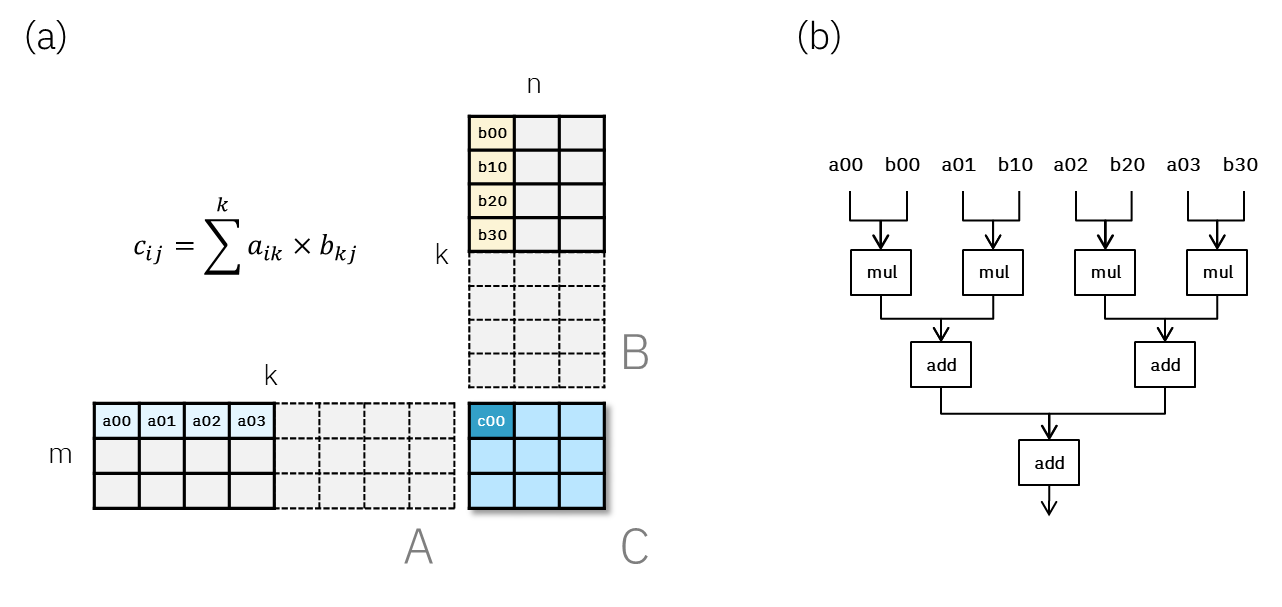
GLM-5 in Arrivo: Indizi nel codice di vLLM
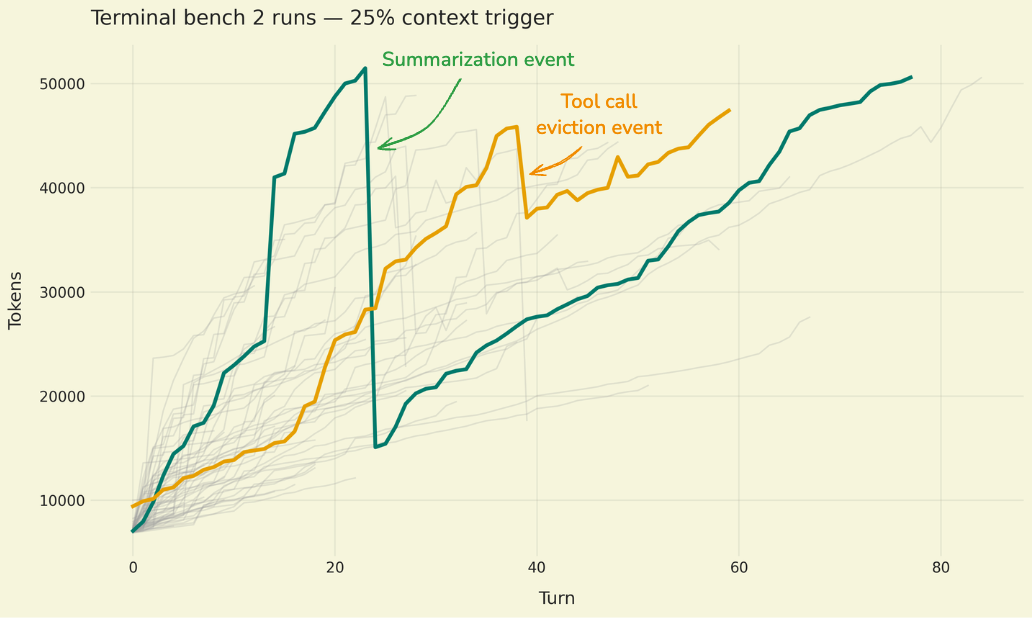
Indiscrezioni sul prossimo modello linguistico GLM-5 emergono da una pull request relativa a vLLM, un framework per l'inference di LLM. La notizia, diffusa inizialmente su Reddit, suggerisce che il nuovo modello potrebbe presto essere integrato e dis...
#Hardware
#LLM On-Premise
#DevOps