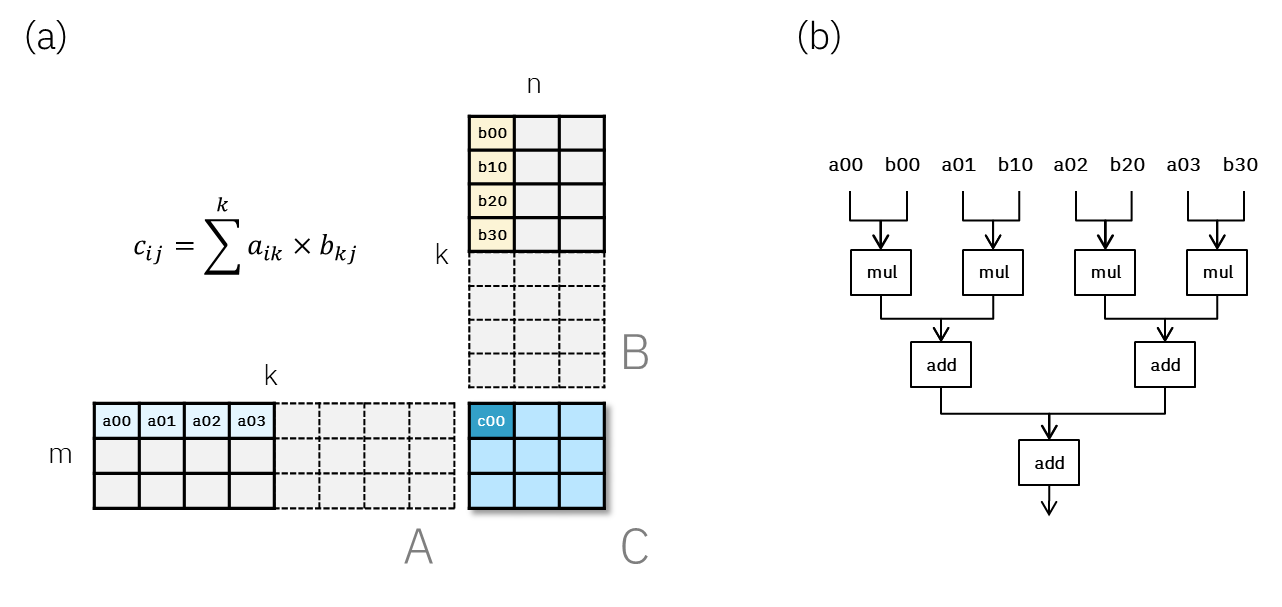
Motori GEMM e precisione degli accumulatori
Le GPU e gli acceleratori personalizzati integrano motori di calcolo specializzati per la moltiplicazione di matrici, noti anche come GEMM. Questi motori eseguono in modo efficiente la moltiplicazione di matrici su blocchi di tensori di piccole dimensioni. I compilatori o le librerie suddividono problemi di moltiplicazione di matrici di grandi dimensioni in problemi più piccoli, alimentandoli a questi motori.
Un aspetto spesso trascurato è che, per ragioni di efficienza hardware, l'output FP32 di un Tensor Core potrebbe avere meno di 23 bit di mantissa effettivi. In altre parole, la precisione dell'operazione Tensor Core è inferiore a FP32. Questa scelta progettuale può influire sulla precisione del modello in determinate circostanze.
Verifica della precisione con Triton
L'articolo descrive un approccio per studiare la precisione dell'accumulatore utilizzando il kernel Triton. L'idea è di applicare una maschera per troncare gli ultimi N<sub>trun</sub> bit dell'output del Tensor Core. Confrontando l'output della moltiplicazione di matrici con un riferimento (nessuna troncamento), è possibile dedurre la precisione dell'accumulatore.
Triton è stato scelto perché consente di generalizzare il metodo ad altri acceleratori che lo supportano, velocizzando lo sviluppo.
Risultati sperimentali
I risultati mostrano che troncando fino a 10 bit meno significativi della mantissa dell'output (utilizzando H100 FP8 TensorCore) si ottengono gli stessi risultati del caso senza troncamento. Questo suggerisce che l'accumulatore è implementato utilizzando un formato FP22 speciale (e8m13) per motivi di efficienza di calcolo. Lo stesso esperimento è stato ripetuto su una GPU RTX4000 e ha mostrato lo stesso comportamento.
È fondamentale assicurarsi che il TensorCore che esegue l'attività sia quello previsto (FP8). In rare situazioni, il compilatore Triton potrebbe scegliere di utilizzare istruzioni FP16 TensorCore per determinati calcoli FP8. Lo strumento di profilazione Nvidia ncu può essere utilizzato per ispezionare le istruzioni CUDA sottostanti associate alla chiamata Triton tl.dot.
Se la precisione della moltiplicazione di matrici è una preoccupazione critica, si dovrebbe provare a utilizzare un'accumulazione FP32 intermedia.
Conclusioni
Comprendere la precisione dell'accumulatore è fondamentale per gli utenti con applicazioni sensibili alla precisione che sviluppano kernel personalizzati, nonché per i progettisti hardware che devono emulare questo comportamento per i loro progetti di nuova generazione. L'approccio basato su kernel Triton può essere combinato con l'ecosistema PyTorch, estendendo la stessa tecnica ad altri acceleratori esistenti e futuri che supportano il linguaggio Triton.










💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!