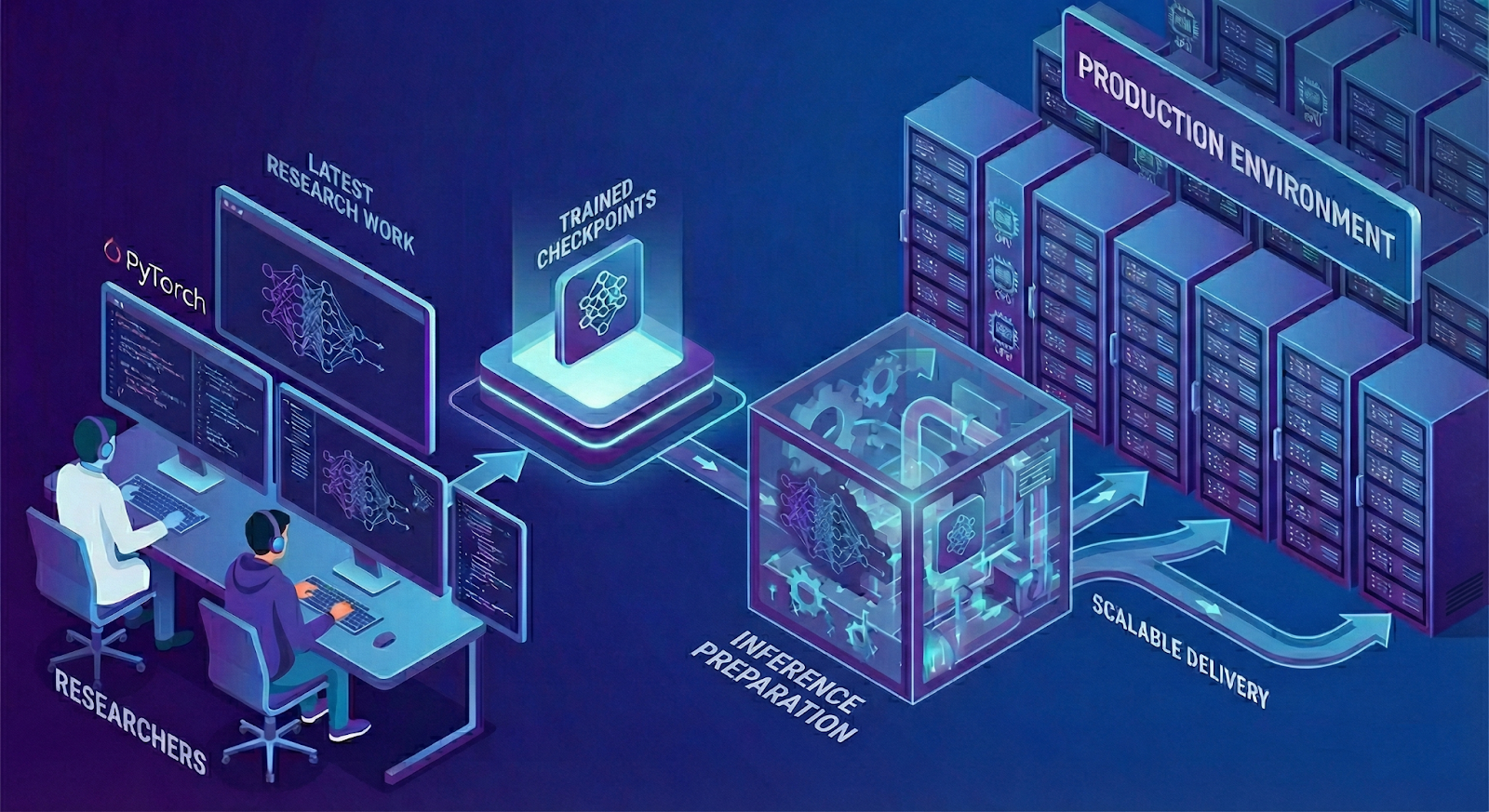
MWC 2026: How AI is reshaping devices, networks, and data policy
The Mobile World Congress 2026 will explore how artificial intelligence is radically transforming devices, network infrastructures, and data management regulations. The event will analyze the future implications of AI in various sectors, with a focus...
#LLM On-Premise
#DevOps




































































































.jpg)