EAGLE3 Joins llama.cpp: New Prospects for Local LLM Inference
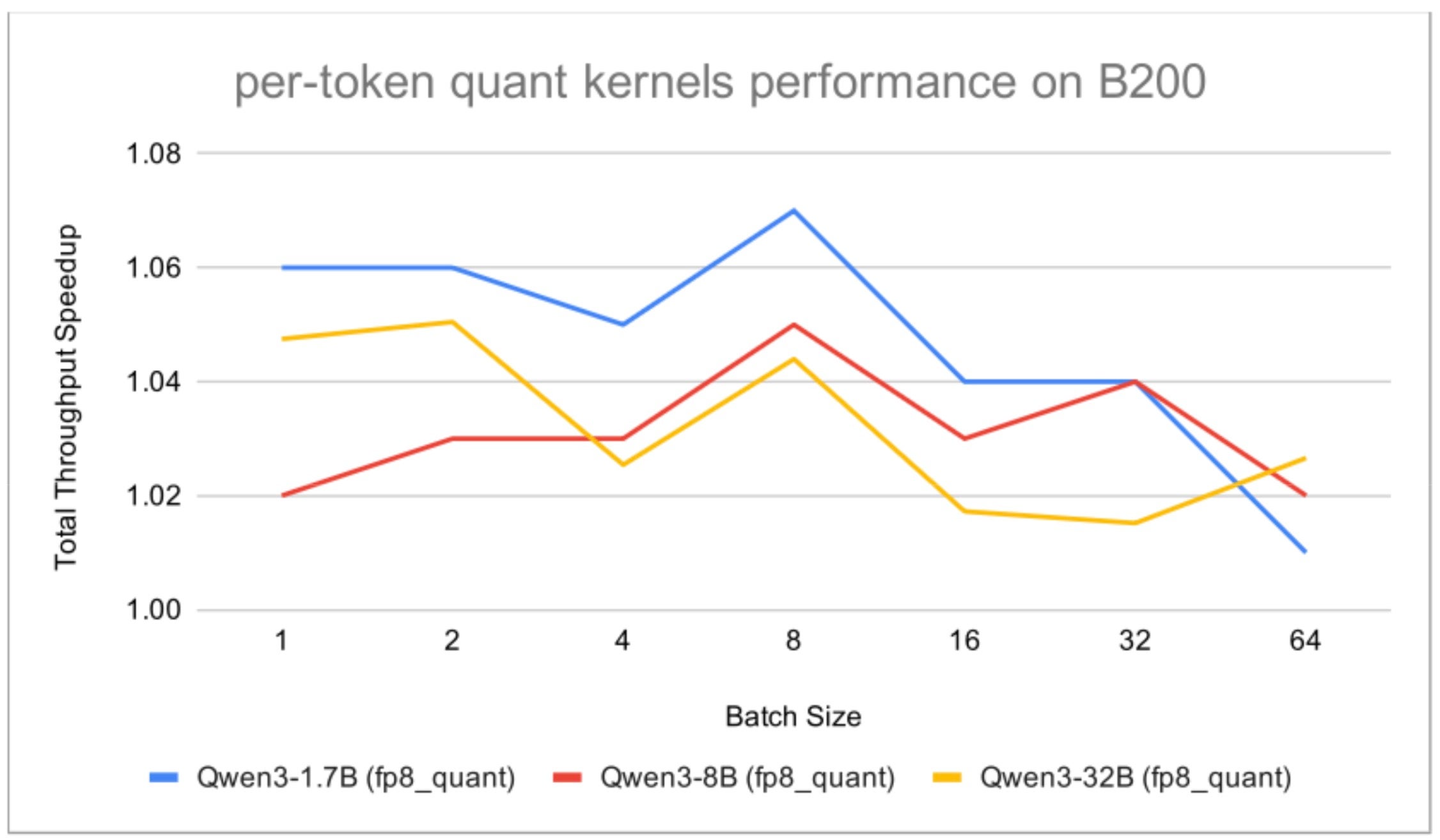
After six months of development, EAGLE3 has been integrated into the llama.cpp project, introducing an evolution in Large Language Model inference. This implementation improves efficiency compared to previous methods like MTP, allowing the helper mod...
#Hardware
#LLM On-Premise
#DevOps






























.jpg)






