Ottimizzazione delle GEMM: la chiave per l'efficienza dei Large Language Models
L'efficienza dei Large Language Models (LLM) dipende in larga parte dalla capacità di eseguire rapidamente le General Matrix Multiplications (GEMM), operazioni che costituiscono il cuore computazionale di questi modelli. Per affrontare questa sfida, TorchInductor, il compilatore JIT di PyTorch, ha annunciato l'integrazione di CuteDSL come quarto backend di autotuning, affiancandosi a Triton, CUTLASS (C++) e cuBLAS. Questa mossa strategica mira a sbloccare nuove vette di performance, in particolare per i carichi di lavoro di inference LLM su hardware NVIDIA di ultima generazione.
L'introduzione di CuteDSL non è un semplice aggiornamento, ma un investimento a lungo termine. Il nuovo backend è stato progettato per offrire un controllo granulare sulle funzionalità hardware più recenti, essenziale per massimizzare l'utilizzo di GPU complesse. Per le organizzazioni che gestiscono deployment on-premise, ogni miglioramento prestazionale si traduce direttamente in un TCO inferiore e in una maggiore capacità operativa, consentendo di ottenere più risultati dalla stessa infrastruttura.
CuteDSL: un ponte tra astrazione e performance hardware
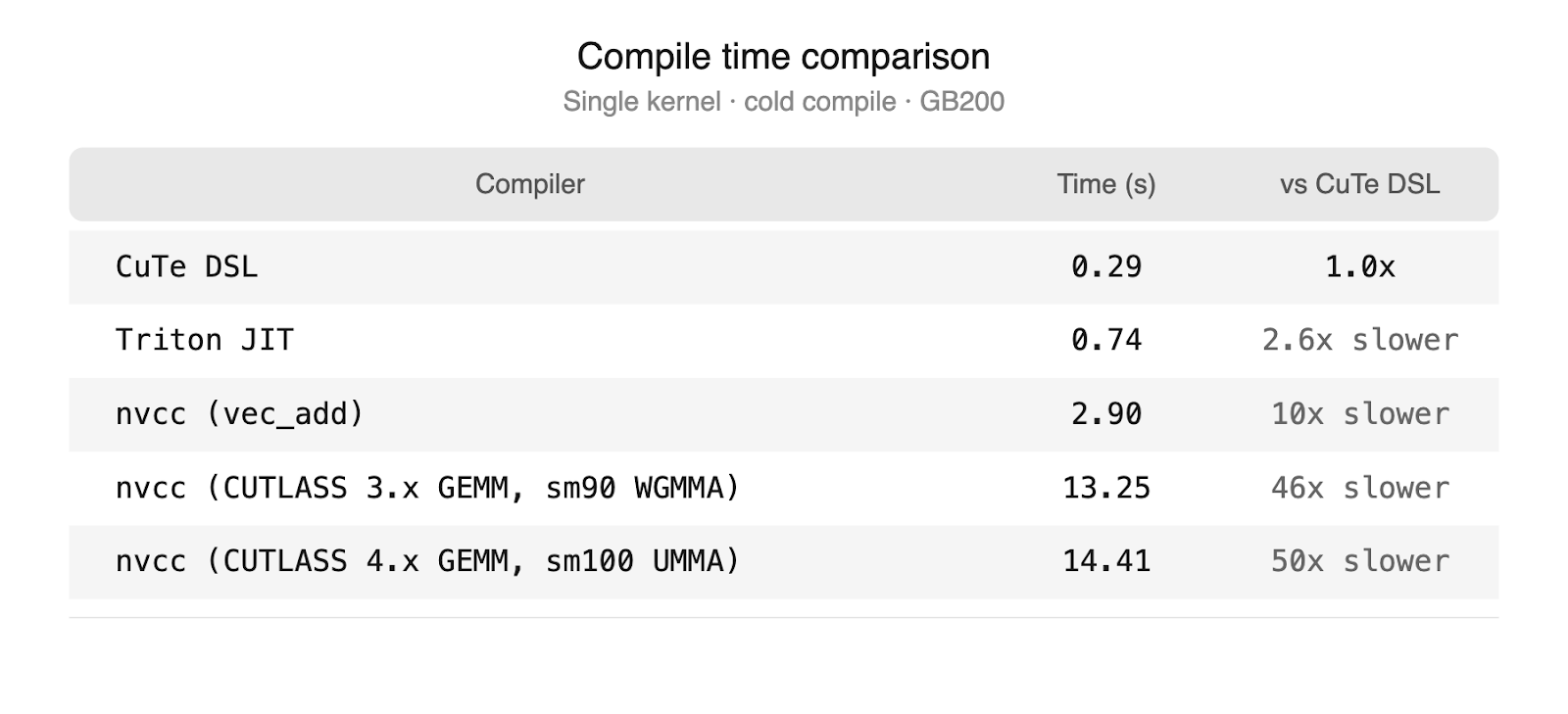
CuteDSL si distingue per la sua capacità di combinare l'astrazione di un Domain Specific Language (DSL) basato su Python con il controllo di basso livello tipico di CUTLASS C++. Questa architettura ibrida risolve uno dei principali colli di bottiglia dei backend C++: gli elevati tempi di compilazione. Grazie a un compilatore personalizzato da Python a MLIR, CuteDSL raggiunge velocità di compilazione paragonabili agli altri backend di TorchInductor, rendendo praticabile l'autotuning e la fusione degli epiloghi, processi critici per l'ottimizzazione delle GEMM.
NVIDIA supporta attivamente lo sviluppo di CuteDSL, fornendo template di kernel ottimizzati che riducono il carico di manutenzione per il team di TorchInductor. Questa collaborazione garantisce che il backend possa sfruttare tempestivamente le innovazioni hardware, come le funzionalità di memoria condivisa distribuita su architetture come H100 e B200. La capacità di esporre l'intera gerarchia di thread e memoria è fondamentale per raggiungere performance vicine al picco su queste operazioni computazionalmente intense.
Impatto sui deployment on-premise e la sovranità dei dati
Per CTO, responsabili DevOps e architetti di infrastruttura che valutano alternative self-hosted rispetto al cloud per i carichi di lavoro AI/LLM, l'integrazione di CuteDSL in TorchInductor rappresenta un fattore significativo. Le ottimizzazioni a livello di kernel e i miglioramenti end-to-end nell'inference si traducono in un maggiore throughput e una minore latenza per GPU. Questo significa che le aziende possono elaborare più richieste con la stessa infrastruttura, o ridurre il numero di GPU necessarie, incidendo positivamente sul TCO complessivo.
I benchmark condotti su una singola GPU NVIDIA B200 (850W) hanno mostrato accelerazioni a livello di kernel fino a 1.73x per BF16, 1.78x per MXFP8 e 1.6x per NVFP4. A livello di inference end-to-end, si sono registrate riduzioni della latenza fino al 6.5% per BF16 su Llama 3.3 70B e fino al 4.2% per NVFP4 su Llama 3.1 8B. Questi numeri sottolineano come l'ottimizzazione del software a stretto contatto con l'hardware sia cruciale per massimizzare il valore degli investimenti in infrastrutture AI locali, supportando al contempo requisiti di sovranità dei dati e compliance.
Prospettive future e strategie di ottimizzazione
La roadmap di sviluppo per il backend CuteDSL è ambiziosa e include diverse aree chiave. Tra queste, la fusione degli epiloghi nei benchmark, la precompilazione parallela asincrona e la caching persistente dei kernel compilati promettono di ridurre ulteriormente i tempi di autotuning e migliorare le performance a lungo termine. È prevista anche la possibilità di esportare cache di configurazione portatili, offrendo maggiore flessibilità nella gestione dei deployment su diverse configurazioni hardware.
L'approccio di TorchInductor, che utilizza cutlass_api per selezionare le configurazioni kernel e nvMatmulHeuristics per ridurre lo spazio di ricerca, garantisce che venga sempre selezionata la configurazione più performante. Poiché il backend CuteDSL è puramente additivo, non può causare regressioni prestazionali, assicurando che l'introduzione di nuove ottimizzazioni avvenga senza rischi. Questa strategia di miglioramento continuo è fondamentale per mantenere la competitività nei deployment on-premise, dove l'efficienza è un parametro non negoziabile.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!