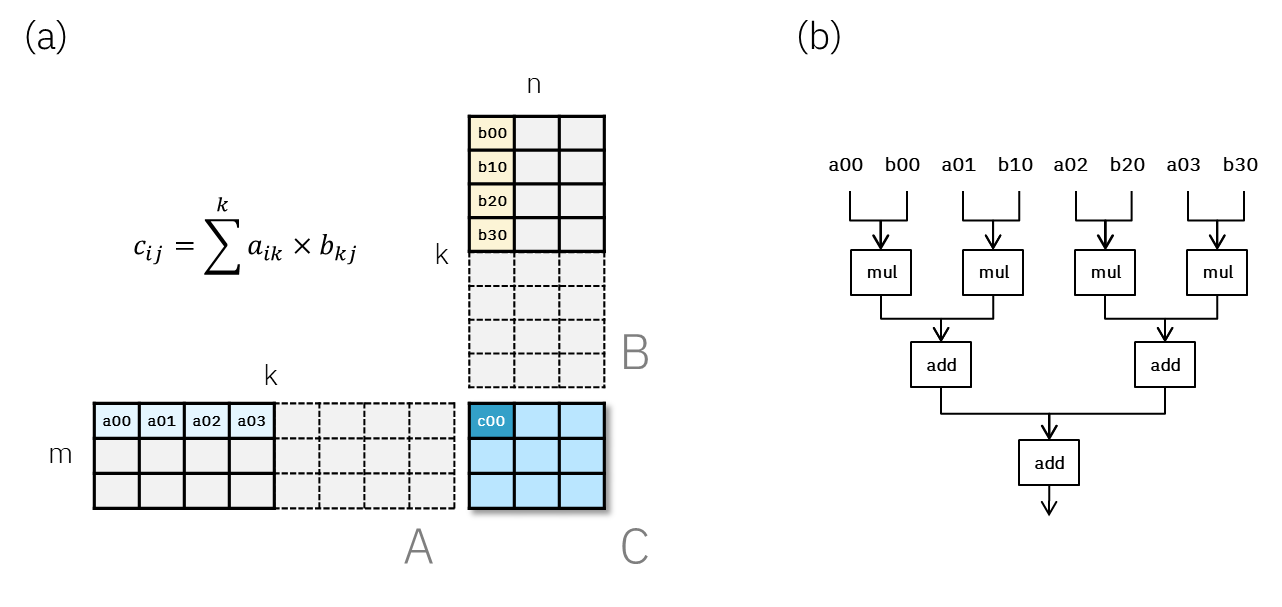
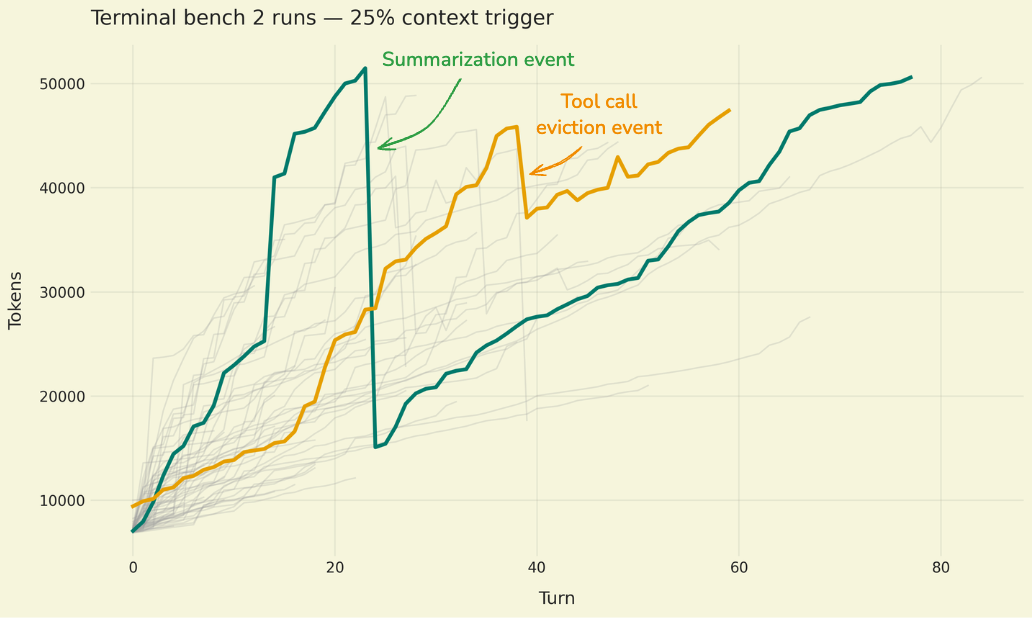
GLM-5 Incoming: Spotted in vLLM Pull Request
Hints of the upcoming GLM-5 language model have surfaced in a pull request related to vLLM, a framework for LLM inference. The news, initially shared on Reddit, suggests that the new model might soon be integrated and available to the open-source com...
#Hardware
#LLM On-Premise
#DevOps