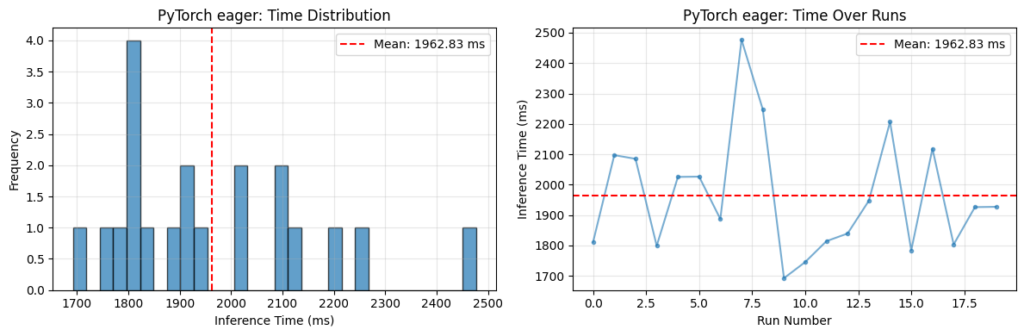
The Llama.cpp Optimization Guide We Needed: A Year of Experiments Distilled
After 12 months of testing local inference, a developer has published a comprehensive guide to llama.cpp optimization: VRAM fitting, KV cache, MoE models, CPU tuning, and the most common out-of-memory traps. A practical reference for those committed ...
#Hardware
#LLM On-Premise
#DevOps