Introduction: LLM Efficiency for Agentic Workloads
In the rapidly evolving landscape of Large Language Models (LLMs), inference efficiency represents a critical challenge, especially for on-premise deployments and complex workloads. The ability to process a high number of tokens per second (tps) is fundamental to ensure rapid responses and optimize hardware resource utilization. In this context, the open-source TokenSpeed inference engine, developed by the LightSeek Foundation, has recently set a new benchmark.
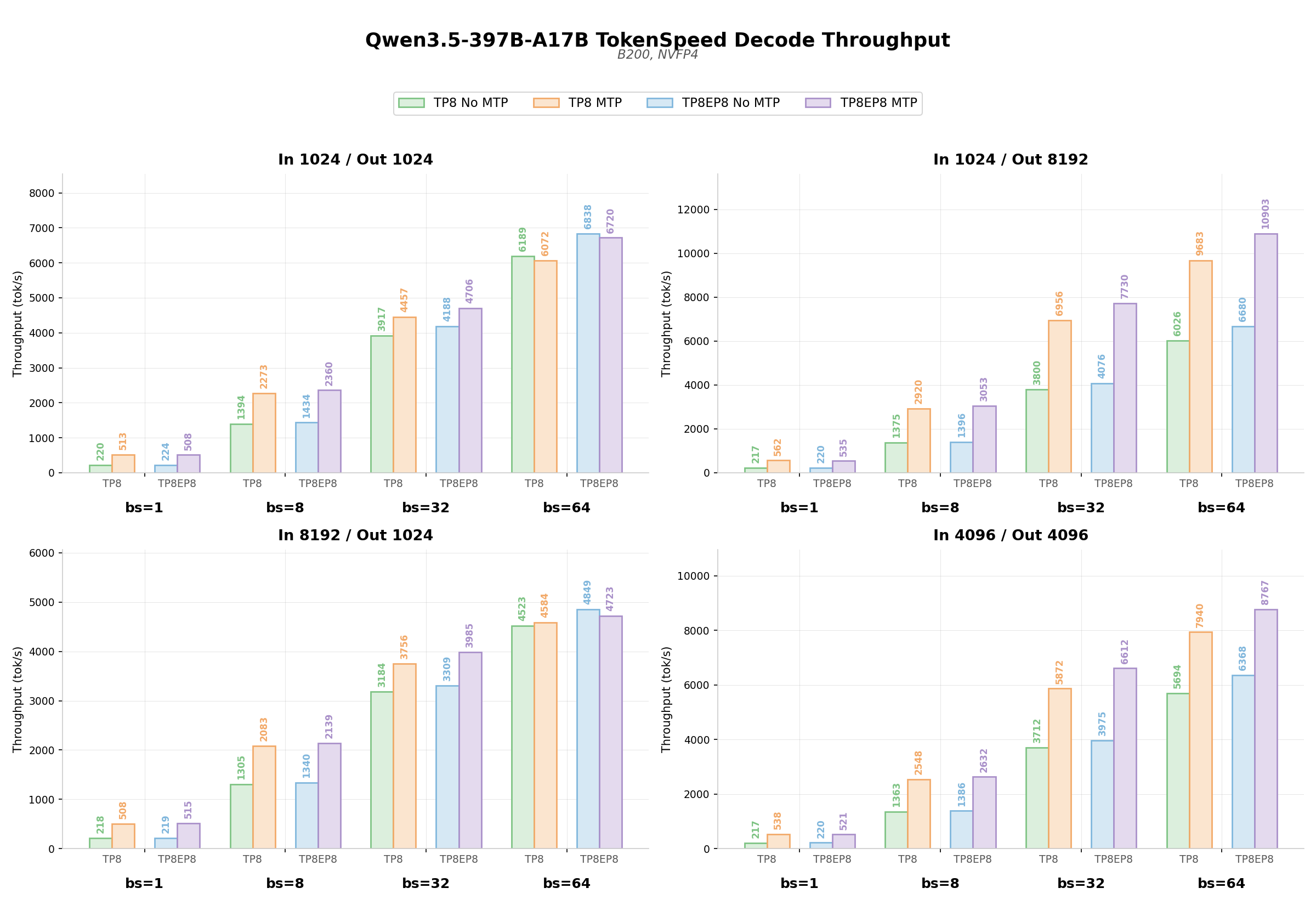
TokenSpeed achieved a throughput of 580 tps with the Qwen3.5-397B-A17B model on NVIDIA Blackwell GPUs, a remarkable result for agentic workloads. These workloads, characterized by multi-turn tool-calling sequences and extended dialogue contexts, require particularly sophisticated memory and computation management. TokenSpeed's goal is to offer performance comparable to TensorRT-LLM while maintaining the ease of use typical of vLLM, making it an interesting solution for those seeking granular control and extreme performance in their local stacks.
Technical and Architectural Details of the Qwen3.5 Model and TokenSpeed
The Qwen3.5-397B-A17B model stands out for its hybrid architecture, which combines standard full attention layers with linear attention layers based on the Gated Delta Network (GDN). This design choice allows for maintaining high modeling capabilities while reducing computational complexity, especially for inference with long sequences. Qwen models, in general, are known for their versatility, supporting everything from edge computing to complex cloud environments, with integrated features for autonomous agent planning and multi-step task execution.
TokenSpeed was designed with a native SPMD (Single Program, Multiple Data) architecture and static compilation, elements that contribute to its ability to accelerate the execution of complex agentic tasks. The engine fully supports Qwen3.5's hybrid architecture, efficiently managing both the KV Cache (for full attention layers) and the Mamba State (for linear attention layers) as separate resource pools. This includes GDN/Mamba prefix caching, crucial for agentic workloads that often share long contexts and conversation histories. Slot lifecycle management and copy-on-write logic ensure data integrity, preventing stale states.
Performance Optimizations and Hardware Efficiency
Achieving 580 tps is the result of a series of deep optimizations designed to maximize GPU utilization. Among these, the systematic elimination of memory copies stands out, achieved, for example, through index indirection for Mamba state updates in speculative decoding. Instead of copying entire tensors, TokenSpeed moves pointers, reducing an O(L·D) operation to an O(1) integer write, a significant gain in terms of throughput and latency reduction.
Another pillar of the optimizations is the extensive use of kernel fusions and CUDA multi-stream parallelism. Operations that would traditionally require separate kernel launches, with consequent overheads and memory bandwidth waste, are fused into a single Triton kernel. Examples include Gemma AllReduce fusion, QK-RMSNorm + RoPE + Gate Split fusion in attention, and Gate-Sigmoid-Mul-Add fusion in the MoE shared expert. Multi-stream parallelism also allows for overlapping the execution of independent workloads, such as shared and routed experts in MoE layers, or GDN input projections, reducing overall latency. The use of CUDA Graphs to capture the entire decode loop eliminates dispatch overhead for thousands of kernels, while the elimination of Device-to-Host round-trips and compile-fused index arithmetic minimize CPU overhead, keeping the GPU saturated.
Implications for On-Premise Deployments and Future Prospects
For CTOs, DevOps leads, and infrastructure architects evaluating self-hosted LLM solutions, TokenSpeed's performance with Qwen3.5-397B-A17B offers important insights. The ability to sustain high throughput (580 tps at bs=1) for agentic workloads on GPUs like NVIDIA Blackwell B200, with a high KV Cache hit rate (over 90%), translates into significant optimization of the operational TCO (Total Cost of Ownership). Lower latency and higher throughput mean more requests handled with the same infrastructure, or the possibility of using less hardware for the same workload.
Efficient management of long contexts, up to 1 million tokens with contained degradation, is another critical factor for applications requiring extended conversational memory or complex document processing. This is particularly relevant for environments with stringent data sovereignty requirements or for air-gapped deployments, where local hardware efficiency is the sole determining factor. TokenSpeed continues its development, with support for Flash Attention 4 (FA4) for Blackwell architectures in the pipeline, promising further improvements. Its open-source nature and the availability of a Docker image facilitate adoption and testing in on-premise environments, offering developers and infrastructure teams the tools to build and deploy ultra-fast, production-grade AI applications. For those evaluating on-premise deployments, AI-RADAR offers analytical frameworks on /llm-onpremise to assess the trade-offs between performance, costs, and control.









💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!