La sparsity è in via di crescita come tecnica per migliorare l'efficienza dell'inferenza dei LLM. La combinazione di diverse strategie, tra cui maskers predittivi, caching dei pesi e tecniche top-k statistiche, può ottenere risultati significativi su dispositivi esterni, rendendo possibile lo sviluppo di modelli più grandi senza compromettere la velocità dell'inferenza. Tuttavia, costruire una soluzione completa per l'inferenza sparsa richiede collaborazione aperta tra ricercatori e sviluppatori. Questo articolo fornisce un'analisi dettagliata delle strategie di sparsity, dei loro vantaggi e limiti, e dei passi da fare per raggiungere l'inferenza efficiente su dispositivi esterni.
📁 LLM
AI generated
Accelerando l'inferenza di LLM con sparsity
Takeaway AI-Radar
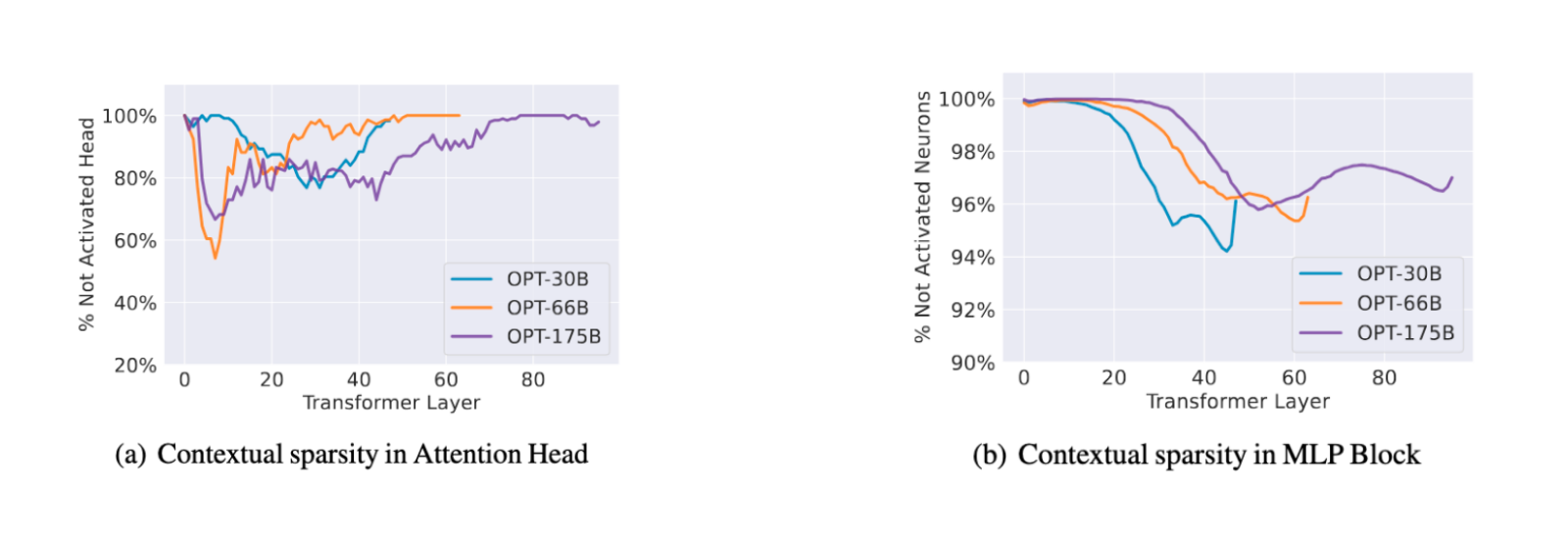
I LLams continuano a crescere in dimensione, e la ricerca di un modo efficiente per il loro inferenza è essenziale. La sparsity rappresenta una soluzione promettente per questo problema, offrendo multipli speed-up necessari per l'inferenza su dispositivi esterni.
Vuoi approfondire? Leggi l'articolo completo dalla fonte:
📖 VAI ALLA FONTE ORIGINALE💻 Hai bisogno di infrastruttura GPU cloud?
Per eseguire inferenza LLM, training di modelli o testare configurazioni hardware, dai un'occhiata a questa piattaforma:
🚂
Railway
Infrastruttura Cloud
Piattaforma cloud moderna con deployment istantanei. Deploy da GitHub in secondi con HTTPS automatico, database e monitoring. Perfetta per web app, API e servizi di inferenza LLM.
✓ Integrazione GitHub
✓ HTTPS automatico
✓ Prezzi semplici
🔗 Questo è un link affiliato - potremmo ricevere una commissione senza costi aggiuntivi per te.
AI-RADAR NEWSLETTER
Resta aggiornato — segnali AI nella tua inbox
Digest giornaliero o settimanale delle notizie AI più importanti. 160+ lettori, zero spam.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!