Microsoft: patch di aprile causa riavvii continui nei domain controller Windows
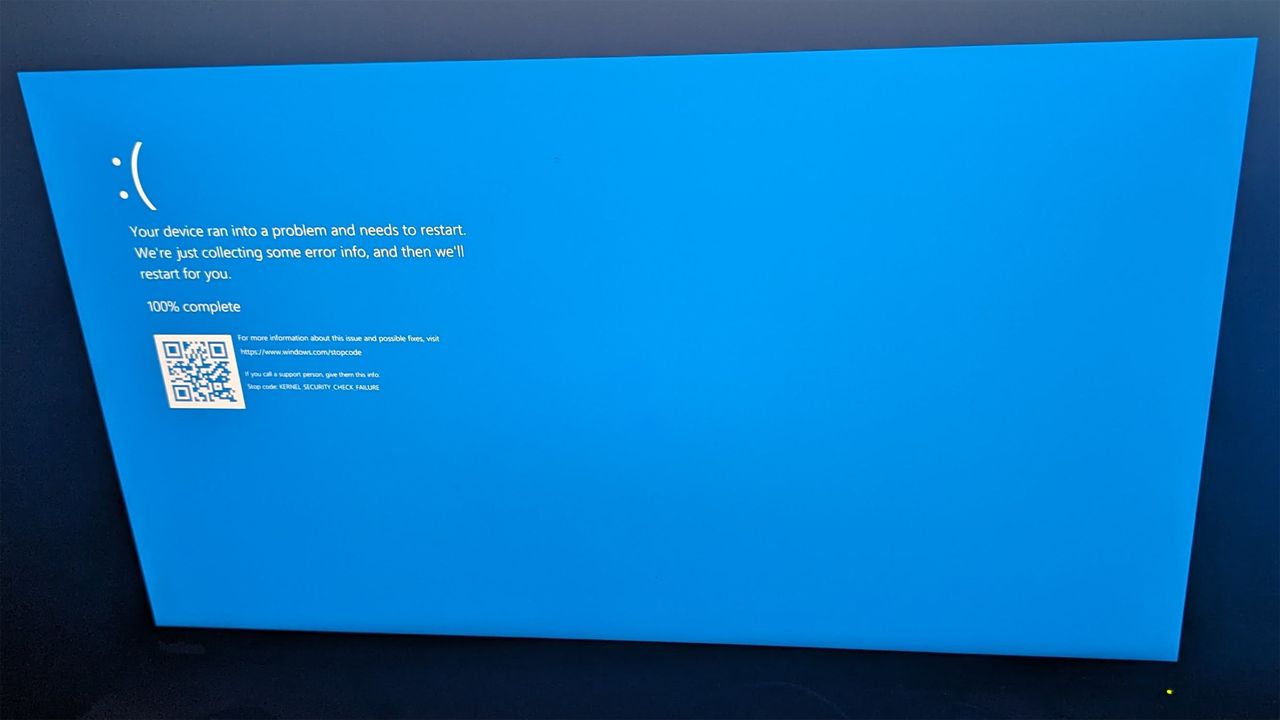
Una recente patch di sicurezza rilasciata da Microsoft ad aprile, identificata come KB5082063, sta generando problemi significativi per gli amministratori di sistema. L'aggiornamento, destinato a migliorare la sicurezza dei sistemi operativi Windows, ha invece innescato cicli di riavvio inattesi e continui su numerosi domain controller Windows Server. Questo inconveniente, che si manifesta con l'errore critico "Kernel_Security_Check_Failure", rappresenta il terzo problema noto associato a questa specifica patch.
La problematica interessa un'ampia gamma di versioni di Windows Server, coprendo le edizioni dal 2016 fino alla più recente 2025. La stabilità dei domain controller è cruciale per qualsiasi infrastruttura IT basata su Windows, poiché questi server gestiscono l'autenticazione, l'autorizzazione e la gestione delle risorse di rete, rendendo l'interruzione del loro funzionamento un evento potenzialmente paralizzante per le operazioni aziendali.
Dettagli tecnici e l'impatto sui sistemi
L'errore "Kernel_Security_Check_Failure" indica una violazione della sicurezza a livello del kernel del sistema operativo, spesso causata da driver difettosi, problemi di memoria o, come in questo caso, da aggiornamenti software che introducono instabilità. La sua comparsa sui domain controller, server che per loro natura devono garantire un'operatività continua e affidabile, è particolarmente preoccupante. La patch KB5082063, lungi dal rafforzare la sicurezza, ha introdotto un elemento di vulnerabilità operativa che richiede un'attenzione immediata.
Il fatto che questo sia il terzo problema documentato per la stessa patch di aprile solleva interrogativi sui processi di controllo qualità degli aggiornamenti software. Ogni interruzione dei servizi di un domain controller può avere un effetto a cascata sull'intera rete, bloccando l'accesso degli utenti alle risorse, impedendo l'autenticazione e compromettendo la disponibilità di applicazioni e dati. Per le organizzazioni che fanno affidamento su infrastrutture self-hosted, la gestione di tali imprevisti diventa una priorità assoluta.
Implicazioni per l'infrastruttura IT e i deployment on-premise
La stabilità dell'infrastruttura IT è un pilastro fondamentale per qualsiasi azienda, e la gestione degli aggiornamenti software rappresenta una delle sfide più complesse. Incidenti come quello causato dalla patch KB5082063 evidenziano la necessità di strategie robuste per il deployment degli aggiornamenti, che includano fasi di test rigorose in ambienti controllati prima della distribuzione su larga scala. Questo è particolarmente vero per le organizzazioni che optano per deployment on-premise, dove il controllo diretto sull'hardware e sul software comporta anche la piena responsabilità della loro operatività.
Per le aziende che stanno valutando l'implementazione di carichi di lavoro AI, inclusi i Large Language Models (LLM), su infrastrutture self-hosted, la lezione è chiara: la resilienza e l'affidabilità dei sistemi operativi e dei servizi di base sono prerequisiti indispensabili. Un'infrastruttura instabile può vanificare qualsiasi investimento in hardware di calcolo avanzato o in software AI, compromettendo la continuità operativa e la sovranità dei dati. AI-RADAR offre framework analitici su /llm-onpremise per valutare i trade-off tra controllo, TCO e performance in contesti di deployment on-premise.
Prospettive e gestione del rischio
Di fronte a problemi di questa natura, le organizzazioni sono chiamate a bilanciare la necessità di mantenere i sistemi aggiornati con il rischio di introdurre nuove vulnerabilità operative. La cautela nell'applicazione delle patch critiche, specialmente quelle che hanno già mostrato problemi, è fondamentale. È consigliabile attendere le comunicazioni ufficiali di Microsoft con eventuali soluzioni o patch correttive, e nel frattempo, implementare mitigazioni temporanee se possibile.
Questo episodio sottolinea l'importanza di una solida strategia di gestione del rischio IT, che includa piani di rollback e sistemi di monitoraggio proattivo. La capacità di identificare e risolvere rapidamente le anomalie è essenziale per mantenere l'integrità e la disponibilità delle infrastrutture, indipendentemente dal fatto che ospitino servizi tradizionali o le più recenti applicazioni basate su AI. La fiducia nella stabilità del proprio ambiente IT è un fattore chiave per l'innovazione e la crescita tecnicica.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!