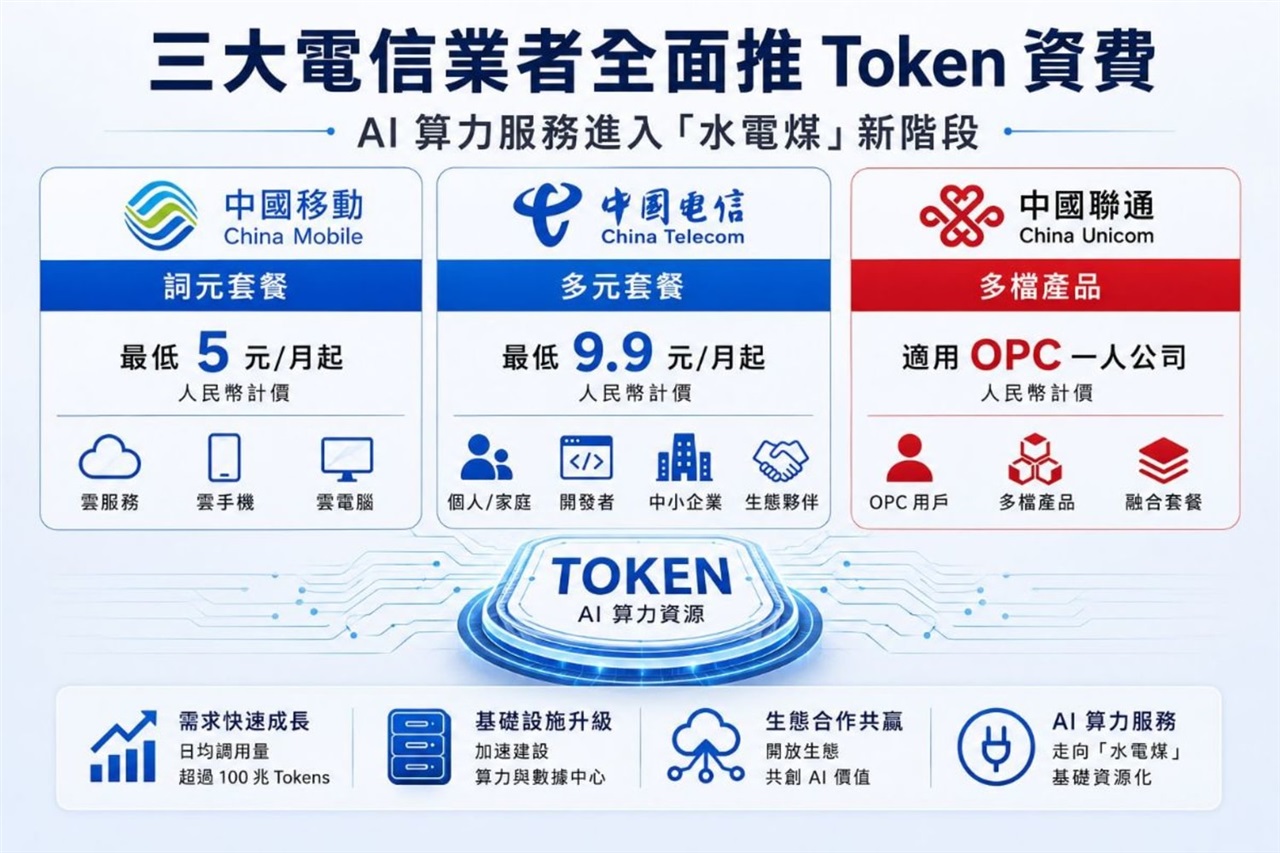
Chinese Telcos and AI Monetization: Inference Goes Mass-Market
The artificial intelligence landscape continues to evolve rapidly, with significant implications for global infrastructure and business models. Recent developments in China indicate a clear direction: major telecommunications companies are introducing token-based billing systems for AI services, signaling a transition of AI Inference towards a mass market. This move not only reflects the growing adoption of AI but also poses new challenges and opportunities for companies evaluating deployment strategies.
The decision by Chinese telcos to adopt a token-based billing model for AI services highlights a maturing market. This approach, common in the LLM sector, allows for granular monetization of the computational resources required for Inference. For enterprises, this means greater transparency on operational costs, but also the need to optimize model usage to control spending. The transition to mass-market AI Inference implies that an increasing number of applications and services will integrate AI capabilities, making infrastructure efficiency and scalability a critical factor.
Token Monetization and Infrastructure Implications
The token-based billing model, while offering flexibility, shifts focus to the efficient management of Inference workloads. For organizations considering a self-hosted LLM deployment, this scenario underscores the importance of a careful TCO analysis. The choice between a cloud infrastructure, with its variable operational costs, and an on-premise deployment, which requires a more substantial initial investment (CapEx) but offers greater control over long-term costs and data sovereignty, becomes crucial.
Telcos, with their vast network infrastructures, are uniquely positioned to offer AI Inference services, potentially even at the edge. This can reduce latency and improve privacy, fundamental aspects for sensitive applications. However, for companies wishing to maintain full control over their data and models, an on-premise or air-gapped architecture remains the preferred option. The ability to internally manage the entire Inference pipeline, from hardware selection (such as GPUs with adequate VRAM) to software optimization, allows for achieving performance and security levels difficult to replicate in external environments.
Mass-Scale AI Inference: Challenges and Opportunities
The expansion of AI Inference to a mass market brings a series of technical challenges. The demand for computational capacity to run LLMs and other AI models in real-time is constantly growing. This requires not only powerful hardware but also optimized software to maximize throughput and minimize latency. Companies must carefully evaluate their needs in terms of batch size, memory requirements (VRAM), and token processing speed to choose the most suitable infrastructure.
The opportunity lies in the ability to integrate AI into a wide range of products and services, creating new value. However, the scalability of these deployments requires meticulous planning. For those opting for self-hosted solutions, managing GPU clusters, configuring efficient serving frameworks, and implementing quantization strategies to reduce memory requirements are essential steps. The ability to manage these aspects internally can translate into a significant competitive advantage, especially in sectors with stringent compliance requirements or where data sovereignty is a priority.
Future Prospects and Deployment Considerations
The trend towards mass-market AI Inference, as demonstrated by the initiatives of Chinese telcos, marks a turning point in the adoption of artificial intelligence. Organizations of all sizes will increasingly be called upon to integrate AI into their core processes. The choice of deployment architecture – whether cloud, hybrid, or entirely on-premise – will become a strategic decision that will directly influence TCO, data security, and operational flexibility.
For companies evaluating on-premise deployment options for their LLM workloads, it is crucial to consider not only the initial hardware costs but also long-term operational costs, energy consumption, and management complexity. AI-RADAR offers analytical frameworks on /llm-onpremise to help evaluate these trade-offs, providing neutral guidance on the implications of each choice. The future of AI is intrinsically linked to the ability of companies to build and manage resilient, efficient, and secure infrastructures capable of supporting large-scale Inference.










💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!