La sparsity è in via di crescita come tecnica per migliorare l'efficienza dell'inferenza dei LLM. La combinazione di diverse strategie, tra cui maskers predittivi, caching dei pesi e tecniche top-k statistiche, può ottenere risultati significativi su dispositivi esterni, rendendo possibile lo sviluppo di modelli più grandi senza compromettere la velocità dell'inferenza. Tuttavia, costruire una soluzione completa per l'inferenza sparsa richiede collaborazione aperta tra ricercatori e sviluppatori. Questo articolo fornisce un'analisi dettagliata delle strategie di sparsity, dei loro vantaggi e limiti, e dei passi da fare per raggiungere l'inferenza efficiente su dispositivi esterni.
📁 LLM
AI generated
Accelerando l'inferenza di LLM con sparsity
AI-Radar Takeaway
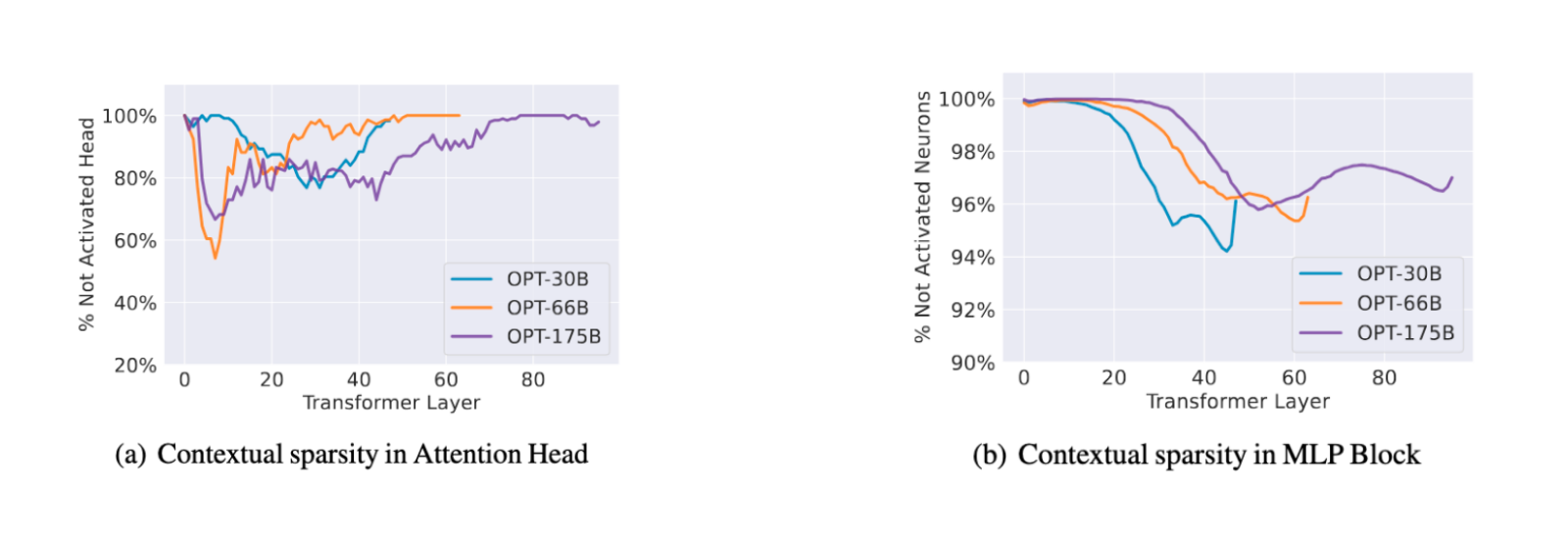
I LLams continuano a crescere in dimensione, e la ricerca di un modo efficiente per il loro inferenza è essenziale. La sparsity rappresenta una soluzione promettente per questo problema, offrendo multipli speed-up necessari per l'inferenza su dispositivi esterni.
Want to dive deeper? Read the full article from the source:
📖 READ THE ORIGINAL ARTICLE💻 Need GPU Cloud Infrastructure?
For running LLM inference, training models, or testing hardware configurations, check out this platform:
🚂
Railway
Cloud Infrastructure
Modern cloud platform with instant deployments. Deploy from GitHub in seconds with automatic HTTPS, databases, and monitoring. Perfect for web apps, APIs, and LLM inference services.
✓ GitHub integration
✓ Auto HTTPS
✓ Simple pricing
🔗 This is an affiliate link - we may earn a commission at no extra cost to you.
💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!