Enabling Cluster Launch Control: una nuova frontiera per i sistemi di calcolo
Takeaway AI-Radar
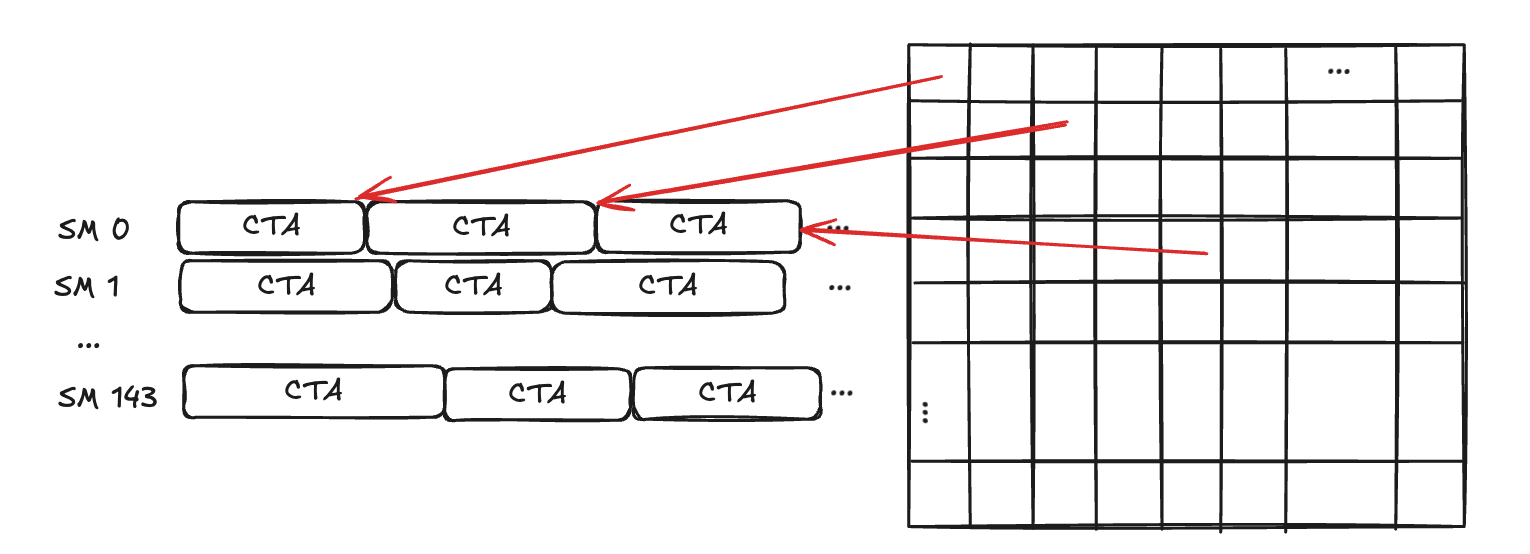
Blackwell introduce Cluster Launch Control (CLC), un'innovazione che permette di ottimizzare la gestione dei thread e dell'utilizzo delle risorse GPU, migliorando le prestazioni dei sistemi di calcolo.
Vuoi approfondire? Leggi l'articolo completo dalla fonte:
📖 VAI ALLA FONTE ORIGINALE💻 Hai bisogno di infrastruttura GPU cloud?
Per eseguire inferenza LLM, training di modelli o testare configurazioni hardware, dai un'occhiata a questa piattaforma:
Cloud GPU flessibile con fatturazione al secondo. Deploy istantaneo con supporto Docker, auto-scaling e ampia selezione di GPU da RTX 4090 a H100.
🔗 Questo è un link affiliato - potremmo ricevere una commissione senza costi aggiuntivi per te.
AI-RADAR NEWSLETTER
Resta aggiornato — segnali AI nella tua inbox
Digest giornaliero o settimanale delle notizie AI più importanti. 160+ lettori, zero spam.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!