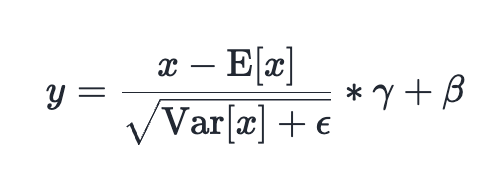Ottimizzazione delle Normalizzazioni con torch.compile: Performance SOTA su H100 e B200
Un'analisi approfondita rivela come torch.compile abbia raggiunto prestazioni all'avanguardia per le operazioni di normalizzazione (LayerNorm e RMSNorm) su GPU NVIDIA H100 e B200. Grazie a mirate ottimizzazioni del compilatore e all'introduzione di t...
#Hardware
#LLM On-Premise
#Fine-Tuning