L'obiettivo dell'Harness Engineering è plasmare l'intelligenza di un modello per compiti specifici, ottimizzando performance, efficienza dei token e latenza. Questo approccio si concentra sulla costruzione di strumenti attorno al modello per raggiungere questi obiettivi.
Analisi dei Traces per il Debug
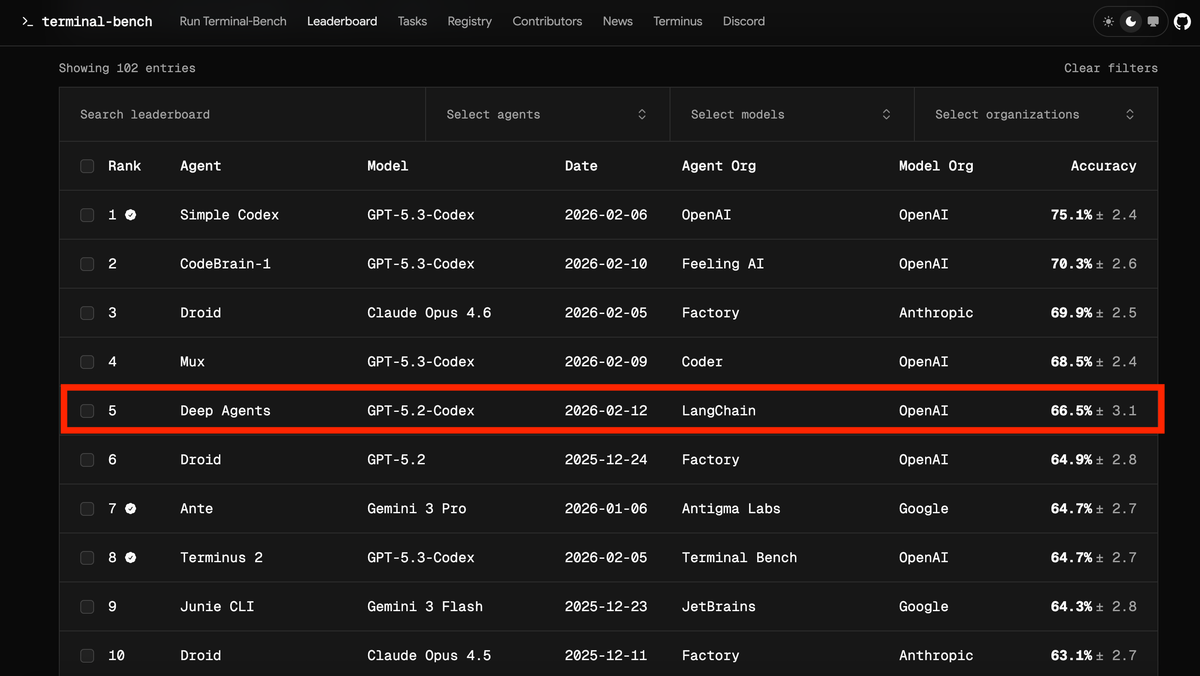
LangChain utilizza i Traces per comprendere i punti deboli degli agenti su larga scala. Analizzando input e output, è possibile identificare aree di miglioramento. Un semplice processo iterativo ha permesso di migliorare le prestazioni dell'agente di coding deepagents-cli di 13.7 punti su Terminal Bench 2.0, passando dal 52.8% al 66.5%, agendo unicamente sull'harness e mantenendo il modello (gpt-5.2-codex) invariato.
Configurazione dell'Esperimento
È stato utilizzato Terminal Bench 2.0 per valutare le capacità di coding dell'agente. Harbor è stato impiegato per orchestrare le esecuzioni, gestendo sandbox (Daytona), interazioni con l'agente e processi di verifica. Ogni azione dell'agente è stata memorizzata in LangSmith, includendo metriche come latenza, numero di token e costi.
Componenti Chiave dell'Harness
L'harness di un agente offre diverse leve di intervento: system prompt, strumenti, middleware, competenze, delega a sotto-agenti e sistemi di memoria. L'ottimizzazione si è concentrata su tre aspetti principali: System Prompt, Strumenti e Middleware (hook attorno alle chiamate al modello e agli strumenti).
Skill di Analisi dei Traces
L'analisi dei Traces è stata trasformata in una skill dell'agente per renderla ripetibile. Il flusso di lavoro prevede:
- Recupero dei Traces degli esperimenti da LangSmith.
- Generazione di agenti paralleli per l'analisi degli errori; l'agente principale sintetizza i risultati e i suggerimenti.
- Aggregazione del feedback e modifiche mirate all'harness.
Questo processo è simile al boosting, concentrandosi sugli errori delle esecuzioni precedenti. L'intervento umano può essere utile per verificare e discutere le modifiche proposte, evitando l'overfitting.
Miglioramenti Implementati
L'analisi automatizzata dei Traces ha permesso di individuare le aree in cui gli agenti commettevano errori, come errori di ragionamento, mancato rispetto delle istruzioni, assenza di test e verifiche, e superamento dei limiti di tempo.
Build & Self-Verify
I modelli odierni hanno capacità di auto-miglioramento. L'auto-verifica consente agli agenti di migliorarsi tramite feedback durante l'esecuzione. È stata aggiunta una guida al system prompt su come affrontare la risoluzione dei problemi, includendo:
- Pianificazione e scoperta.
- Implementazione.
- Verifica.
- Correzione.
È stata data enfasi ai test, che alimentano i cambiamenti in ogni iterazione. Un PreCompletionChecklistMiddleware intercetta l'agente prima dell'uscita e ricorda di eseguire una verifica rispetto alle specifiche del task.
Contesto Ambientale
L'Harness Engineering include la creazione di un meccanismo di delivery per il contesto. Un LocalContextMiddleware mappa le directory e trova strumenti come le installazioni di Python. L'iniezione di contesto riduce gli errori e facilita l'onboarding dell'agente nel suo ambiente. È stato insegnato agli agenti a scrivere codice testabile, sottolineando che il loro lavoro sarà misurato rispetto a test programmati. Sono stati aggiunti avvisi relativi al budget di tempo per spingere l'agente a terminare il lavoro e passare alla verifica.
Riconsiderazione dei Piani
Un LoopDetectionMiddleware tiene traccia del numero di modifiche per file tramite hook di chiamata degli strumenti. Aggiunge contesto come "...considera di riconsiderare il tuo approccio" dopo N modifiche allo stesso file.
Calcolo per il Ragionamento
È necessario decidere quanto calcolo dedicare a ogni sotto-task. GPT-5.2-codex ha 4 modalità di ragionamento: low, medium, high e xhigh. È stato scoperto che il ragionamento aiuta nella pianificazione e nella verifica. Un approccio "reasoning sandwich" (xhigh-high-xhigh) è stato utilizzato come baseline.
Conclusioni Pratiche
- Context Engineering per conto degli agenti.
- Aiutare gli agenti a verificare il proprio lavoro.
- Utilizzare i Traces come segnale di feedback.
- Rilevare e correggere i pattern negativi a breve termine.
- Adattare gli Harness ai modelli.
Per chi valuta deployment on-premise, esistono trade-off da considerare. AI-RADAR offre framework analitici su /llm-onpremise per valutare questi trade-off.










💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!