Anthropic e la gestione della memoria per gli LLM
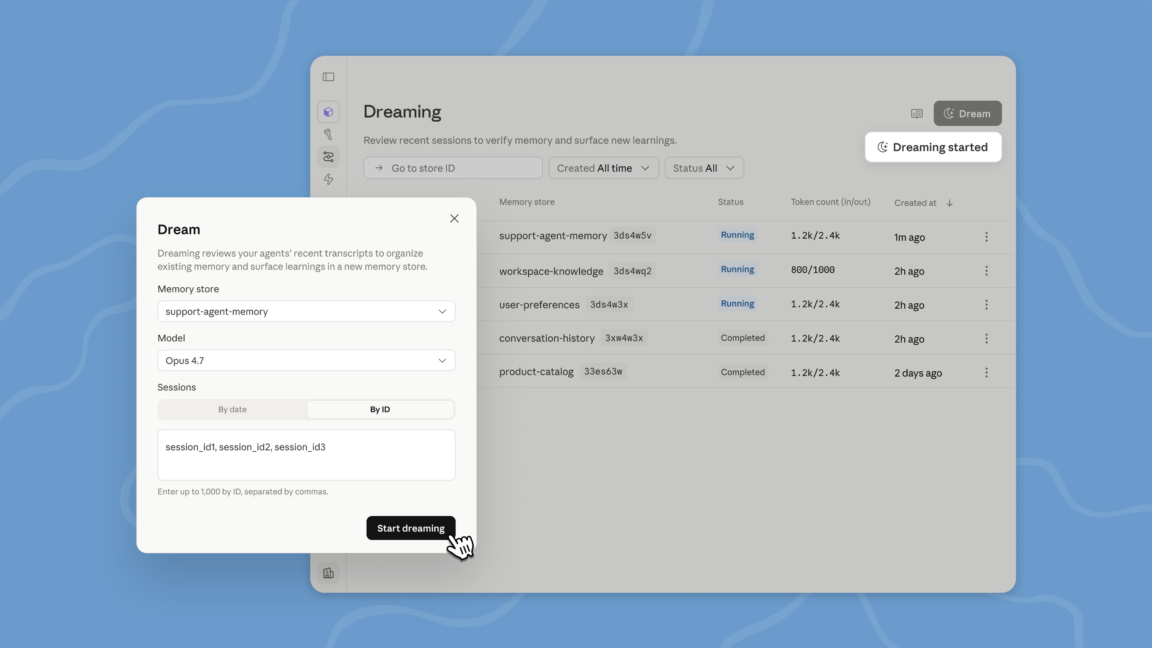
Durante la sua conferenza per sviluppatori 'Code with Claude', Anthropic ha annunciato una nuova funzionalità denominata 'dreaming' per i suoi Claude Managed Agents. Questa innovazione rappresenta un passo significativo verso la risoluzione di una delle sfide più persistenti nell'ambito dei Large Language Models (LLM): la gestione della memoria e la persistenza delle informazioni in compiti complessi e di lunga durata. La funzione 'dreaming' è attualmente disponibile in fase di ricerca (research preview) e limitata agli agenti gestiti sulla piattaforma Claude.
I Managed Agents di Anthropic si configurano come un'alternativa di livello superiore rispetto alla costruzione diretta sull'API Messages. L'azienda li descrive come un 'agent harness pre-costruito e configurabile che opera su infrastruttura gestita'. Sono progettati per scenari in cui più agenti devono collaborare su un compito o un progetto per periodi estesi, che possono variare da diversi minuti a ore, richiedendo una coerenza e una continuità informativa che le architetture LLM tradizionali faticano a mantenere.
Il meccanismo di 'dreaming' e i limiti delle context windows
Il processo di 'dreaming' è concepito come un'attività schedulata, in cui le sessioni recenti e i relativi archivi di memoria vengono esaminati. L'obiettivo è curare e selezionare specifiche 'memorie' che meritano di essere conservate per informare compiti e interazioni future. Questa capacità è fondamentale perché le context windows degli LLM, sebbene in costante espansione, rimangono intrinsecamente limitate. In progetti prolungati, informazioni importanti possono facilmente perdersi o essere 'dimenticate' dal modello, compromettendo la coerenza e l'efficacia delle sue risposte.
Anthropic sottolinea che la gestione della memoria è un aspetto critico per l'affidabilità degli LLM in contesti applicativi reali. Nel campo delle interazioni basate su chat, molti modelli adottano un processo simile chiamato 'compaction'. Questo meccanismo analizza periodicamente le conversazioni lunghe, cercando di rimuovere le informazioni irrilevanti dalla context window e mantenendo solo ciò che è effettivamente importante per la conversazione, il progetto o il compito in corso. La 'dreaming' di Anthropic estende questo concetto a un livello più strutturato e proattivo per i suoi agenti.
Implicazioni per i deployment di LLM e la sovranità dei dati
La capacità di gestire la memoria a lungo termine e di mantenere il contesto è cruciale non solo per l'efficacia degli LLM, ma anche per le decisioni di deployment, specialmente in ambienti self-hosted o air-gapped. Per le organizzazioni che valutano un deployment on-premise, la gestione efficiente della memoria influisce direttamente sui requisiti hardware, come la VRAM delle GPU, e sul Total Cost of Ownership (TCO). Un modello che può 'ricordare' informazioni rilevanti senza doverle ricaricare continuamente nella context window può ridurre il throughput necessario e ottimizzare l'utilizzo delle risorse computazionali.
In contesti dove la sovranità dei dati e la compliance sono prioritarie, la capacità di un LLM di gestire e curare la propria memoria interna diventa un fattore abilitante. Permette di mantenere la pertinenza delle interazioni senza dover esporre l'intero storico delle conversazioni o dei dati sensibili a ogni richiesta, migliorando la sicurezza e la privacy. Per chi valuta framework analitici per deployment on-premise, AI-RADAR offre risorse su /llm-onpremise per approfondire questi trade-off e le implicazioni infrastrutturali.
Prospettive future per gli agenti intelligenti
L'introduzione di funzionalità come 'dreaming' evidenzia la direzione evolutiva degli LLM, che si stanno trasformando da semplici generatori di testo a veri e propri agenti capaci di ragionamento e persistenza. Questa abilità di 'riflettere' sugli eventi passati e di curare una memoria interna apre nuove possibilità per applicazioni aziendali complesse, dalla gestione di progetti alla risoluzione di problemi che richiedono una comprensione profonda e continuativa del contesto.
Tuttavia, l'implementazione e lo scaling di tali sistemi di memoria presentano sfide significative, inclusa la determinazione di cosa sia 'importante' da ricordare e come gestire l'oblio selettivo. La ricerca in questo campo è dinamica e promette di sbloccare ulteriori capacità per gli LLM, rendendoli strumenti sempre più sofisticati e autonomi, capaci di operare efficacemente in scenari che richiedono una comprensione contestuale estesa e una memoria a lungo termine affidabile.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!