Materiali Semiconduttori a Taiwan: Scenari Competitivi e Impatti sull'AI On-Premise
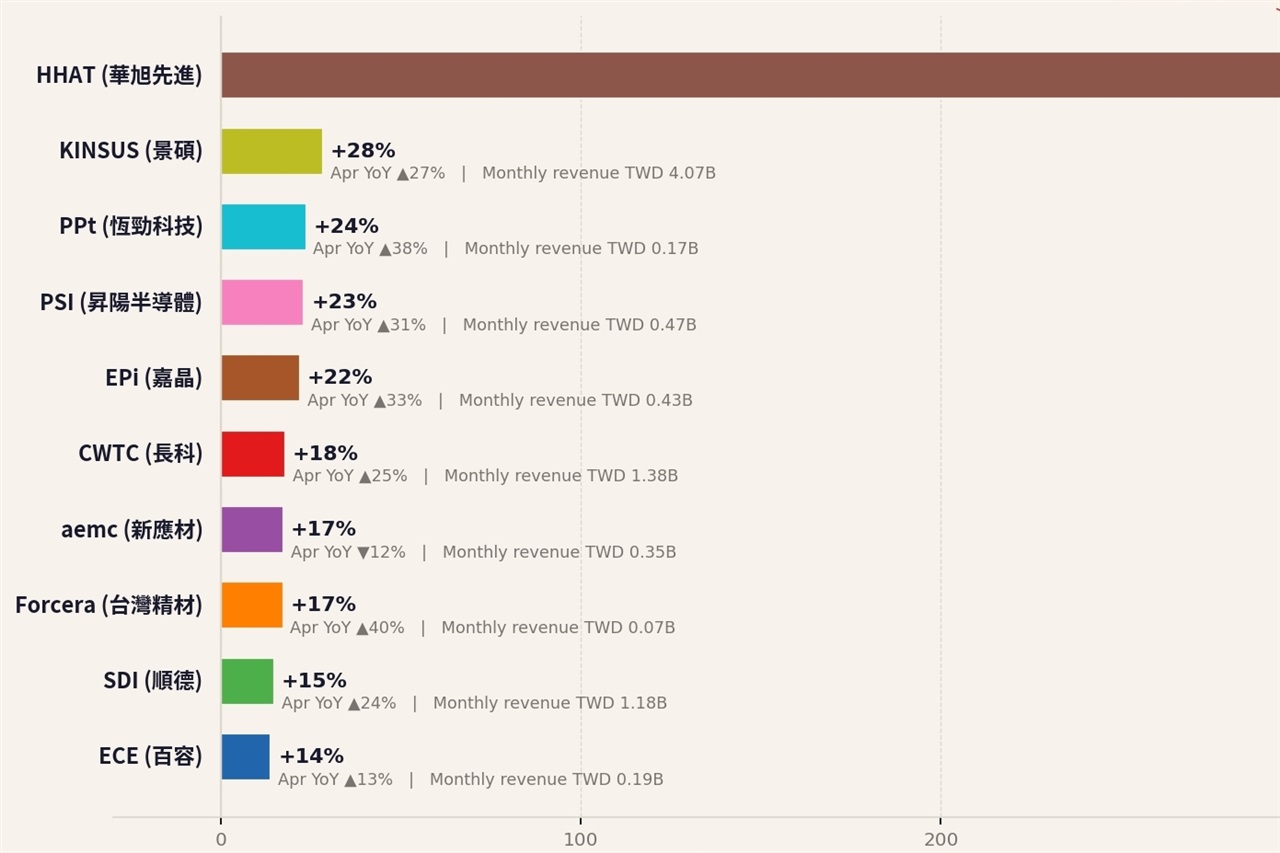
Un'analisi di Digitimes per aprile 2026 evidenzia una crescente polarizzazione nel settore dei materiali semiconduttori a Taiwan. Questa dinamica, caratterizzata da due 'corse' distinte, potrebbe influenzare significativamente la catena di approvvigi...
#Hardware
#LLM On-Premise
#Fine-Tuning