
Il Grande Divario Hardware dell'IA: AirLLM è il Sostituto Giusto per la Quantization? Vediamone i Pro e i Contro
Un Editoriale di AI-Radar
L'evoluzione dei modelli linguistici di grandi dimensioni (LLM) ha raggiunto un punto critico e in qualche modo frustrante. La scala dei moderni modelli all'avanguardia supera sempre più la capacità di memoria dell'hardware consumer e persino di quello aziendale di livello intermedio. Quando Meta ha rilasciato il modello Llama 3.1 405B, è stato acclamato come un trionfo per l'IA open-source. Tuttavia, la fisica della distribuzione locale ha rapidamente ridimensionato l'entusiasmo: l'esecuzione di un modello da 405 miliardi di parametri a piena precisione a 16 bit richiede oltre 800 gigabyte di Video RAM (VRAM). Per la stragrande maggioranza degli sviluppatori e delle aziende, questo blocca di fatto l'IA all'avanguardia dietro le mura dei data center d'élite.
Questo divario tecnicico ha catalizzato due risposte principali per aggirare il "Muro della Memoria": la compressione matematica dei pesi del modello tramite quantization e la riconfigurazione temporale dell'inference attraverso framework di esecuzione a strati come AirLLM.
La promessa di AirLLM è innegabilmente seducente: eseguire un modello da 70 miliardi di parametri su una singola GPU da 4GB, o un enorme modello da 405B su soli 8GB di VRAM, con zero perdite di precisione matematica. Sembra magia, ma nel campo dell'ingegneria dei sistemi, non esiste un pranzo gratuito.
La questione centrale per gli ingegneri dell'IA e gli architetti di infrastrutture oggi è se AirLLM rappresenti un sostituto valido per la quantization, o se sia una strategia distinta e complementare con i suoi brutali compromessi. Per rispondere a ciò, dobbiamo analizzare la meccanica, la matematica e l'innegabile fisica dell'inference degli LLM.
--------------------------------------------------------------------------------
Parte I: La Fisica dell'Inference degli LLM
Per capire perché esistono sia la quantization che AirLLM, dobbiamo definire i vincoli hardware che cercano di aggirare. L'inference delle reti neurali, in particolare durante la fase di generazione dei token (decodifica), è fondamentalmente limitata dalla memoria (memory-bound) piuttosto che dalla capacità di calcolo (compute-bound).
Durante la generazione, il collo di bottiglia principale non è la velocità delle operazioni in virgola mobile (FLOPs) eseguite dai core CUDA della GPU, ma piuttosto la velocità con cui i pesi del modello possono essere spostati dalla VRAM a questi core. Le GPU moderne come la RTX 4090 possiedono un'enorme potenza di calcolo teorica, eppure la loro larghezza di banda della memoria — tipicamente intorno ai 1.000 GB/s (1 TB/s) — è insufficiente per mantenere i core di calcolo completamente saturi.
Quando un modello supera la VRAM disponibile, il sistema deve recuperare i dati dalla RAM di sistema o, peggio, da un'unità a stato solido (SSD).
Grafico: La Cascata della Larghezza di Banda
[ Compute Cores ] <── 19,000 GB/s ──> [ L1 Cache / SMEM ]
^
│ ~12,000 GB/s
v
[ L2 Cache ]
^
│ ~1,000 GB/s (Il Collo di Bottiglia della VRAM)
v
[ GPU VRAM (HBM/GDDR) ]
^
│ ~32 GB/s (PCIe 4.0 x16 / PCIe 5.0)
v
[ System RAM (DDR5) ]
^
│ ~7 to 14 GB/s (Il Collo di Bottiglia dello Storage)
v
[ NVMe SSD ]
Visualizzazione del drastico calo della larghezza di banda man mano che i dati si allontanano dai core di calcolo.
Se un modello da 70B richiede 140GB di spazio di archiviazione a precisione a 16 bit, semplicemente non può essere caricato in una GPU da 24GB o 80GB. Per generare un singolo token, l'intero modello deve essere letto nei core di calcolo. Pertanto, la comunità dell'IA ha dovuto trovare modi per ridurre le dimensioni del modello (Quantization) o modificare il modo in cui viene caricato (AirLLM).
--------------------------------------------------------------------------------
Parte II: Il Campione in Carica – La Quantization dei Pesi
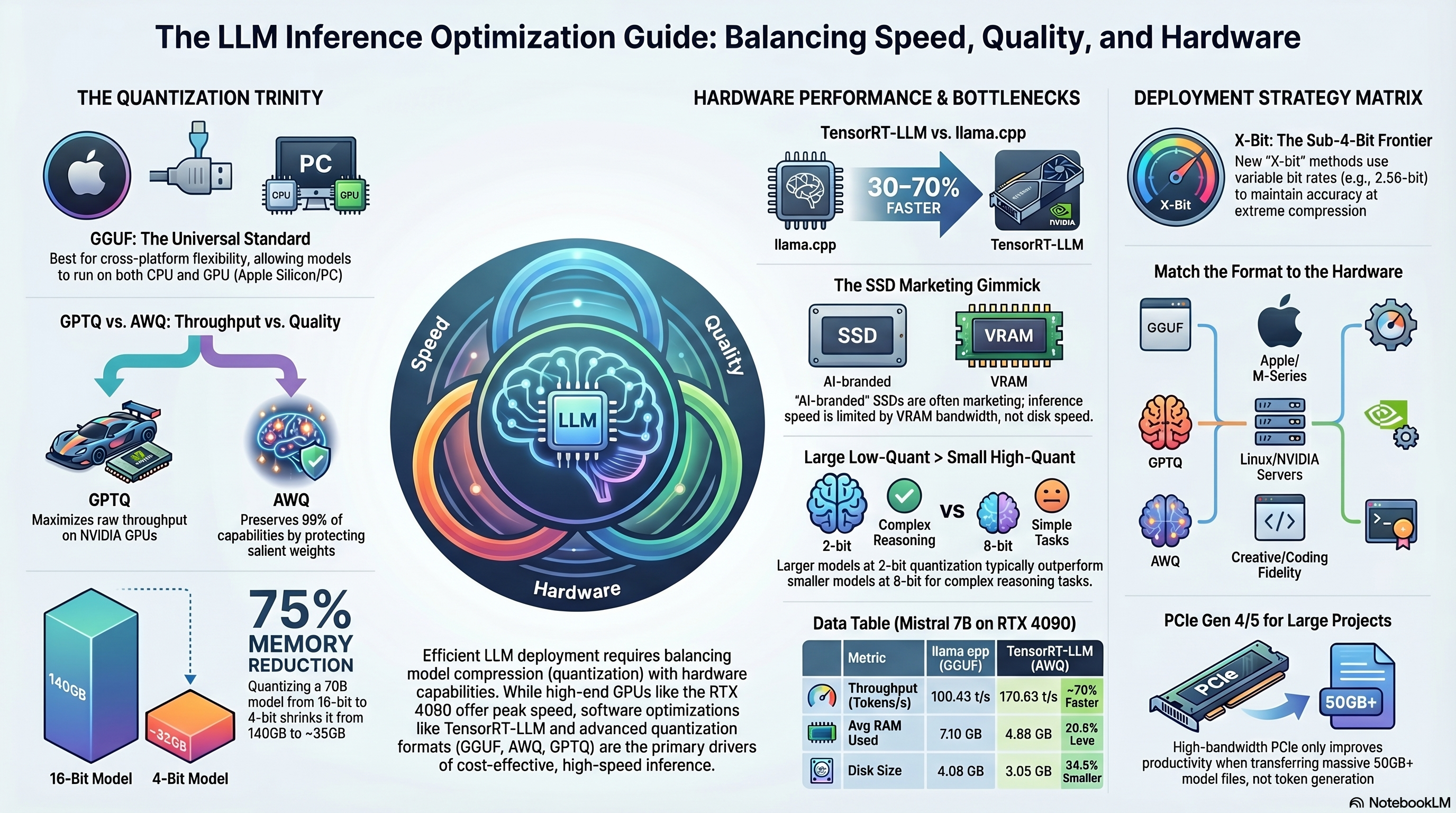
La quantization è da tempo la soluzione standard del settore per la crisi della memoria. È il processo di mappatura di valori in virgola mobile ad alta precisione a set discreti a precisione inferiore, come interi a 8 bit, 4 bit o persino 2 bit.
Riducendo la precisione di un modello da 16 bit a 4 bit, l'ingombro di memoria viene ridotto di circa il 75%, consentendo a un enorme modello da 70B di rientrare in circa 35GB-40GB di VRAM. La formula fondamentale per la quantization simmetrica prende il peso originale in virgola mobile, lo divide per un fattore di scala, aggiunge un offset di punto zero e lo arrotonda all'intero più vicino.
I Principali Formati di Quantization
Non tutta la quantization è uguale. L'ecosistema è attualmente dominato da alcune metodologie chiave, ciascuna ottimizzata per hardware e casi d'uso specifici:
| Formato di Quantization | Metodologia Principale | Miglior Caso d'Uso | Framework Principali |
|---|---|---|---|
| GGUF | Quantization intera a precisione mista (a blocchi). | Multipiattaforma (CPU, Apple M-Series, GPU/CPU miste). | llama.cpp, Ollama, LM Studio. |
| GPTQ | Compensazione degli errori basata sulla calibrazione tramite matrici di Hessian. | Server GPU multi-utente ad alta produttività. | vLLM, AutoGPTQ, TGI. |
| AWQ | Quantization dei pesi sensibile all'attivazione (Activation-Aware Weight Quantization). Protegge i pesi salienti scalandoli in base ai dati di attivazione. | Distribuzioni in produzione che richiedono una rigorosa conservazione dell'accuratezza a 4 bit. | vLLM, AutoAWQ. |
| EXL2 | Quantization a bit-rate variabile (es. 4,65 bit per peso) che consente l'allocazione per strato. | Massima qualità per bit per ambienti GPU a utente singolo. | ExLlamaV2, Text-Generation-WebUI. |
Pro della Quantization:
Efficienza dell'Inference: Riducendo i pesi, meno dati vengono trasmessi attraverso il collo di bottiglia della VRAM, portando direttamente a un aumento della velocità da 2,4x a 3x nella generazione di token a flusso singolo rispetto ai modelli base a 16 bit.Fattibilità Hardware: Permette ai modelli di risiedere interamente all'interno della VRAM, facilitando velocità di token interattive (spesso oltre 50 token al secondo su hardware consumer).Maturità: Formati come GGUF consentono la portabilità "compila una volta, esegui ovunque" attraverso sistemi operativi e architetture.
Contro della Quantization:
Perdita e Degrado delle Informazioni: La compressione è con perdita di dati. Mentre la quantization a 8 bit di solito comporta una diminuzione della qualità inferiore all'1%, la quantization a 4 bit riduce la fedeltà del ragionamento del 2-5%.Collasso Sotto i 4 Bit: Scendere sotto i 4 bit (ad esempio, a 2 bit o 1 bit) spesso causa un degrado catastrofico in compiti che richiedono logica complessa, matematica o codifica, a meno che non vengano utilizzati algoritmi dinamici specializzati.L'Anomalia LLaMA-3-70B: Alcune architetture sono particolarmente ostili alla quantization. Ad esempio, i ricercatori hanno scoperto che i modelli LLaMA-3-70B e 3.1-70B presentano enormi outlier di peso (magnitudini superiori a 90) nei loro strati iniziali. La quantization standard W8A8 per canale ne devasta l'accuratezza. La risoluzione di questo problema richiede strategie specializzate di raggruppamento misto (mixed-grouping) o bi-smoothing.Penalità Multilingue: La quantization aggressiva danneggia gravemente le lingue con meno risorse, con il ragionamento in lingue non inglesi che diminuisce fino al 20% nei formati a 4 bit.
--------------------------------------------------------------------------------
Parte III: Lo Sfidante – AirLLM e l'Inference a Strati
Se la quantization è l'atto di comprimere il carico per farlo entrare nel veicolo, AirLLM è l'atto di smontare il veicolo, spostarlo pezzo per pezzo e riassemblarlo a destinazione.
AirLLM aggira completamente la limitazione della capacità della VRAM utilizzando una tecnica chiamata inference a strati (layer-wise inference). I modelli Transformer sono pile sequenziali di strati. Invece di caricare l'intero modello da 140GB nella GPU in una volta sola, AirLLM carica il modello un singolo strato alla volta dalla memoria di sistema.
Grafico: Il Ciclo di Esecuzione di AirLLM
INIZIO GENERAZIONE TOKEN
^
v
┌─────────────────────────────────┐
│ 1. CARICA: Leggi lo Strato N da SSD │
│ via PCIe alla VRAM della GPU │
└───────────────┬─────────────────┘
│
┌───────────────v─────────────────┐
│ 2. CALCOLA: La GPU esegue lo Strato N│
│ usando i core CUDA │
└───────────────┬─────────────────┘
│
┌───────────────v─────────────────┐
│ 3. LIBERA: Elimina lo Strato N dalla VRAM│
│ per fare spazio │
└───────────────┬─────────────────┘
│
[Ripeti per tutti gli 80 strati]
│
[Output 1 Singolo Token]
│
[Ripeti Ciclo]
Il flusso meccanico del caricamento temporale di AirLLM.
Poiché la GPU contiene solo una frazione del modello in un dato millisecondo, un enorme frammento di modello da 70B si adatta comodamente all'interno di un buffer di frame da 4GB.
Pro di AirLLM:
Accesso Democratico Senza Precedenti: AirLLM consente agli sviluppatori con laptop da 8GB di sperimentare con il modello Llama 3.1 da 405 miliardi di parametri, ridefinendo completamente ciò che è possibile su hardware consumer.Validazione della Fedeltà a Zero Perdite: AirLLM può eseguire il modello nella sua precisione nativa FP16 senza alcuna compressione matematica. Ciò consente agli scienziati dei dati di stabilire un benchmark di riferimento per le vere capacità di un modello prima di decidere di noleggiare costosi cluster cloud o investire in una quantization distruttiva.Privacy Assoluta: Per applicazioni sanitarie, legali o di difesa, i dati sensibili possono essere elaborati interamente offline on-premises senza fare affidamento su API closed-source o server di fascia alta.
--------------------------------------------------------------------------------
Parte IV: L'Ineludibile Fisica della Latenza
Se l'innovazione centrale di AirLLM è elegante, la sua conseguenza è brutale. Spostando il modello strato per strato, AirLLM introduce un nuovo vincolo primario: l'I/O su disco.
Non si è più vincolati dalla larghezza di banda della memoria della GPU (~1.000 GB/s), ma dalla velocità dell'unità di archiviazione. Anche un SSD NVMe PCIe Gen 4 di fascia alta raggiunge circa 7,5 GB/s, e un'unità Gen 5 all'avanguardia arriva a circa 14 GB/s. La matematica per la latenza dei token in AirLLM è ineludibile:
Latenza Token = Dimensione Modello (GB) / Larghezza di Banda del Disco (GB/s)
In pratica, per un modello da 70B in esecuzione su un SSD NVMe Gen4, AirLLM procede a circa 0,175 token al secondo. Per il modello da 405B, le velocità crollano a 0,03 token al secondo. Per mettere le cose in prospettiva, generare una risposta standard di 2.000 token richiederebbe letteralmente ore.
Come ha sinteticamente affermato un critico ingegneristico: "Non stai 'eseguendo 70B su 4GB'. Stai aspettando 70B su 4GB."
Inoltre, la lettura continua e ad alto volume richiesta da AirLLM spingerà rapidamente le unità NVMe ai loro limiti termici (circa 80°C), innescando il throttling termico. Una volta sottoposta a throttling, le prestazioni di un'unità Gen 5 scendono ai livelli di Gen 3, raddoppiando la latenza a metà generazione.
Tabella: Realtà delle Prestazioni – Quantization vs. AirLLM
| Metrica | Quantization Nativa 70B (vLLM/llama.cpp) | AirLLM 70B (a Strati) |
|---|---|---|
| Hardware Richiesto | 2x RTX 3090 / 1x RTX 6000 Ada | 1x RTX 3050 (4GB) + NVMe Veloce |
| Velocità Generazione Token | ~15 a 45 Token / Secondo | ~0,05 a 0,175 Token / Secondo |
| Tempo per 500 Token | ~15 Secondi | ~1,5 a 3 Ore |
| Batching / Concorrenza | Altamente Scalabile (Centinaia di utenti) | Strettamente Utente Singolo (Sequenziale) |
| Collo di Bottiglia Primario | Larghezza di Banda VRAM | Throughput PCIe / I/O su Disco |
--------------------------------------------------------------------------------
Parte V: Il Verdetto – Sostituto o Complemento?
AirLLM è il sostituto giusto per la quantization? La risposta definitiva è no.
L'analisi tecnica rivela che AirLLM non è un sostituto della quantization; è un paradigma infrastrutturale distinto che richiede effettivamente la quantization per essere funzionale in qualsiasi senso pratico.
AirLLM si basa esplicitamente su un flag di configurazione compression='4bit'. Questo non è un rebranding dello scambio di strati; è l'integrazione della quantization standard dei pesi a blocchi. Perché? Perché spostare 140GB di dati attraverso il bus PCIe per ogni singolo token è insostenibile. Applicando la quantization a 4 bit, il carico di dati scende a 35GB, fornendo un aumento di velocità obbligatorio di 3x al processo di caricamento del disco. Non si può sfuggire alla quantization; AirLLM ne dipende per trasformare "giorni per token" in "minuti per token".
Quando usare la Quantization:
La quantization è lo strumento per la fase di distribuzione. Se è necessario costruire un'applicazione reattiva e in tempo reale — come un assistente di codifica, un chatbot o un server API con batching continuo — i framework di quantization come GGUF (per CPU/Mac) o AWQ/GPTQ (per GPU) sono le uniche strade percorribili. La quantization democratizza velocità e interattività.
Quando usare AirLLM:
AirLLM è lo strumento per la fase di scoperta e validazione. Eccelle quando l'obiettivo è l'accesso, non la velocità. Usa AirLLM se:
Stai eseguendo elaborazioni batch offline o estrazione di documenti durante il fine settimana, dove la latenza è irrilevante.Vuoi verificare se un enorme modello da 405B possiede la capacità di ragionamento richiesta per i tuoi dati aziendali specifici prima di autorizzare un acquisto hardware da 30.000 dollari.Sei un accademico o un ricercatore che indaga lo spazio latente di modelli che superano di gran lunga il tuo budget di calcolo.
--------------------------------------------------------------------------------
Parte VI: Il Futuro dell'Inference con Risorse Limitate
Le nette limitazioni di AirLLM hanno spinto la comunità open-source a trovare soluzioni intermedie che colmino il divario tra una quantization aggressiva











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!