La Sfida dei Contesti Lunghi negli LLM
Il training dei Large Language Models (LLM) si sta orientando sempre più verso compiti che richiedono la gestione di contesti estremamente lunghi, dove il numero di token può superare le 100.000 unità. A queste scale, emergono frequentemente problemi di esaurimento della memoria (Out-Of-Memory, OOM), anche quando si incrementa il numero di dispositivi utilizzando tecniche di training convenzionali come ZeRO o FSDP. Per ovviare a queste problematiche, la Sequence Parallelism (SP), che consiste nel partizionare i token di input tra i vari dispositivi, rappresenta una tecnica di training parallelo sempre più adottata per abilitare il training su contesti estesi con un numero crescente di GPU.
Tuttavia, l'implementazione della Sequence Parallelism è notoriamente complessa. Richiede modifiche invasive al codice di librerie esistenti come DeepSpeed o HuggingFace. Queste modifiche spesso implicano il partizionamento dei contesti dei token di input e delle attivazioni intermedie, l'inserimento di collettivi di comunicazione e la sovrapposizione della comunicazione con il calcolo, operazioni che devono essere eseguite sia per il passaggio forward che per quello backward. Questo comporta che i ricercatori che desiderano sperimentare con capacità di contesto lungo debbano dedicare uno sforzo significativo all'ingegnerizzazione dello stack di sistema per abilitare tale funzionalità, ripetendo questo sforzo per diversi fornitori di hardware.
AutoSP: Una Soluzione Basata su Compilatore
Per superare questa complessità, è stato introdotto AutoSP, una soluzione completamente automatizzata basata su compilatore. AutoSP converte automaticamente il codice di training standard, facile da scrivere, in codice parallelo per multi-GPU, che utilizza in modo efficiente le GPU per il training su contesti di input più lunghi, integrandosi con strategie parallele esistenti come ZeRO. Questo elimina la necessità per gli sviluppatori di modificare ripetutamente le pipeline di training per i contesti lunghi.
Gli utenti possono ora semplicemente importare AutoSP e compilare modelli arbitrari utilizzando il backend di AutoSP, rendendo accessibile a tutti la potenza del training su contesti estesi. Inoltre, integrando questa tecnicia nel compilatore, l'approccio è performance-portable: una Sequence Parallelism altamente performante può essere realizzata su hardware diversi. La filosofia di design chiave di AutoSP è la semplicità nell'astrarre la maggior parte della complessità della programmazione multi-GPU dagli utenti, implementando AutoSP all'interno di DeepCompile, un ecosistema di compilatori in DeepSpeed.
Dettagli Tecnici e Valutazione delle Performance
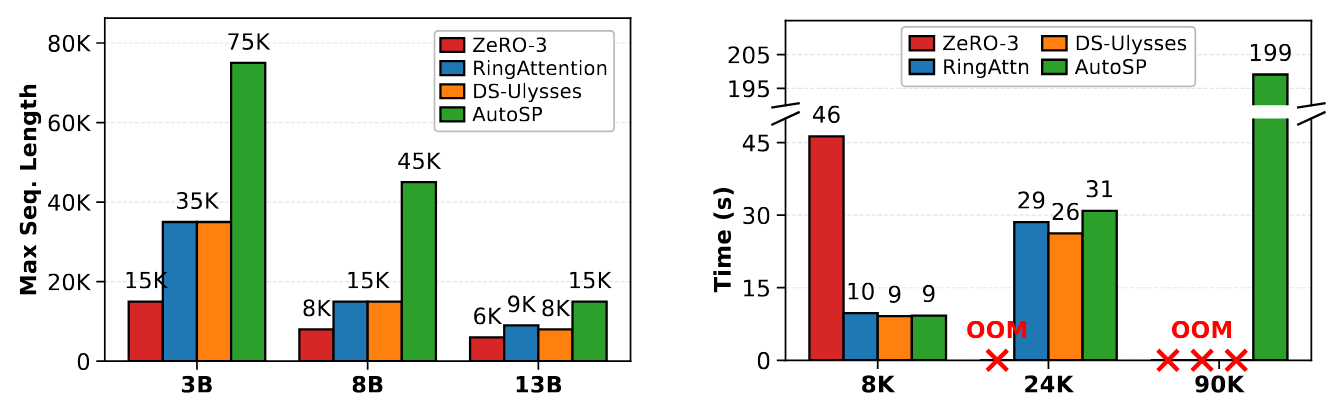
AutoSP trasforma il codice utente per abilitare il training su contesti più lunghi. La strategia specifica di Sequence Parallelism in cui AutoSP converte il codice è DeepSpeed-Ulysses. Questa scelta è motivata dal fatto che il suo overhead di comunicazione rimane costante all'aumentare del numero di GPU su topologie di rete NVLink o reti fat-tree. È importante notare, tuttavia, che DeepSpeed-Ulysses consente di scalare la dimensione della SP solo fino al numero di head in un modello (ad esempio, 32 nei modelli da 7-8 miliardi di parametri).
AutoSP applica anche una strategia personalizzata di Activation Checkpointing (AC) pensata per la modellazione di contesti lunghi, denominata Sequence-aware AC (SAC). Questa tecnica rilascia le attivazioni intermedie di operatori a basso costo computazionale, ricalcolandole nel passaggio backward quando necessario per i gradienti. Sebbene PyTorch 2.0 introduca una formulazione AC automatizzata basata su max-flow min-cut, questa è stata ritenuta eccessivamente conservativa per la modellazione di contesti lunghi. SAC, invece, sfrutta le dinamiche FLOP uniche dei contesti lunghi. Quando attivata (impostazione predefinita in AutoSP), questa strategia riduce marginalmente il throughput di training, ma senza di essa, il training su contesti più lunghi risulterebbe impraticabile. Gli utenti possono scegliere di attivarla solo per le configurazioni che vanno in OOM.
Per dimostrare la validità di AutoSP, le sue performance sono state valutate su modelli di diverse dimensioni utilizzando GPU NVIDIA. I benchmark sono stati eseguiti su modelli Llama 3.1 su un nodo con 8 GPU NVIDIA A100-80GB SXM, utilizzando PyTorch 2.7 e CUDA 12.8. I risultati sono stati confrontati con baselines scritte a mano e compilate con torch.compile, tra cui RingFlashAttention, DeepSpeed-Ulysses e ZeRO-3. I test hanno dimostrato che AutoSP non solo aumenta la lunghezza massima della sequenza addestrabile a parità di risorse, ma lo fa con un costo minimo in termini di performance di runtime.
Implicazioni e Limiti per i Deployment On-Premise
Per CTO, DevOps lead e architetti infrastrutturali che valutano alternative self-hosted per carichi di lavoro AI/LLM, AutoSP rappresenta un'innovazione significativa. La capacità di semplificare il training di LLM con contesti estesi su infrastrutture multi-GPU esistenti è cruciale per ottimizzare l'utilizzo delle risorse e contenere il Total Cost of Ownership (TCO). In ambienti on-premise, dove l'hardware è un investimento fisso, massimizzare l'efficienza di ogni GPU A100-80GB SXM diventa un fattore determinante per la sostenibilità e la scalabilità dei progetti AI. Per chi valuta deployment on-premise, soluzioni come AutoSP offrono un percorso per ottimizzare l'uso delle risorse hardware esistenti, un fattore cruciale nella gestione del TCO. AI-RADAR offre framework analitici su /llm-onpremise per valutare questi trade-off.
Nonostante i suoi vantaggi, AutoSP presenta alcune limitazioni. In primo luogo, richiede che l'utente compili il transformer come un singolo artefatto compilabile. Questo significa che gli utenti PyTorch che compilano molte funzioni individualmente e le uniscono in un unico modello non possono utilizzare AutoSP, poiché il compilatore necessita di vedere l'intero modello per partizionare correttamente le sequenze di input e propagare le informazioni attraverso il grafo completo. In secondo luogo, AutoSP non consente interruzioni del grafo negli artefatti compilabili, il che complica l'analisi e la propagazione delle informazioni. L'estensione di AutoSP per essere resiliente alle interruzioni del grafo è un'area di ricerca futura. Nonostante queste limitazioni, la sua integrazione con DeepSpeed democratizza l'accesso al training di LLM su contesti lunghi, rendendolo più accessibile e gestibile per le organizzazioni che puntano a mantenere il controllo e la sovranità dei propri dati.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!