
The Sovereign Developer: Surviving the Great Token Squeeze of 2026
Welcome to the end of the AI charity era. For the past three years, developers have been living in a venture-capital-funded utopia, burning through $8 to $13 of compute for every $1 spent on flat-rate AI subscriptions. We gleefully highlighted entire codebases, asked our IDEs to "refactor this to be more Pythonic," and went to grab a coffee while Microsoft and Anthropic absorbed the staggering costs of server farms running hotter than a small city.
But as of mid-2026, the AI industry’s "subsidy scam" has officially collapsed. GitHub Copilot’s shift to a token-based usage model on June 1, 2026, represents a fundamental paradigm shift for software engineers. We are no longer renting intelligence; we are buying it by the token. This editorial is your comprehensive, iron-clad survival guide to navigating the new metered reality, escaping the "Context Trap," and reclaiming your workflow by bringing AI inference back to your local machine.
--------------------------------------------------------------------------------
Part I: The Collapse of the Cloud Subsidy
The catalyst for this industry-wide reckoning was GitHub's announcement that Copilot is ditching Premium Request Units (PRUs) in favor of "GitHub AI Credits". Starting June 1, 2026, your $10 Copilot Pro or $39 Copilot Pro+ subscription provides exactly $10 or $39 worth of token consumption, billed at the listed API rates for the models you use.

For light users asking simple autocomplete questions, the change is negligible. But for the modern developer running multi-step agentic workflows, repository-wide reasoning, and exhaustive debugging sessions, the costs will stack up with terrifying speed. A single prompt analyzing a massive codebase using a frontier model like Claude Opus 4.6 or GPT-5.5 could effortlessly burn through $10 to $30 of API credits in fifteen minutes.
Microsoft framed this generously as "an important step toward a sustainable, reliable Copilot business," noting that a quick chat question and a multi-hour autonomous coding session previously cost the user the same amount. Translation: Microsoft is tired of footing the bill for your 100-file refactoring sprees while their CFO hyperventilates over GPU procurement costs. Even reviewing a pull request with Copilot now drains your included GitHub Actions minutes.
Adding insult to injury, the "fallback" safety nets are gone. Under the old system, exhausting your PRUs meant you were quietly downgraded to a cheaper model. In the new usage-based era, when your credits are gone, you are cut off entirely until you open your wallet for more. Unused credits do not roll over to the next month; it is a strict "use it or lose it" scenario.
The Frontier API Price Matrix (Q2 2026)
If you decide to abandon Copilot and go directly to the API providers, the pricing remains sobering.
| Model Tier | Input Cost (per 1M Tokens) | Output Cost (per 1M Tokens) | Context Window | Benchmark (SWE-bench Verified) |
|---|---|---|---|---|
| Claude Opus 4.7 | $5.00 | $25.00 | 1M | 82.0% |
| GPT-5.4 | $5.00 | $15.00 | 1M | ~80.0% |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M | 79.6% |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | 80.6% |
| DeepSeek V4 Pro | $1.74 | $3.48 | 1M | 77.4% (Unverified)* |
| DeepSeek V4 Flash | $0.14 | $0.28 | 1M | N/A |
Note: DeepSeek V4 acts as the great open-source price disruptor, undercutting Claude Opus by 50x on input tokens, though independent benchmarks are still pending verification. All prices sourced from March/April 2026 data*.
When Anthropic estimates that heavy enterprise users spend between $150 and $250 a month on Claude Code—amounting to over $3,000 annually per developer—the financial argument for local hardware transcends hobbyist tinkering and becomes a fiscal mandate.
--------------------------------------------------------------------------------
Part II: The Hardware Battlefield (NVIDIA vs. Apple Silicon)
If you are transitioning to local AI, the first truth you must accept is that VRAM is everything. Processor speed is practically an afterthought; your bottleneck will almost exclusively be the memory capacity to hold the model weights and the memory bandwidth to push those weights through the computational pipeline.
In 2026, the hardware debate has fractured into two distinct theological camps: the raw throughput of NVIDIA's discrete GPUs versus the massive capacity of Apple Silicon's unified memory.
- The NVIDIA Route: Speed and Ecosystem
NVIDIA remains the undisputed king of the AI software ecosystem. CUDA is the bedrock of machine learning; PyTorch, vLLM, and Flash Attention are optimized for NVIDIA first, and everything else second.
- The Apple Silicon Route: Capacity and Silence
For those who prefer not to run a jet engine in their living room, Apple's M-series chips (M3/M4/M5) offer an architectural miracle: Unified Memory. Because the CPU and GPU share the same RAM pool, a Mac Studio with 128GB or an M4 Pro Mac Mini with 48GB can load massive 70B or even 100B+ Mixture-of-Experts (MoE) models entirely in memory.
+-------------------------------------------------------------+
| Hardware Paradigm Shift: The "Gotcha" of Apple Silicon |
+-------------------------------------------------------------+
| While a Mac Mini M4 Pro (48GB) costs a reasonable $1,799 |
| and sips 50W of power, it sacrifices raw speed [42, 50].|
| MEMORY BANDWIDTH COMPARISON: |
| NVIDIA RTX 5090: 1,792 GB/s [31, 38] |
| Apple M4 Pro: 273 GB/s [51] |
| Apple M4 Max: 546 GB/s [52] |
| Apple M5 Ultra: ~800 GB/s [52] |
| Result: A Mac can hold a 70B model, but token generation |
| speed might hover around 8-15 tok/s, compared to 50+ tok/s |
| on NVIDIA hardware [53, 54]. Prompt processing is also |
| significantly slower on Macs, which bottlenecks agentic |
| coding workflows where fast feedback is required [1238, 1243|
+-------------------------------------------------------------+
If you are running complex agentic loops that require reading 10K lines of code, an NVIDIA setup will do it in seconds, whereas a Mac may take minutes to ingest the context. However, if you require a massive context window on a strict budget, Apple remains the only way to avoid spending $15,000+ on enterprise RTX 6000 Ada workstations.
--------------------------------------------------------------------------------
Part III: The 2026 Local Model Roster
The "Frontier Gap"—the cognitive disparity between closed-source monoliths and open-weight models—has effectively vanished for coding tasks. In 2026, you don't need a trillion parameters to fix a Python script; you just need a specialized, repository-aware model.
- Qwen 3.5 Coder (Alibaba)
The absolute sweet spot for single-GPU setups. Qwen3-Coder comes in a 32B dense variant and a 30B MoE variant (A3B, which only activates ~3B parameters per token). It boasts an immense 256K context window and handles repository-level coding tasks beautifully. On a single RTX 4090, Qwen3-Coder 32B achieves 64 tokens/s and matches GPT-4o's performance on the HumanEval benchmark (92.7%).
- DeepSeek-Coder-V2 (DeepSeek)
This 236B parameter MoE model only activates 21B parameters during inference, making it incredibly efficient. Trained on 10.2 trillion tokens covering 338 programming languages, it achieved a 90.2% score on HumanEval and broke records on the SWE-bench repair benchmark (12.7%), making it the top open-source bug-fixing model available. If you have dual 3090s or a Mac Studio with 64GB+ unified memory, this is a phenomenal daily driver.
- Llama 4 Scout vs. Maverick (Meta)
Meta's early-2026 release bifurcated their open-weights strategy.
- The Surprising Open Source Contenders
Do not ignore models like Codestral 22B, which fits comfortably on a single 24GB GPU, boasts a 32K context, and excels at repository benchmarks. Additionally, MiniMax M2.5 and GLM-5.1 have recently posted SWE-bench scores (80.2% and 77.8% respectively) that rival Claude Opus 4.6 (80.8%), proving that Asian AI labs are pushing the open-weights frontier to unprecedented heights.
--------------------------------------------------------------------------------
Part IV: The Quantization Trap (Why "8-bit" Ruined Your Code)
To fit these massive models into consumer hardware, we rely on quantization—the dark art of reducing numerical precision (e.g., from 16-bit to 4-bit) to shrink file sizes. A standard assumption is that "Q4 loses quality, Q8 is safe."
In 2025, a landmark paper by Dong et al. systematically dismantled this assumption, revealing a catastrophic phenomenon: 8-bit quantization destroyed 92% of the HumanEval pass rate on a 13B model, while 4-bit degradation was only 22%.
How is this logically possible? The issue stems from conflating two different types of quantization. When the community uses tools like llama.cpp to create GGUF formats (like Q4_K_M), they are using weight-only quantization (W4A16), meaning the weights are compressed to 4-bit, but the neural activations remain in FP16/FP32.
The 92% capability destruction occurred during W8A8-INT quantization (weight + activation quantization), where activations were rounded down to 8-bit integers. Cramming the massive dynamic range of LLM activations into an 8-bit integer completely distorts the intermediate state of inference, causing catastrophic failure specifically in syntax-heavy tasks like code generation.
The takeaway: If you are running Q4_K_M GGUF models on an RTX 4060 or a Mac, you are structurally insulated from this 92% degradation. Do not chase 8-bit activation quantization for coding models. If you upgrade to Blackwell hardware (RTX 5090), you can utilize NVFP4—hardware-native 4-bit floating-point arithmetic—which matches or beats the quality of software Q4 with superior speed.
--------------------------------------------------------------------------------
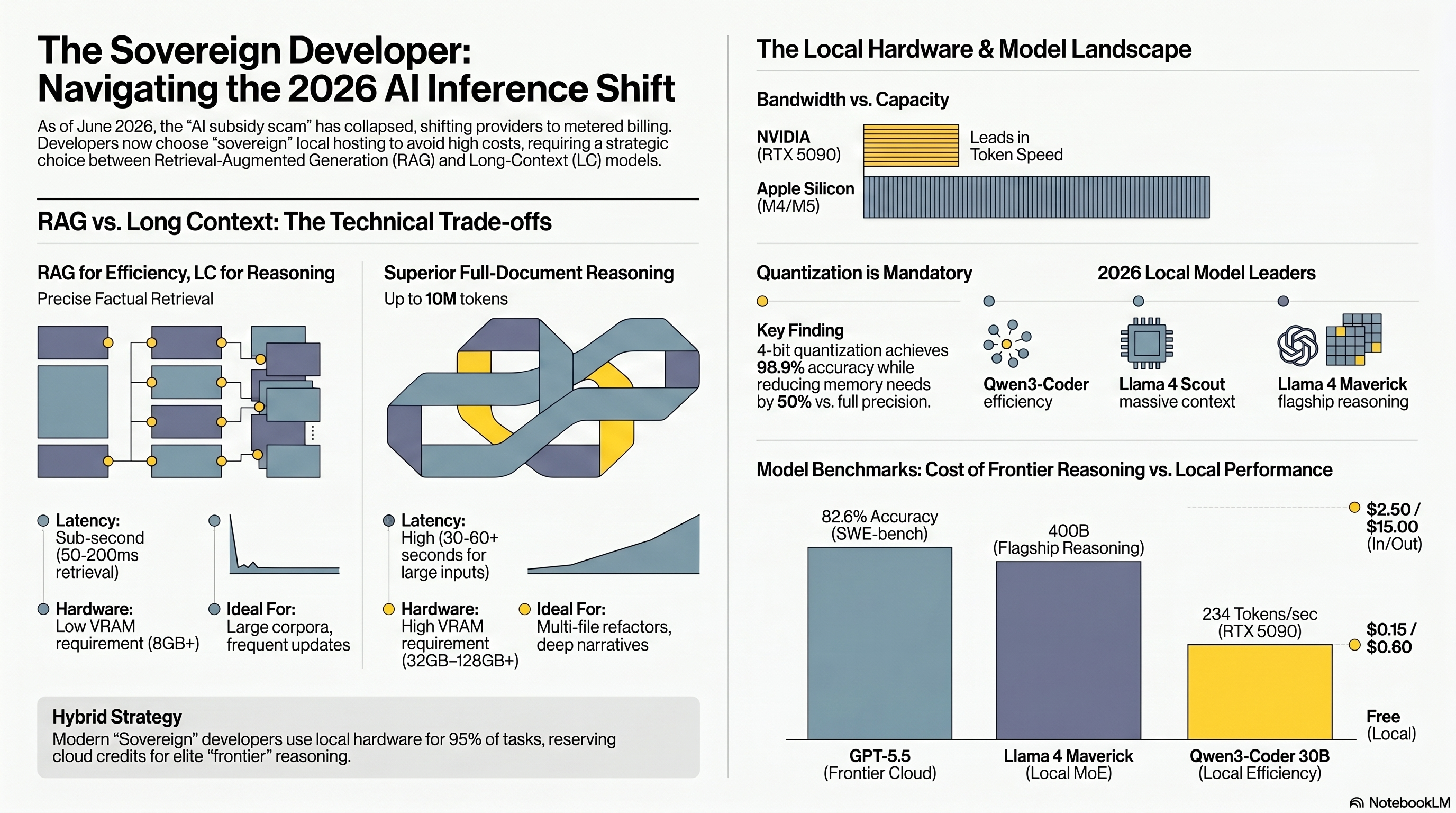
Part V: The 10-Million Token Void vs. RAG
With models like Llama 4 Scout boasting 10 million token context windows, a logical question arises: Is Retrieval-Augmented Generation (RAG) dead? Why build a vector database when I can just paste my entire repo into the prompt?
The truth is much messier. The "Infinite Context" pitch is largely marketing hype masking severe computational realities.
Primacy and Recency Bias (The "Lost in the Middle" Effect): LLMs suffer from severe accuracy degradation (drops of 10-20%+) when relevant information is buried in the middle of a massive context window. Models are good at remembering the start and end of a prompt, but they gloss over the center.The Context Cost: Expanding context length quadratically increases computational requirements for attention mechanisms. On cloud APIs, feeding a 100,000-token prompt costs a fortune. Locally, it eats your KV Cache alive, causing out-of-memory errors and grinding "Time To First Token" (TTFT) to a halt.RAG is Faster and Cheaper: RAG pipelines retrieve only the relevant 2,000 tokens of context, taking 50-200ms for vector retrieval. Processing a 100K token prompt natively can take 30 to 60 seconds.
OP-RAG: The Evolution of Retrieval
A recent Nvidia study introduced Order-Preserve RAG (OP-RAG), which fundamentally improves RAG for coding and document tasks. Traditional RAG fetches chunks based purely on cosine similarity scores, presenting the LLM with a disjointed, Frankenstein-esque collage of text. OP-RAG retrieves the top chunks but re-orders them to match their original chronological sequence in the source document.
This simple tweak preserves the logical progression of the text. In tests on a Llama 3.1-70B model, using OP-RAG with just 48,000 tokens achieved a 47.25 F1 score, completely demolishing the 34.26 F1 score achieved by brute-forcing 117,000 tokens of raw context without RAG.
The Verdict: Do not blindly stuff millions of tokens into your prompt. Use a hybrid architecture: embed your repository for RAG retrieval, and pass only the relevant chunks (in chronological order) into a 32K–64K context window for the local LLM to reason over.
--------------------------------------------------------------------------------
Part VI: Terminal Velocity (Tools of the Trade)
Local hardware is useless without an interface that matches the seamlessness of Cursor or Copilot. In 2026, the ecosystem has moved to terminal-based, API-agnostic orchestrators.
- OpenCode: The TUI Powerhouse
OpenCode is an open-source, CLI-based coding agent written in Go. Unlike locked-in extensions, OpenCode treats AI models as interchangeable modules. It connects natively to local Ollama instances and supports the Model Context Protocol (MCP).
Its superpower is mid-session model switching. You can begin a session by querying a local Qwen 2.5 Coder to generate boilerplate, hit a complex architectural hurdle, type /models to instantly switch the backend to Claude Opus 4.7 via API to solve the logic, and switch back to local for the execution. All your project data stays private on your machine unless you explicitly route a specific prompt to the cloud.
- Aider: Zero-Cost Pair Programming
Aider integrates directly with your Git repo, autonomously editing files and committing changes. To prevent local models from suffering "silent data drops" (where they forget instructions halfway through a file), Aider utilizes a .aider.model.settings.yml file to explicitly define context limits and edit formats for local models.
Aider popularized the Architect Mode: you use a frontier cloud model (like GPT-5.5) as the "Architect" to create the blueprint and planning, and then an entirely local model (like llama3 or qwen3.5-coder:14b) executes the code changes as the "Editor". This perfectly balances cloud intelligence with local execution speeds and zero API output costs.
- Tunneling to Cursor via Ngrok
If you refuse to leave the Cursor IDE, you can bypass their local-model restrictions by treating your own PC as a remote server. By running LM Studio or Ollama locally, you can use ngrok to expose your localhost:1234 or 11434 port to a public URL. Plug that Ngrok URL into Cursor's "OpenAI Base URL" settings, input a dummy API key, and Cursor will flawlessly route all autocomplete and chat requests to your local GPU. (Note: this does route data through Ngrok's infrastructure, slightly compromising the "air-gapped" privacy of pure local setups).
--------------------------------------------------------------------------------
Part VII: The 3-Year ROI (Is it Actually Worth It?)
Let's address the anxiety of upfront capital expenditure. Is dropping $2,500 on a local rig actually cheaper than paying $39/month for Copilot Pro+?
Yes. Because you aren't just paying $39.
In an agentic coding world, you pay the subscription plus the usage overages. A professional developer leaning heavily on agentic tools (like Claude Code or OpenCode) can easily burn through $75 to $200 a month in API tokens alone.
The 3-Year Math:
Cloud-Native Developer: $39/mo (Subscription) + 75/mo(APItokens)∗36months=∗∗4,104.Local Mid-Range Developer: $1,800 (Hardware: Ryzen 7 + RTX 4070 / Used 3090) + 15/*mo(Electricity)∗36months*=∗∗2,340.
The hardware pays for itself in roughly 16 to 20 months. But the financial ROI pales in comparison to the qualitative returns:
Zero Token Anxiety: You will never again subconsciously shorten prompts, limit refactoring, or stifle exploration to save a few pennies.Air-Gapped Privacy: For developers working on proprietary corporate architecture or sensitive security code, sending raw data to a third-party API is a massive liability. Local AI means zero telemetry leaves the room.Sub-Second Latency: Cloud latency varies wildly based on server load. Local models on fast VRAM provide instantaneous responses, keeping you firmly locked in the developer "flow state".
Conclusion
The era of relying entirely on Microsoft and Anthropic to subsidize our coding habits is over. As cloud providers shift to aggressive usage-based billing and introduce rate limits to protect their own compute, the sovereign developer must adapt.
You don't need a $15,000 server rack. A used RTX 3090 or a Mac Mini M4 Pro, paired with Qwen3-Coder or DeepSeek-V2 and an orchestrator like OpenCode, provides a coding assistant that rivals the finest cloud models of 2025, completely free of token anxiety.
In the meantime I'm trying different strategies with my GMKtec Evo-x2. Indeed the 128 GB of LPDDR5X 8000MHz memory and the AI AMD Ryzen AI Max+ 395 gives me lot of HPs to play with and i can afford 30b around models with a decent speed. Playing a lot with Nemotron (altough not leveraging on Cuda),Gemma and Gwen and not convinced at all about using quantizations on the big guys.
Maybe we are near to face a revolutionary change??
Should we say: Stop renting your brain. Own your compute?











💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!