Anthropic presenta Claude Design: l'IA che genera asset visivi e impatta i flussi di lavoro
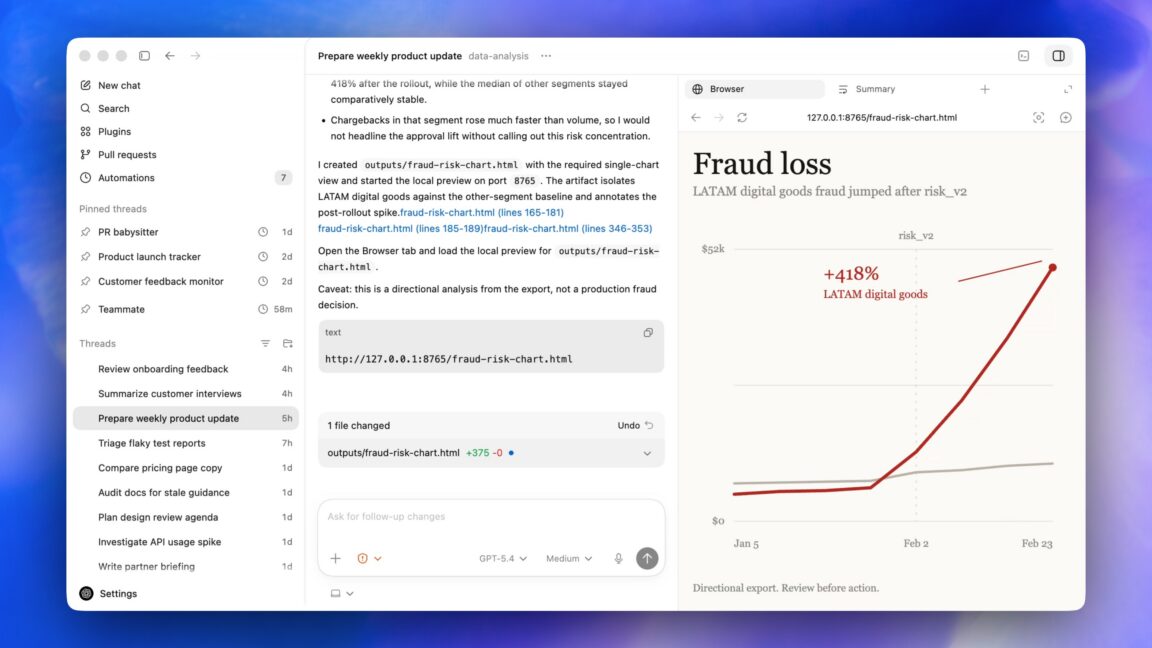
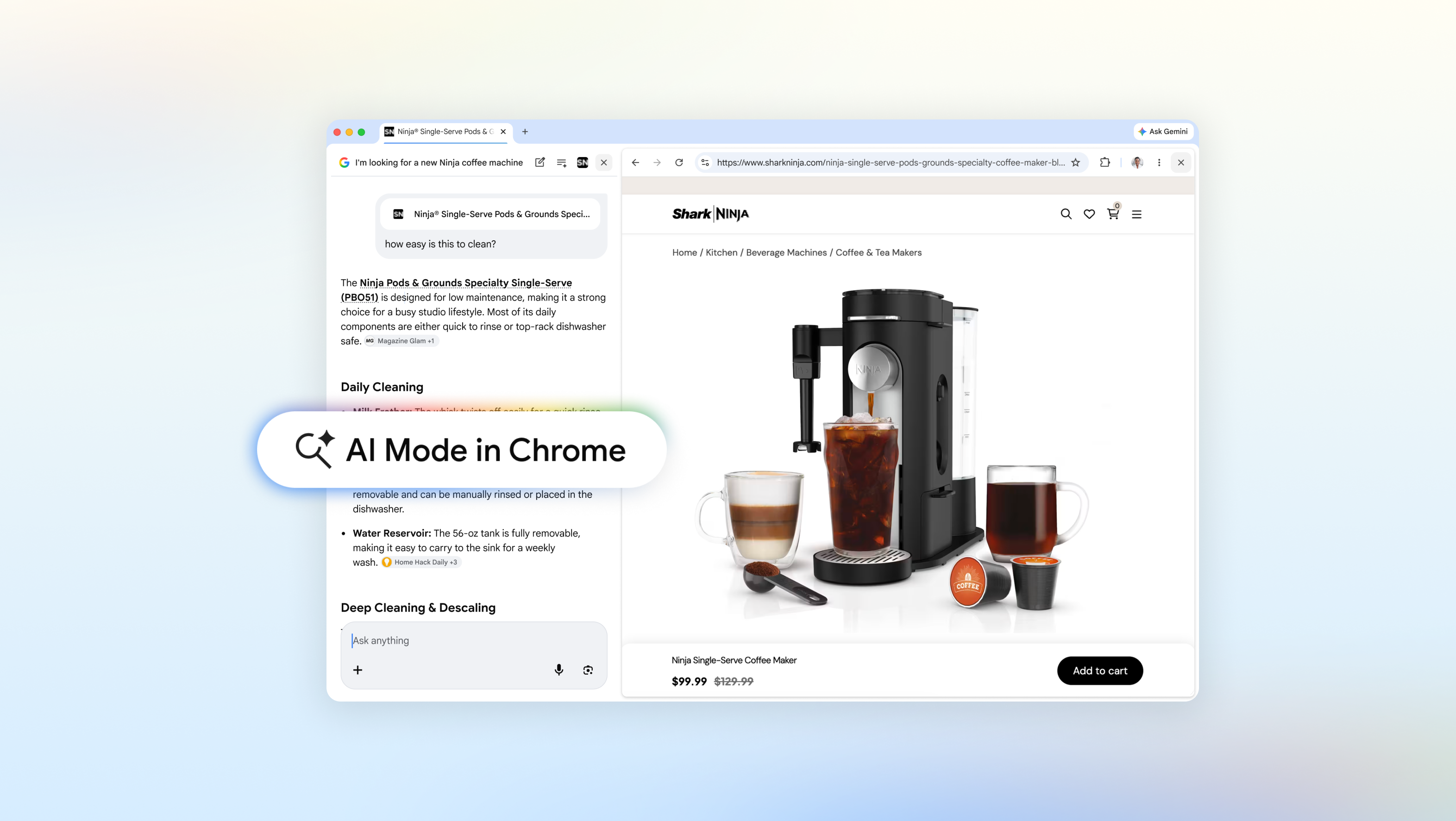
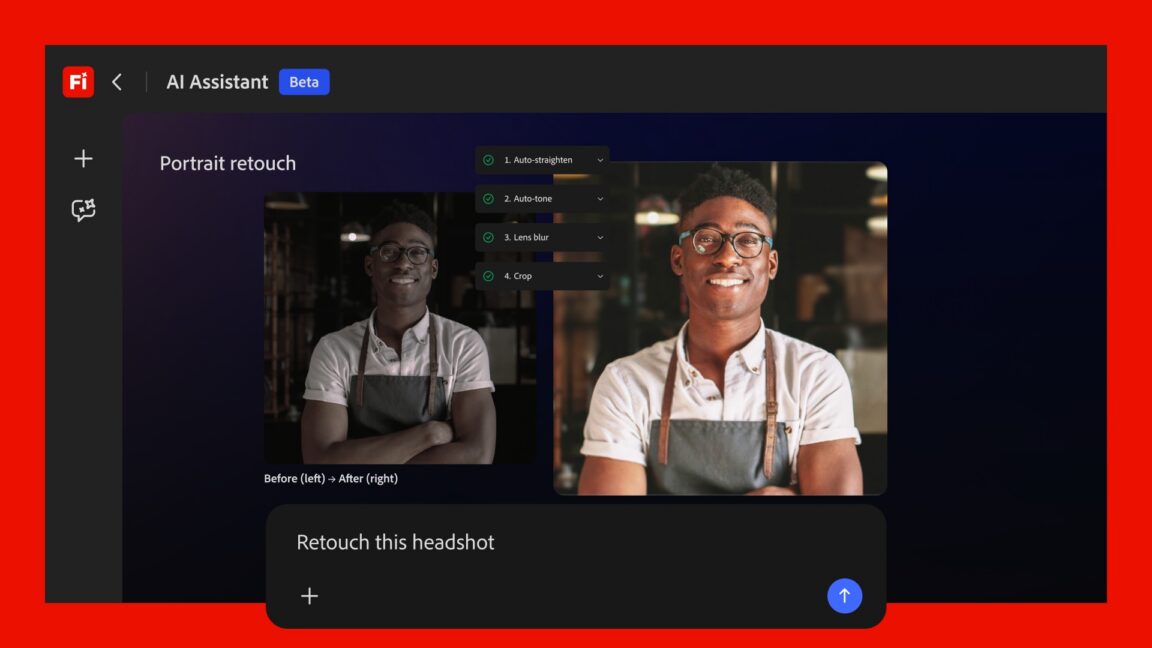
Anthropic ha introdotto Claude Design, un servizio in anteprima di ricerca che permette di creare asset visivi attraverso la conversazione con un modello di intelligenza artificiale. Questa novità, che segue il successo di Claude Code per la generazi...
#Hardware
#LLM On-Premise
#DevOps