Le telco cinesi e la monetizzazione dell'AI: l'inference diventa di massa
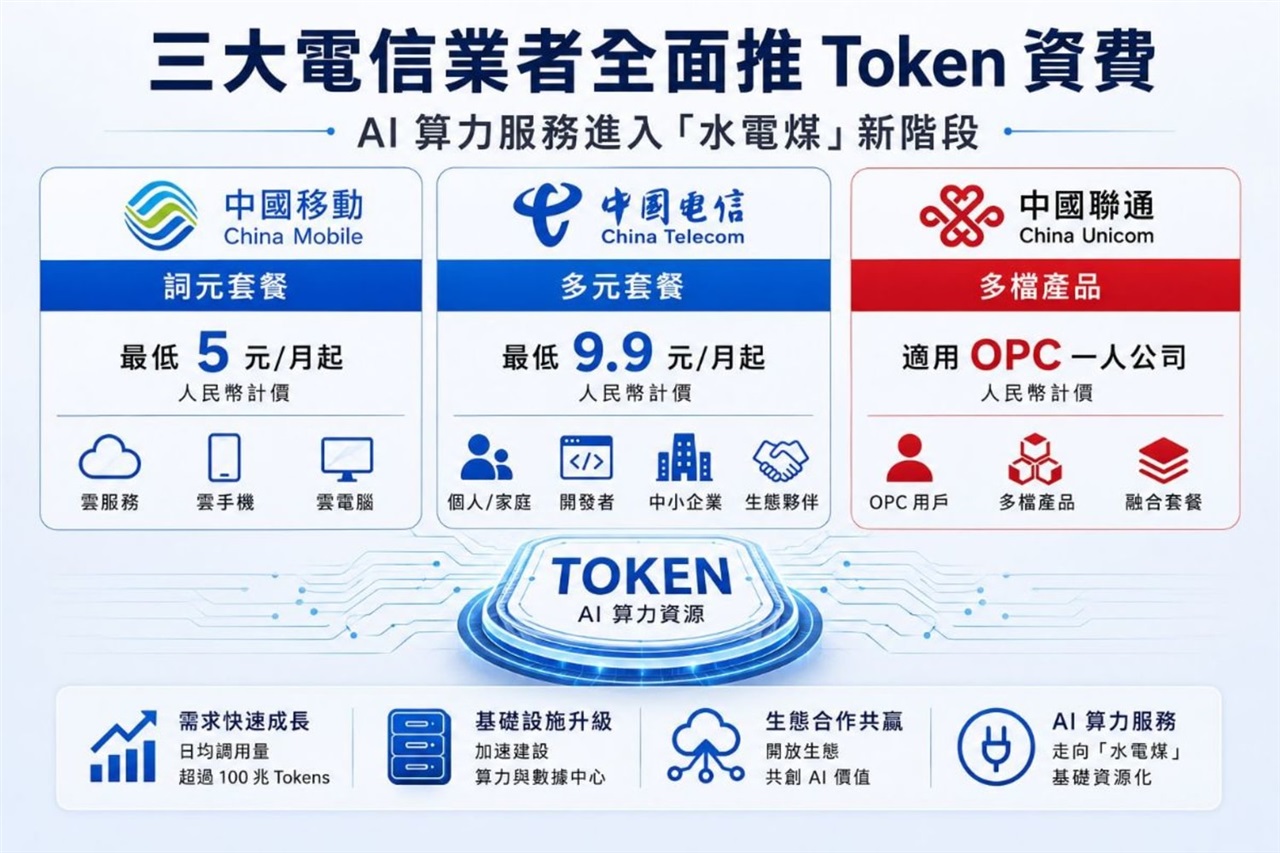
Il panorama dell'intelligenza artificiale continua a evolversi rapidamente, con implicazioni significative per le infrastrutture e i modelli di business globali. Recenti sviluppi in Cina indicano una chiara direzione: le principali compagnie di telecomunicazioni stanno introducendo sistemi di fatturazione basati su token per i servizi AI, segnalando una transizione dell'inference AI verso un mercato di massa. Questa mossa non solo riflette la crescente adozione dell'AI, ma pone anche nuove sfide e opportunità per le aziende che valutano strategie di deployment.
La decisione delle telco cinesi di adottare un modello di fatturazione a token per i servizi di intelligenza artificiale evidenzia una maturazione del mercato. Questo approccio, comune nel settore degli LLM, permette una monetizzazione granulare dell'utilizzo delle risorse computazionali necessarie per l'Inference. Per le imprese, ciò significa una maggiore trasparenza sui costi operativi, ma anche la necessità di ottimizzare l'uso dei modelli per controllare la spesa. La transizione verso un'Inference AI di massa implica che un numero sempre maggiore di applicazioni e servizi integrerà capacità AI, rendendo l'efficienza e la scalabilità dell'infrastruttura un fattore critico.
La monetizzazione a token e le implicazioni infrastrutturali
Il modello di fatturazione basato su token, sebbene offra flessibilità, sposta l'attenzione sulla gestione efficiente dei carichi di lavoro di Inference. Per le organizzazioni che considerano un deployment self-hosted di LLM, questo scenario sottolinea l'importanza di un'attenta analisi del TCO. La scelta tra un'infrastruttura cloud, con i suoi costi operativi variabili, e un deployment on-premise, che richiede un investimento iniziale (CapEx) più consistente ma offre un controllo maggiore sui costi a lungo termine e sulla sovranità dei dati, diventa cruciale.
Le telco, con le loro vaste infrastrutture di rete, sono posizionate in modo unico per offrire servizi di Inference AI, potenzialmente anche all'edge. Questo può ridurre la latenza e migliorare la privacy, aspetti fondamentali per applicazioni sensibili. Tuttavia, per le aziende che desiderano mantenere il pieno controllo sui propri dati e modelli, un'architettura on-premise o air-gapped rimane l'opzione preferibile. La capacità di gestire internamente l'intera pipeline di Inference, dalla scelta dell'hardware (come GPU con VRAM adeguata) all'ottimizzazione del software, permette di raggiungere livelli di performance e sicurezza difficilmente replicabili in ambienti esterni.
L'inference AI su larga scala: sfide e opportunità
L'espansione dell'Inference AI a un mercato di massa comporta una serie di sfide tecniche. La domanda di capacità computazionale per eseguire LLM e altri modelli AI in tempo reale è in costante crescita. Questo richiede non solo hardware potente, ma anche software ottimizzato per massimizzare il throughput e minimizzare la latenza. Le aziende devono valutare attentamente le proprie esigenze in termini di batch size, requisiti di memoria (VRAM) e velocità di elaborazione dei token per scegliere l'infrastruttura più adatta.
L'opportunità risiede nella possibilità di integrare l'AI in un'ampia gamma di prodotti e servizi, creando nuovo valore. Tuttavia, la scalabilità di questi deployment richiede una pianificazione meticolosa. Per chi opta per soluzioni self-hosted, la gestione di cluster di GPU, la configurazione di framework di serving efficienti e l'implementazione di strategie di quantization per ridurre i requisiti di memoria sono passaggi essenziali. La capacità di gestire questi aspetti internamente può tradursi in un vantaggio competitivo significativo, specialmente in settori con stringenti requisiti di compliance o dove la sovranità dei dati è prioritaria.
Prospettive future e considerazioni per il deployment
La tendenza verso l'Inference AI di massa, come dimostrato dalle iniziative delle telco cinesi, segna un punto di svolta nell'adozione dell'intelligenza artificiale. Le organizzazioni di ogni dimensione saranno sempre più chiamate a integrare l'AI nei loro processi core. La scelta dell'architettura di deployment – che sia cloud, ibrida o completamente on-premise – diventerà una decisione strategica che influenzerà direttamente il TCO, la sicurezza dei dati e la flessibilità operativa.
Per le aziende che valutano le opzioni di deployment on-premise per i propri carichi di lavoro LLM, è fondamentale considerare non solo i costi iniziali dell'hardware, ma anche i costi operativi a lungo termine, il consumo energetico e la complessità della gestione. AI-RADAR offre framework analitici su /llm-onpremise per aiutare a valutare questi trade-off, fornendo una guida neutrale sulle implicazioni di ciascuna scelta. Il futuro dell'AI è intrinsecamente legato alla capacità delle aziende di costruire e gestire infrastrutture resilienti, efficienti e sicure, capaci di supportare l'Inference su larga scala.










💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!