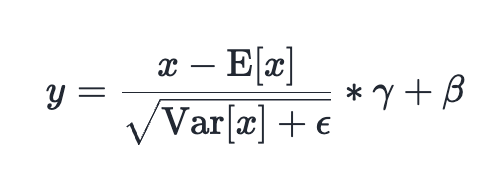SOTA Normalization Performance with torch.compile on H100 and B200
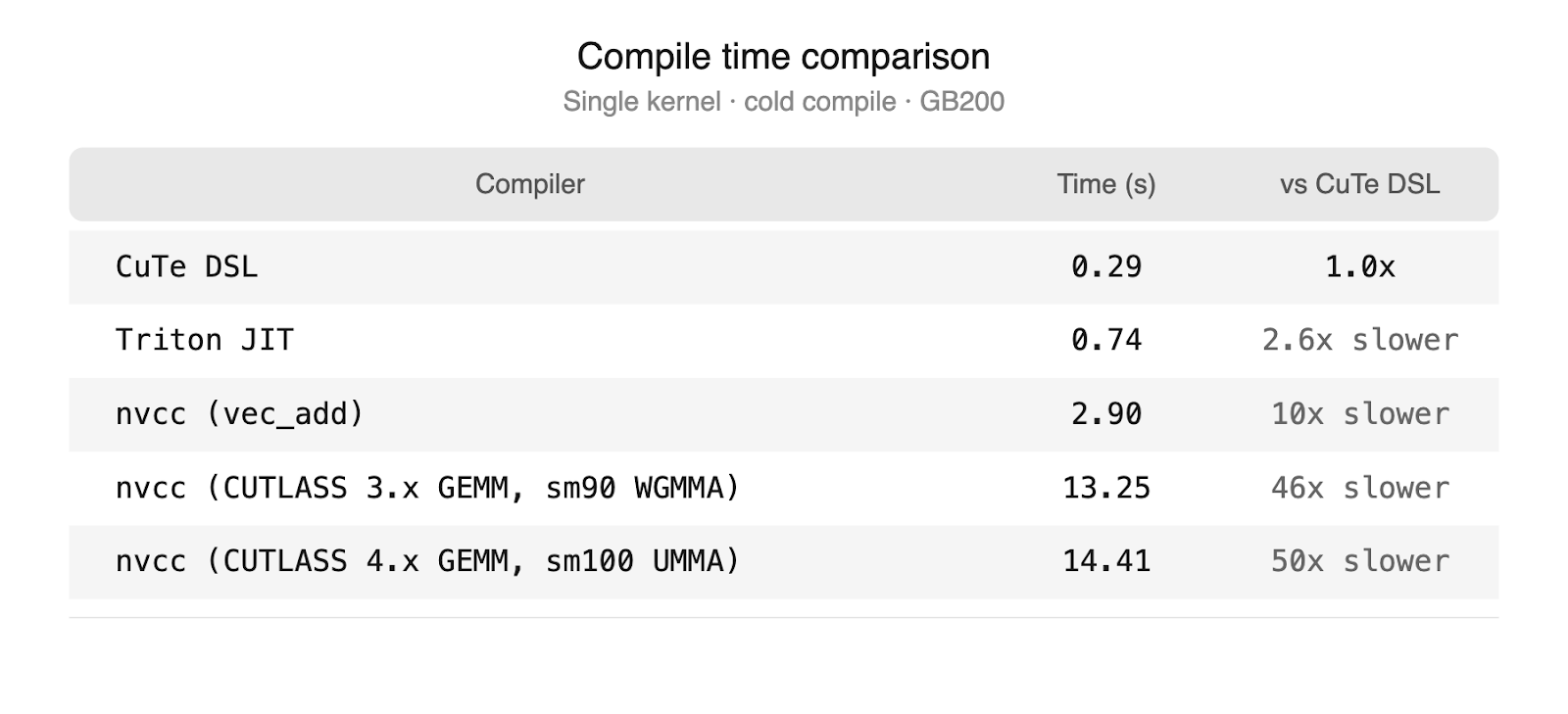
This analysis details how torch.compile achieved state-of-the-art performance for normalization operations (LayerNorm and RMSNorm) on NVIDIA H100 and B200 GPUs. Through targeted compiler optimizations, including MixOrderReduction and software pipelin...
#Hardware
#LLM On-Premise
#Fine-Tuning