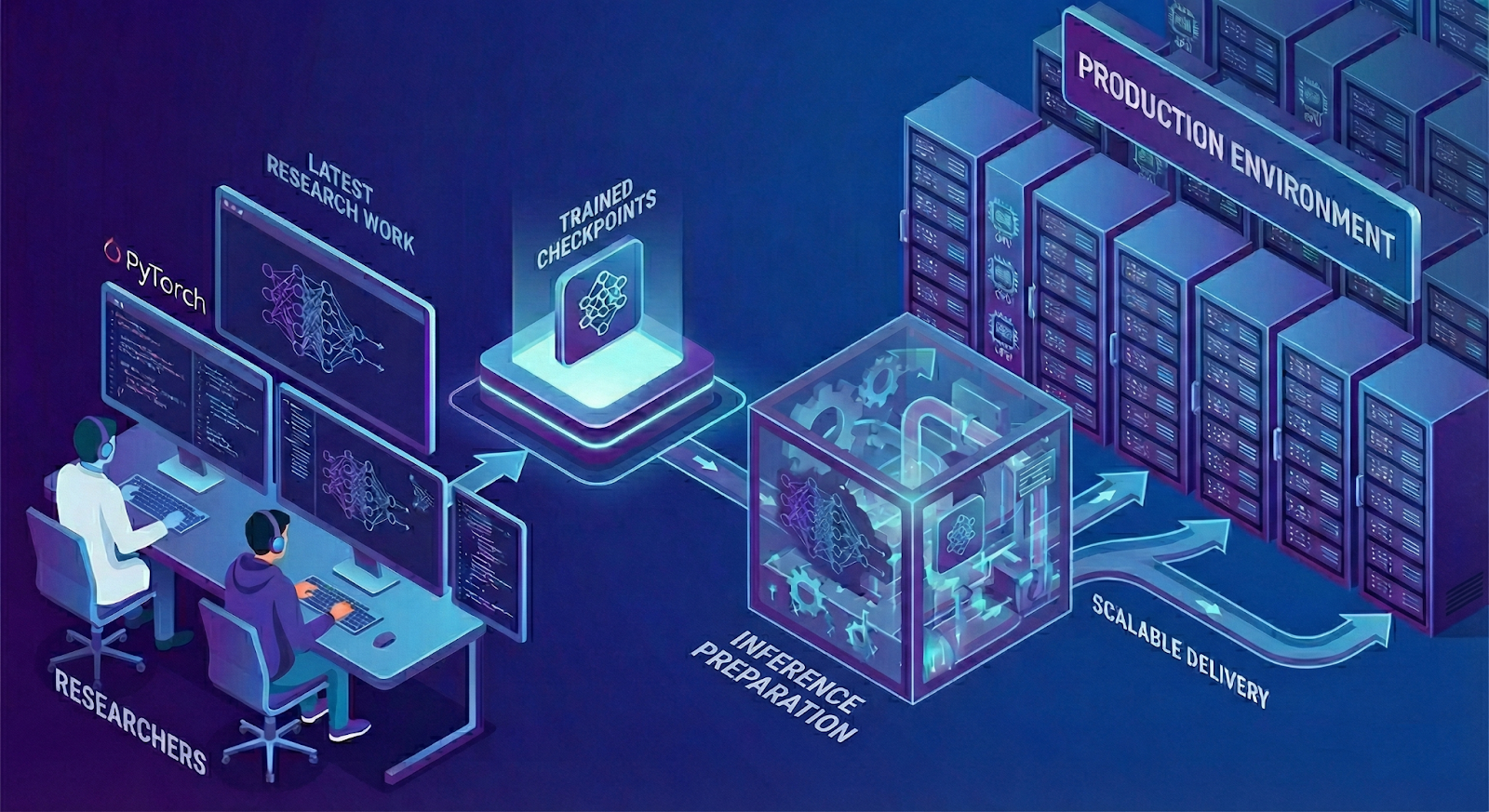
Meta ha realizzato un sistema di inference per raccomandazioni basato su PyTorch, progettato per tradurre rapidamente i progressi della ricerca in applicazioni reali. Questo sistema supporta architetture ML diversificate, dalle estensioni del modello DLRM a tecniche avanzate come DHEN e HSTU.
Pipeline di lavoro generale
Il sistema converte i modelli addestrati in modelli ottimizzati per l'inference, garantendo un utilizzo efficiente dell'hardware e alte prestazioni (QPS) con bassa latenza. Questo processo include la definizione di un modello di inference dedicato, l'acquisizione del grafo computazionale e l'applicazione di trasformazioni e ottimizzazioni.
Trasformazione e ottimizzazione del modello
Le trasformazioni includono lo splitting del modello per l'inference distribuita, la fusione di operatori, la quantization e la compilazione. La serializzazione del modello utilizza formati come TorchScript e torch.export per garantire la backward compatibility e risolvere i problemi di dipendenza da Python.
Caricamento ed esecuzione del modello
Dopo aver preparato i modelli di inference, il runtime elabora le richieste. Un server di inference basato su PyTorch gestisce il serving, con un wrapper leggero per l'esecuzione, API flessibili basate su tensori e una rappresentazione DAG (Directed Acyclic Graph) del modello.
Ottimizzazioni chiave
Le ottimizzazioni includono l'inference su GPU, l'utilizzo di un runtime C++ per alte QPS, l'inference distribuita (CPU-GPU, embedding-dense, parallelismo denso), compilatori AI (AOTInductor, AITemplate, TensorRT) e librerie kernel ad alte prestazioni (CUTLASS, Composable Kernels, ZenDNN, OneDNN).
Per chi valuta deployment on-premise, esistono trade-off discussi in dettaglio su AI-RADAR nella sezione /llm-onpremise.
Altre tecniche includono il request coalescing, table batched embedding, la quantization (bf16, int8, int4) e gli aggiornamenti delta per mantenere la freschezza del modello.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!