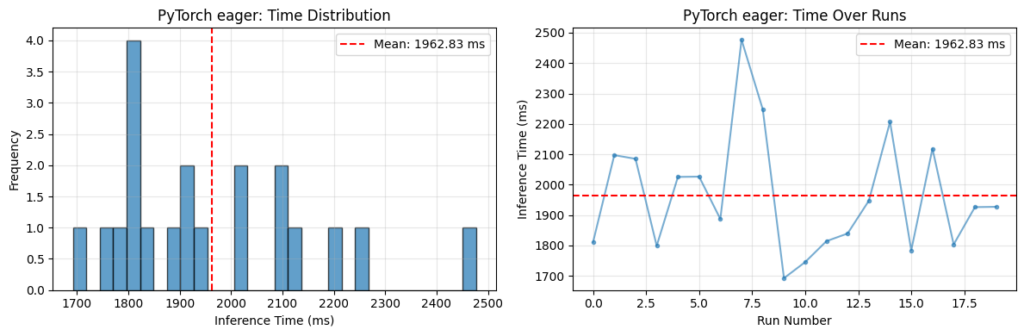
Llama.cpp, la guida all’ottimizzazione che mancava: un anno di esperimenti condensati
Dopo 12 mesi di test su inference locale, uno sviluppatore pubblica una guida completa per ottimizzare llama.cpp: gestione della VRAM, cache KV, modelli MoE, tuning della CPU e le trappole OOM più frequenti. Un riferimento pratico per chi sceglie il ...
#Hardware
#LLM On-Premise
#DevOps