
The Great AI Hardware Divide: Is AirLLM the Right Substitute for Quantization? Let’s See the Pros and Cons
An AI-Radar Editorial
The evolution of large language models (LLMs) has reached a critical and somewhat frustrating juncture. The scale of modern frontier models increasingly outstrips the memory capacity of consumer, and even intermediate-level enterprise, hardware. When Meta released the Llama 3.1 405B model, it was hailed as a triumph for open-source AI. Yet, the physics of local deployment quickly grounded the hype: running a 405-billion parameter model at full 16-bit precision requires over 800 gigabytes of Video RAM (VRAM). For the vast majority of developers and enterprises, this effectively locks state-of-the-art AI behind elite data center walls.
This technological divide has catalyzed two primary responses to bypass the "Memory Wall": the mathematical compression of model weights via quantization, and the temporal reconfiguration of inference through layer-wise execution frameworks like AirLLM.
AirLLM’s promise is undeniably seductive: run a 70-billion parameter model on a single 4GB GPU, or a massive 405B model on a mere 8GB of VRAM, with zero loss in mathematical precision. It sounds like magic, but in the realm of systems engineering, there is no such thing as a free lunch.
The central question for AI engineers and infrastructure architects today is whether AirLLM represents a viable substitute for quantization, or if it is a distinct, complementary strategy with its own set of brutal trade-offs. To answer this, we must dissect the mechanics, the mathematics, and the undeniable physics of LLM inference.
--------------------------------------------------------------------------------
Part I: The Physics of LLM Inference
To understand why both quantization and AirLLM exist, we must define the hardware constraints they attempt to circumvent. Neural network inference, specifically during the token generation (decode) phase, is fundamentally memory-bound rather than compute-bound.
During generation, the primary bottleneck is not the speed of the floating-point operations (FLOPs) performed by the GPU's CUDA cores, but rather the rate at which the model's weights can be moved from VRAM into those cores. Modern GPUs like the RTX 4090 possess massive theoretical compute power, yet their memory bandwidth—typically around 1,000 GB/s (1 TB/s)—is insufficient to keep the compute cores fully saturated.
When a model exceeds the available VRAM, the system must fetch data from system RAM or, worse, from a solid-state drive (SSD).
Graphic: The Bandwidth Waterfall
[ Compute Cores ] <── 19,000 GB/s ──> [ L1 Cache / SMEM ]
^
│ ~12,000 GB/s
v
[ L2 Cache ]
^
│ ~1,000 GB/s (The VRAM Bottleneck)
v
[ GPU VRAM (HBM/GDDR) ]
^
│ ~32 GB/s (PCIe 4.0 x16 / PCIe 5.0)
v
[ System RAM (DDR5) ]
^
│ ~7 to 14 GB/s (The Storage Bottleneck)
v
[ NVMe SSD ]
Visualizing the drastic drop in bandwidth as data moves further away from the compute cores.
If a 70B model requires 140GB of storage at 16-bit precision, it simply cannot fit into a 24GB or 80GB GPU. To generate a single token, the entire model must be read into the compute cores. Therefore, the AI community had to find ways to shrink the model (Quantization) or change how it is loaded (AirLLM).
--------------------------------------------------------------------------------
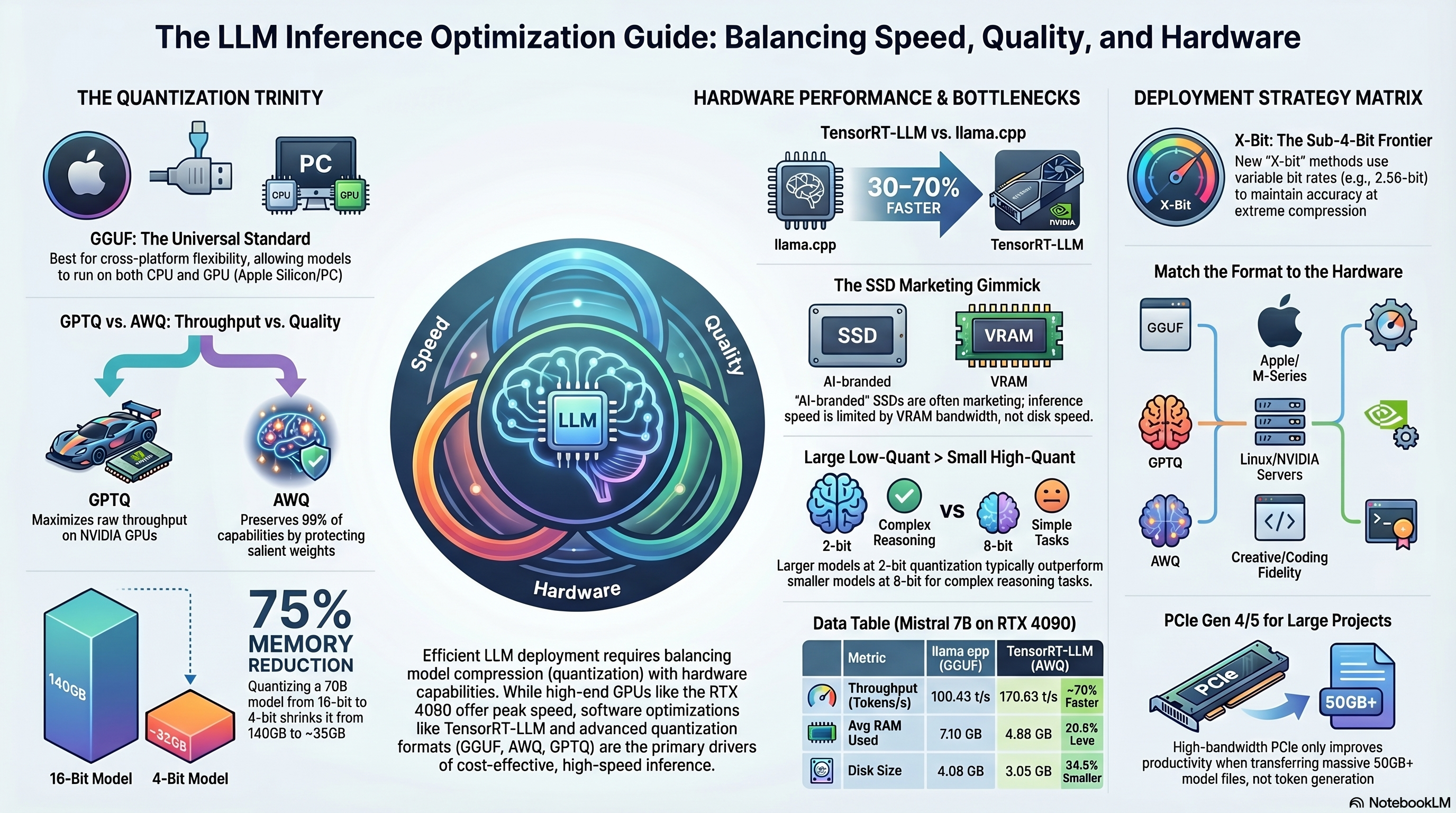
Part II: The Reigning Champion – Weight Quantization
Quantization has long been the industry-standard solution for the memory crisis. It is the process of mapping high-precision floating-point values to lower-precision discrete sets, such as 8-bit, 4-bit, or even 2-bit integers.
By reducing the precision of a model from 16-bit to 4-bit, its memory footprint is slashed by approximately 75%, allowing a massive 70B model to fit within roughly 35GB to 40GB of VRAM. The fundamental formula for symmetric quantization takes the original floating-point weight, divides it by a scale factor, adds a zero-point offset, and rounds it to the nearest integer.
The Major Quantization Formats
Not all quantization is created equal. The ecosystem is currently dominated by a few key methodologies, each optimized for specific hardware and use cases:
| Quantization Format | Core Methodology | Best Use Case | Primary Frameworks |
|---|---|---|---|
| GGUF | Mixed-precision integer quantization (block-wise). | Cross-platform (CPU, Apple M-Series, mixed GPU/CPU). | llama.cpp, Ollama, LM Studio. |
| GPTQ | Calibration-based error compensation using Hessian matrices. | High-throughput multi-user GPU servers. | vLLM, AutoGPTQ, TGI. |
| AWQ | Activation-Aware Weight Quantization. Protects salient weights by scaling them based on activation data. | Production deployments needing strict accuracy preservation at 4-bit. | vLLM, AutoAWQ. |
| EXL2 | Variable bit-rate quantization (e.g., 4.65 bits per weight) allowing per-layer allocation. | Maximum quality-per-bit for single-user GPU environments. | ExLlamaV2, Text-Generation-WebUI. |
Pros of Quantization:
Inference Efficiency: By shrinking the weights, less data is streamed across the VRAM bottleneck, directly leading to a 2.4x to 3x speedup in single-stream token generation compared to 16-bit baselines.Hardware Viability: It allows models to reside entirely within VRAM, facilitating interactive token speeds (often 50+ tokens per second on consumer hardware).Maturity: Formats like GGUF allow for "compile once, run everywhere" portability across operating systems and architectures.
Cons of Quantization:
Information Loss and Degradation: The compression is lossy. While 8-bit quantization typically sees less than a 1% quality drop, 4-bit quantization drops 2-5% of reasoning fidelity.Sub-4-Bit Collapse: Pushing below 4 bits (e.g., to 2-bit or 1-bit) often causes catastrophic degradation in tasks requiring complex logic, math, or coding unless specialized dynamic algorithms are used.The LLaMA-3-70B Anomaly: Certain architectures are uniquely hostile to quantization. For example, researchers discovered that the LLaMA-3-70B and 3.1-70B models have massive weight outliers (magnitudes exceeding 90) in their initial layers. Standard per-channel W8A8 quantization devastates their accuracy. Fixing this requires specialized mixed-grouping or bi-smoothing strategies.Multilingual Penalties: Aggressive quantization severely hurts low-resource languages, with reasoning in non-English tongues dropping by up to 20% in 4-bit formats.
--------------------------------------------------------------------------------
Part III: The Challenger – AirLLM and Layer-Wise Inference
If quantization is the act of compressing the cargo to fit the vehicle, AirLLM is the act of dismantling the vehicle, moving it piece by piece, and reassembling it at the destination.
AirLLM bypasses the VRAM capacity limitation entirely using a technique called layer-wise inference. Transformer models are sequential stacks of layers. Rather than loading the entire 140GB model into the GPU at once, AirLLM loads the model one single layer at a time from system storage.
Graphic: The AirLLM Execution Cycle
START TOKEN GENERATION
│
v
┌─────────────────────────────────┐
│ 1. LOAD: Read Layer N from SSD │
│ over PCIe to GPU VRAM │
└───────────────┬─────────────────┘
│
┌───────────────v─────────────────┐
│ 2. COMPUTE: GPU executes Layer N│
│ using CUDA cores │
└───────────────┬─────────────────┘
│
┌───────────────v─────────────────┐
│ 3. FREE: Purge Layer N from VRAM│
│ to make space │
└───────────────┬─────────────────┘
│
[Repeat for all 80 layers]
│
[Output 1 Single Token]
│
[Repeat Cycle]
The mechanical flow of AirLLM's temporal loading.
Because the GPU is only ever holding a fraction of the model at any given millisecond, a massive 70B model shard fits comfortably inside a 4GB frame buffer.
Pros of AirLLM:
Unprecedented Democratic Access: AirLLM allows developers with 8GB laptops to experiment with the 405-billion parameter Llama 3.1, completely redefining what is possible on consumer hardware.Zero-Loss Fidelity Validation: AirLLM can run the model in its native FP16 precision without any mathematical compression. This allows data scientists to establish a ground-truth benchmark for a model's true capabilities before they decide to rent expensive cloud clusters or invest in destructive quantization.Absolute Privacy: For healthcare, legal, or defense applications, sensitive data can be processed entirely offline on-premises without relying on closed-source APIs or high-end servers.
--------------------------------------------------------------------------------
Part IV: The Unavoidable Physics of Latency
If AirLLM's core innovation is elegant, its consequence is brutal. By moving the model layer-by-layer, AirLLM introduces a new primary constraint: Disk I/O.
You are no longer bound by the GPU's memory bandwidth (~1,000 GB/s), but by the speed of your storage drive. Even a top-tier PCIe Gen 4 NVMe SSD peaks at about 7.5 GB/s, and a bleeding-edge Gen 5 drive hits around 14 GB/s. The math for token latency in AirLLM is inescapable:
Token Latency = Model Size (GB) / Disk Bandwidth (GB/s)
In practice, for a 70B model running off a Gen4 NVMe SSD, AirLLM crawls at roughly 0.175 tokens per second. For the 405B model, speeds plummet to 0.03 tokens per second. To put that in perspective, generating a standard 2,000-token response would literally take hours.
As one engineering critic succinctly put it: "You’re not ‘running 70B on 4GB.’ You’re waiting for 70B on 4GB."
Furthermore, the continuous, high-volume reading required by AirLLM will quickly push NVMe drives to their thermal limits (around 80°C), triggering thermal throttling. Once throttled, a Gen 5 drive's performance drops to Gen 3 levels, doubling latency mid-generation.
Table: Performance Realities – Quantization vs. AirLLM
| Metric | 70B Native Quantization (vLLM/llama.cpp) | 70B AirLLM (Layer-Wise) |
|---|---|---|
| Hardware Required | 2x RTX 3090 / 1x RTX 6000 Ada | 1x RTX 3050 (4GB) + Fast NVMe |
| Token Generation Speed | ~15 to 45 Tokens / Second | ~0.05 to 0.175 Tokens / Second |
| Time for 500 Tokens | ~15 Seconds | ~1.5 to 3 Hours |
| Batching / Concurrency | Highly Scalable (Hundreds of users) | Strictly Single User (Sequential) |
| Primary Bottleneck | VRAM Bandwidth | PCIe / Disk I/O Throughput |
--------------------------------------------------------------------------------
Part V: The Verdict – Substitute or Complement?
Is AirLLM the right substitute for quantization? The definitive answer is no.
Technical analysis reveals that AirLLM is not a substitute for quantization; it is a distinct infrastructure paradigm that actually requires quantization to be functional in any practical sense.
AirLLM explicitly relies on a compression='4bit' configuration flag. This is not a rebranding of layer-swapping; it is the integration of standard block-wise weight quantization. Why? Because moving 140GB of data across the PCIe bus for every single token is untenable. By applying 4-bit quantization, the data payload drops to 35GB, providing a mandatory 3x speed boost to the disk-loading process. You cannot escape quantization; AirLLM depends on it to turn "days per token" into "minutes per token."
When to use Quantization:
Quantization is the deployment phase tool. If you need to build a responsive, real-time application—such as a coding assistant, a chatbot, or a continuous-batching API server—quantization frameworks like GGUF (for CPUs/Macs) or AWQ/GPTQ (for GPUs) are the only viable paths. Quantization democratizes speed and interactivity.
When to use AirLLM:
AirLLM is the discovery and validation phase tool. It excels when the goal is access, not speed. Use AirLLM if:
You are performing offline batch processing or document extraction over the weekend where latency is irrelevant.You want to validate if a massive 405B model possesses the reasoning capability required for your specific enterprise data before you authorize a $30,000 hardware purchase.You are an academic or researcher investigating the latent space of models that vastly exceed your computing budget.
--------------------------------------------------------------------------------
Part VI: The Future of Resource-Constrained Inference
The stark limitations of AirLLM have spurred the open-source community to find middle-ground solutions that bridge the gap between harsh quantization and agonizing disk latency.
1. Pipelined-Ring Parallelism (Prima.cpp) Systems like prima.cpp are emerging to tackle the "prefetch-release conflict" inherent in OS-level memory mapping. By treating a home network of heterogeneous devices (a laptop, a smartphone, a PC) as a distributed ring, prima.cpp can run 30-70B models by overlapping disk I/O with compute and communication. Utilizing predictive prefetching, it achieves 674 ms/token for a 70B model on consumer hardware, bridging the gap between AirLLM's extreme slowness and standard inference.
2. Unified Memory Architectures Apple's M-series chips and AMD's Strix Halo processors are changing the paradigm. By sharing memory between the CPU and GPU, massive models (quantized to GGUF or MLX formats) can be run without navigating the PCIe bottleneck. An M3 Ultra with 192GB of unified RAM can achieve practical inference speeds on a 120B model without resorting to disk-swapping.
3. Advanced Sub-4-Bit and KV Cache Quantization Innovations like TurboQuant and picoLLM (X-bit quantization) are pushing the boundaries of what is possible. TurboQuant specifically targets the KV Cache—the memory overhead that grows as context length increases—compressing it efficiently so that larger context windows fit in smaller VRAM. Meanwhile, X-bit quantization allows models to average 2.56 bits per weight by allocating more bits to salient outlier weights and fewer to redundant ones, retaining near FP16 accuracy at extreme compression ratios.
Final Thoughts for the AI Engineer
In the 2026 AI landscape, hardware economics dictate software strategy. Quantization remains the undisputed king of production AI, fundamentally altering the economics of token generation by maximizing performance-per-dollar and throughput-per-watt.
AirLLM, conversely, is a brilliant exploit of the transformer architecture's sequential nature. It serves as a stark reminder of the physical realities of von Neumann architectures and the PCIe bus. It is not a replacement for quantization, but a specialized magnifying glass—a way for anyone, regardless of budget, to peer into the minds of the largest artificial intelligences humanity has yet created.
Choose quantization when you need the model to talk to you. Choose AirLLM when you have the patience to let the model think.











💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!