Introduzione: L'Efficienza degli LLM per Carichi di Lavoro "Agentic"
Nel panorama in rapida evoluzione dei Large Language Models (LLM), l'efficienza nell'Inference rappresenta una sfida cruciale, specialmente per i deployment on-premise e i carichi di lavoro complessi. La capacità di elaborare un elevato numero di token al secondo (tps) è fondamentale per garantire risposte rapide e ottimizzare l'utilizzo delle risorse hardware. In questo contesto, l'engine di Inference open-source TokenSpeed, sviluppato dalla LightSeek Foundation, ha recentemente stabilito un nuovo primato.
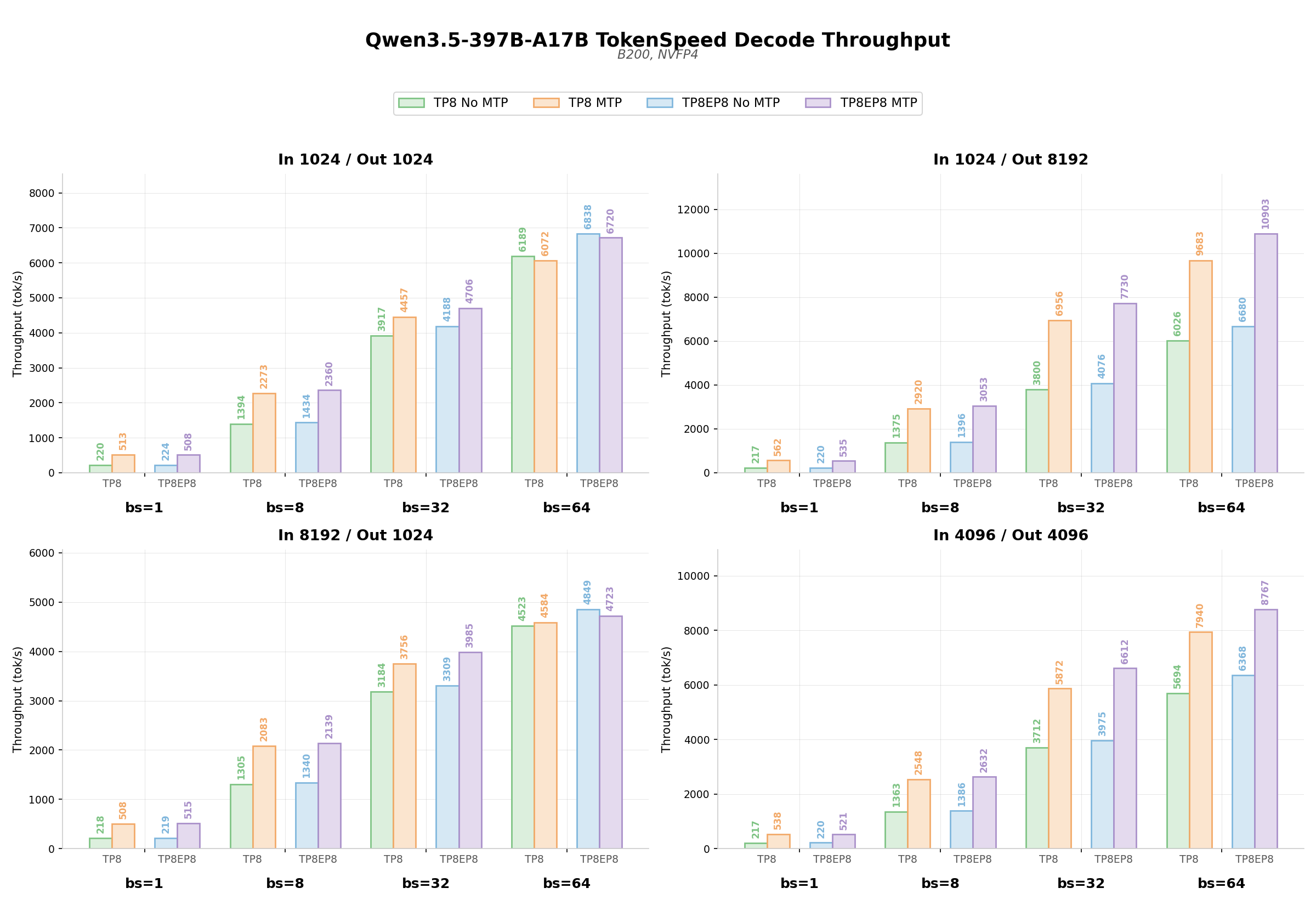
TokenSpeed ha raggiunto un throughput di 580 tps con il modello Qwen3.5-397B-A17B su GPU NVIDIA Blackwell, un risultato notevole per i carichi di lavoro "agentic". Questi ultimi, caratterizzati da sequenze di tool-calling multi-turno e contesti di dialogo estesi, richiedono una gestione particolarmente sofisticata della memoria e del calcolo. L'obiettivo di TokenSpeed è offrire performance paragonabili a quelle di TensorRT-LLM, mantenendo al contempo la facilità d'uso tipica di vLLM, rendendolo una soluzione interessante per chi cerca un controllo granulare e prestazioni estreme nei propri stack locali.
Dettagli Tecnici e Architetturali del Modello Qwen3.5 e di TokenSpeed
Il modello Qwen3.5-397B-A17B si distingue per la sua architettura ibrida, che combina strati di "full attention" standard con strati di "linear attention" basati sulla Gated Delta Network (GDN). Questa scelta progettuale consente di mantenere elevate capacità di modellazione riducendo la complessità computazionale, soprattutto per l'Inference con sequenze lunghe. I modelli Qwen, in generale, sono noti per la loro versatilità, supportando dall'edge computing agli ambienti cloud complessi, con funzionalità integrate per la pianificazione autonoma degli agenti e l'esecuzione di task multi-step.
TokenSpeed è stato concepito con un'architettura SPMD (Single Program, Multiple Data) nativa e una compilazione statica, elementi che contribuiscono alla sua capacità di accelerare l'esecuzione di task "agentic" complessi. L'engine supporta pienamente l'architettura ibrida di Qwen3.5, gestendo in modo efficiente sia il KV Cache (per i layer di "full attention") sia lo stato Mamba (per i layer di "linear attention") come pool di risorse separati. Questo include un caching dei prefissi GDN/Mamba, cruciale per i carichi di lavoro "agentic" che spesso condividono contesti lunghi e cronologie di conversazione. La gestione del ciclo di vita degli slot e la logica "copy-on-write" assicurano l'integrità dei dati, prevenendo stati obsoleti.
Ottimizzazioni per le Performance e l'Efficienza Hardware
Il raggiungimento di 580 tps è il risultato di una serie di ottimizzazioni profonde, pensate per massimizzare l'utilizzo delle GPU. Tra queste, spicca l'eliminazione sistematica delle copie di memoria, ottenuta, ad esempio, tramite l'indirezione degli indici per gli aggiornamenti dello stato Mamba nello "speculative decoding". Invece di copiare interi tensori, TokenSpeed sposta puntatori, riducendo un'operazione O(L·D) a una scrittura intera O(1), un guadagno significativo in termini di throughput e riduzione della latenza.
Un altro pilastro delle ottimizzazioni è l'ampio ricorso alle fusioni di kernel e al parallelismo multi-stream CUDA. Operazioni che tradizionalmente richiederebbero lanci di kernel separati, con conseguenti overhead e spreco di banda di memoria, vengono fuse in un unico kernel Triton. Esempi includono la fusione di Gemma AllReduce, la fusione di QK-RMSNorm con RoPE e Gate Split nell'attention, e la fusione di Gate-Sigmoid-Mul-Add nell'expert condiviso MoE. Il parallelismo multi-stream, inoltre, consente di sovrapporre l'esecuzione di carichi di lavoro indipendenti, come gli "shared expert" e i "routed expert" nei layer MoE, o le proiezioni di input GDN, riducendo la latenza complessiva. L'utilizzo di CUDA Graphs per catturare l'intero ciclo di decode elimina l'overhead di dispatch per migliaia di kernel, mentre l'eliminazione dei round-trip Device-to-Host e l'aritmetica degli indici fusa in compilazione riducono al minimo l'overhead della CPU, mantenendo la GPU satura.
Implicazioni per i Deployment On-Premise e Prospettive Future
Per CTO, DevOps lead e architetti infrastrutturali che valutano soluzioni LLM self-hosted, le performance di TokenSpeed con Qwen3.5-397B-A17B offrono spunti importanti. La capacità di sostenere un throughput elevato (580 tps a bs=1) per carichi di lavoro "agentic" su GPU come le NVIDIA Blackwell B200, con un'elevata percentuale di hit del KV Cache (oltre il 90%), si traduce in un'ottimizzazione significativa del TCO (Total Cost of Ownership) operativo. Minore latenza e maggiore throughput significano più richieste gestite con la stessa infrastruttura, o la possibilità di utilizzare meno hardware per lo stesso carico di lavoro.
La gestione efficiente di contesti lunghi, fino a 1 milione di token con una degradazione contenuta, è un altro fattore critico per applicazioni che richiedono memoria conversazionale estesa o elaborazione di documenti complessi. Questo è particolarmente rilevante per ambienti con stringenti requisiti di sovranità dei dati o per deployment "air-gapped", dove l'efficienza dell'hardware locale è l'unico fattore determinante. TokenSpeed continua il suo sviluppo, con il supporto per Flash Attention 4 (FA4) per le architetture Blackwell in cantiere, promettendo ulteriori miglioramenti. La sua natura open-source e la disponibilità di un'immagine Docker facilitano l'adozione e il testing in ambienti on-premise, offrendo agli sviluppatori e ai team infrastrutturali gli strumenti per costruire e rilasciare applicazioni AI ultra-veloci e di livello produttivo. Per chi valuta deployment on-premise, AI-RADAR offre framework analitici su /llm-onpremise per valutare i trade-off tra performance, costi e controllo.









💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!