TorchInductor accoglie CuteDSL per ottimizzare le operazioni critiche degli LLM
TorchInductor, il compilatore JIT (Just-In-Time) integrato in PyTorch, ha recentemente annunciato l'integrazione di CuteDSL come quarto backend per l'ottimizzazione delle moltiplicazioni matriciali (GEMM). Questa mossa strategica si affianca ai backend esistenti come Triton, CUTLASS (C++) e cuBLAS, con l'obiettivo di migliorare ulteriormente le performance dei carichi di lavoro basati su Large Language Models (LLM) su hardware NVIDIA.
L'ottimizzazione delle GEMM è un aspetto cruciale per l'efficienza degli LLM, poiché queste operazioni rappresentano la maggior parte del profilo di calcolo durante la fase di forward pass nei modelli basati su architetture Transformer. L'introduzione di CuteDSL risponde alla crescente esigenza di un controllo più granulare sull'hardware di ultima generazione, pur mantenendo tempi di compilazione rapidi e un ridotto carico di manutenzione per i team di sviluppo. Questa combinazione di fattori lo posiziona come un investimento strategico a lungo termine per l'ecosistema PyTorch.
La strategia dietro l'ottimizzazione delle GEMM e i vantaggi di CuteDSL
Non tutte le operazioni beneficiano allo stesso modo di un nuovo backend. Per le operazioni memory-bound, come le matematiche elementwise, le attivazioni e le riduzioni, Triton genera già codice di alta qualità, grazie al suo modello di programmazione a blocchi. Le GEMM, tuttavia, rappresentano una sfida diversa. Queste operazioni richiedono un controllo estremamente preciso sulle funzionalità hardware introdotte da ogni nuova generazione di GPU, inclusi i dimensionamenti dei tile, la gestione esplicita della memoria condivisa, lo scheduling a livello di warp e, sulle architetture più recenti come B200, i cluster di thread block e la memoria condivisa distribuita.
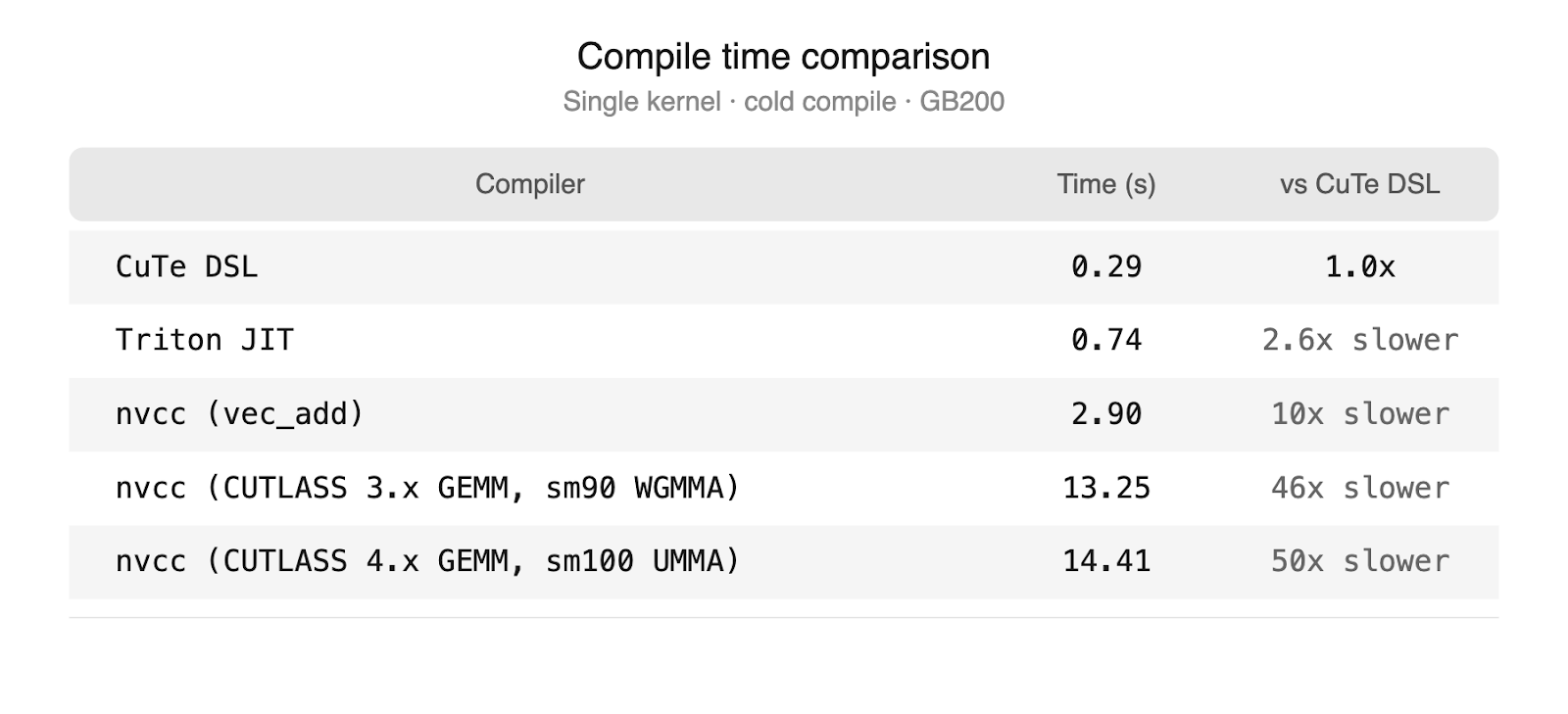
CuteDSL affronta queste complessità attraverso un compilatore personalizzato da Python a MLIR. Sebbene sia basato sulle stesse astrazioni di CUTLASS C++ – la stessa algebra dei tile, le stesse primitive della gerarchia di memoria e lo stesso modello di epilogue fusion – CuteDSL compila a velocità paragonabili agli altri backend di TorchInductor. Questo risolve il problema del sovraccarico di compilazione del backend CUTLASS C++, che richiede invocazioni complete di nvcc per ogni variante del kernel, rendendo impraticabile la valutazione di molteplici candidati durante l'autotuning. Inoltre, NVIDIA contribuisce attivamente con template di kernel ottimizzati, garantendo a CuteDSL un vantaggio nell'adozione delle ottimizzazioni specifiche per l'hardware più recente.
Architettura e risultati di performance su NVIDIA B200
Il backend CuteDSL si integra nella pipeline di autotuning di TorchInductor in modo additivo. Quando il compilatore incontra una moltiplicazione matriciale, interroga cutlass_api, una libreria Python mantenuta da NVIDIA che contiene l'intero spazio delle configurazioni dei kernel GEMM di CuteDSL. Per gestire le centinaia di configurazioni compatibili, il backend utilizza nvMatmulHeuristics, un modello analitico di performance di NVIDIA, per selezionare i candidati più promettenti (tipicamente cinque) da compilare e sottoporre a benchmark sull'hardware target. Questo approccio garantisce che l'abilitazione di NVGEMM non possa causare regressioni di performance, poiché il sistema seleziona automaticamente il backend più veloce.
I benchmark, eseguiti su una singola GPU NVIDIA B200 a 850W con PyTorch nightly e Cuda 13.1, hanno evidenziato miglioramenti significativi. A livello di kernel, CuteDSL ha mostrato speedup fino a 1.73x per le operazioni BF16 in scenari di decode, fino a 1.78x per MXFP8 su forme di medie dimensioni e fino a 1.6x per NVFP4 su forme di dimensioni ridotte. Per quanto riguarda l'inference end-to-end di LLM con vLLM (su modelli come Llama 3.1 8B, Qwen3 32B e Llama 3.3 70B), l'integrazione di NVGEMM ha ridotto la latenza fino al 6.5% per BF16 e fino al 4.2% per NVFP4, con guadagni più consistenti a batch size tra 16 e 64. Per le organizzazioni che valutano deployment on-premise di LLM, l'ottimizzazione a basso livello come quella offerta da CuteDSL è fondamentale per massimizzare il ritorno sull'investimento hardware e garantire la sovranità dei dati. AI-RADAR offre framework analitici su /llm-onpremise per valutare questi trade-off.
Prospettive future e impatto sui deployment on-premise
Il roadmap di sviluppo per il backend CuteDSL è ambizioso. Tra le priorità future figurano il benchmarking dell'epilogue fusion, che permetterà di valutare la convenienza di fondere operazioni downstream direttamente nel kernel GEMM, e l'implementazione della precompilazione parallela asincrona con caching persistente. Quest'ultima funzionalità ridurrà ulteriormente i tempi di autotuning, eliminando la necessità di ricompilare i kernel già ottimizzati.
Sono previsti anche lo sviluppo di cache di configurazione esportabili per la portabilità tra ambienti e il supporto alla compilazione AOT (Ahead-Of-Time) per i deployment di inference, eliminando il sovraccarico di autotuning in fase di esecuzione. A lungo termine, l'obiettivo è che CuteDSL raggiunga la piena parità di performance con il backend CUTLASS C++ sulle nuove generazioni di hardware, consentendone la sostituzione e semplificando la codebase di TorchInductor. Questi sviluppi sono particolarmente rilevanti per gli architetti di infrastrutture e i responsabili DevOps che gestiscono carichi di lavoro AI/LLM in ambienti self-hosted, dove l'efficienza, il controllo e il TCO sono fattori determinanti.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!