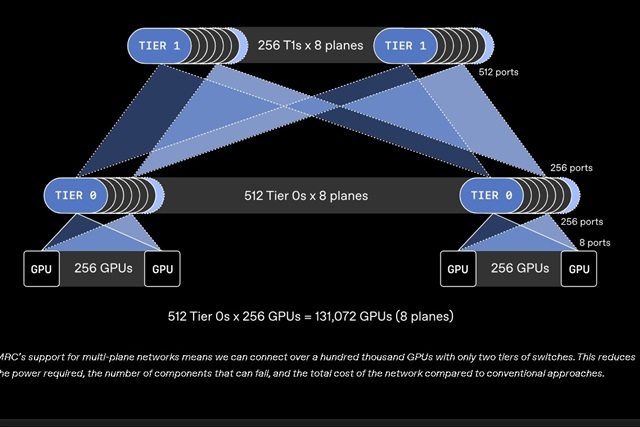
A Joint Initiative to Accelerate AI Training
OpenAI, in collaboration with major silicon manufacturers, has announced the introduction of a new initiative, named MRC, designed to address and prevent slowdowns that can compromise the efficiency of artificial intelligence model training processes. This strategic partnership highlights the growing awareness that the advancement of AI depends not only on algorithms and data but also on the ability of the underlying infrastructure to support increasingly intense and complex workloads.
Training Large Language Models (LLMs) and other large-scale AI models requires immense computational resources. Slowdowns can arise from bottlenecks at various levels, from GPU memory bandwidth to latency in communication between cluster nodes. The objective of MRC is precisely to identify and resolve these inefficiencies, ensuring that hardware resources are utilized to their full potential.
The Technical Challenges of Large-Scale Training
Training cutting-edge AI models is a technically arduous undertaking. Modern GPUs, while extremely powerful, must handle data volumes and parameters that often exceed the available VRAM capacity or the data transfer speed between various components. This leads to situations where compute units remain idle awaiting data, drastically reducing overall throughput and prolonging training times.
Issues such as memory management, data pipeline optimization, and synchronization among thousands of processor cores are commonplace. Solutions that improve efficiency at the chip and system level are fundamental to unlocking the potential of next-generation models. The MRC initiative positions itself precisely in this context, seeking to refine the interaction between software and hardware to overcome these structural limitations.
Implications for On-Premise Deployments
For organizations opting for self-hosted deployments for their AI workloads, initiatives like MRC take on even greater importance. The ability to prevent training slowdowns directly translates into an improved Total Cost of Ownership (TCO) and more efficient utilization of expensive acquired hardware resources. In an on-premise environment, every GPU clock cycle and every byte of VRAM counts, as the initial infrastructure investment is significant.
Data sovereignty, regulatory compliance, and the need to operate in air-gapped environments are often the drivers behind self-hosted solutions. However, these choices demand meticulous optimization of the entire training and inference pipeline. Tools and standards emerging from collaborations like that between OpenAI and chipmakers can provide the foundation for building more performant and resilient local stacks, maximizing return on investment and ensuring complete control over the AI infrastructure. For those evaluating the trade-offs of on-premise deployments, AI-RADAR offers analytical frameworks on /llm-onpremise to delve deeper into these considerations.
Future Prospects and Hardware-Software Synergy
The collaboration between AI model developers like OpenAI and silicon giants is a clear signal of the industry's direction. Optimization is no longer an exclusive task of software or hardware but requires deep synergy between the two. Solutions like MRC aim to create a more cohesive ecosystem where innovations at the chip level can be fully leveraged by the most advanced algorithms.
This integrated approach is essential to overcome current and future barriers in training increasingly larger and more capable AI models. Regardless of whether a company chooses to operate in the cloud or with bare metal infrastructure, training efficiency remains a critical factor for innovation and competitiveness. The MRC initiative represents a significant step towards a future where slowdowns will no longer be an insurmountable obstacle to the evolution of artificial intelligence.











💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!