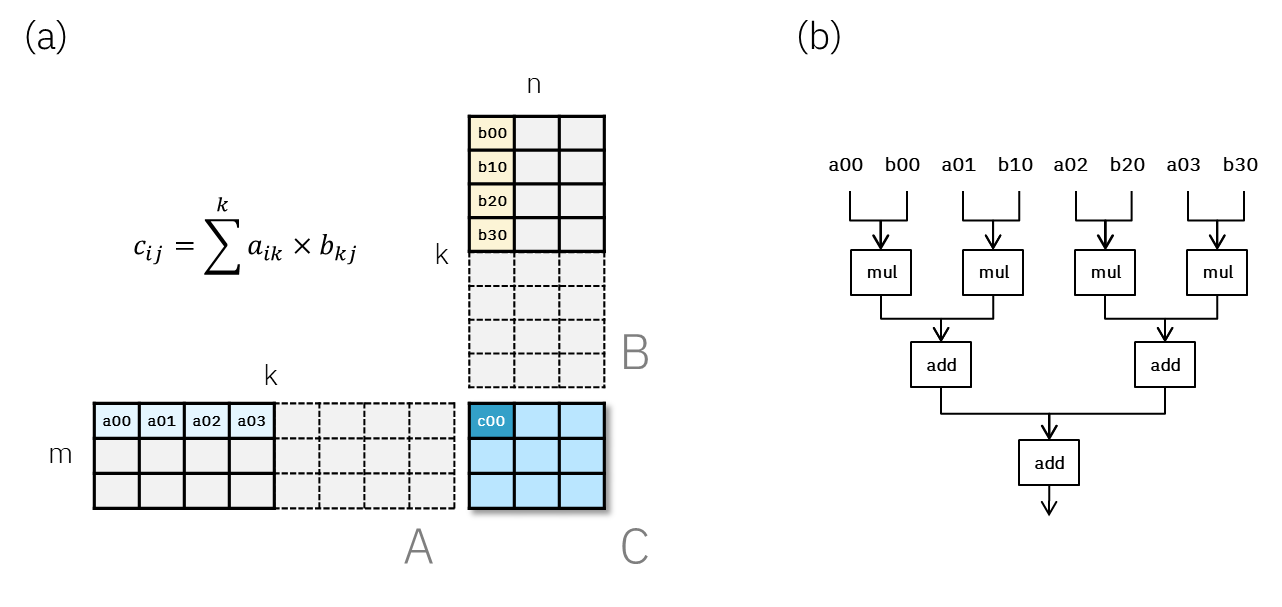
GPT-5: Contextual Analysis and Advanced Prompt Engineering
A new study explores the use of LLMs, specifically GPT-5, for analyzing the context of textual citations. The research focuses on prompt sensitivity, varying their structure to assess how they influence the model's interpretations. The goal is to und...