Accelerare l'Ottimizzazione dei Kernel con i Large Language Models
L'ottimizzazione delle prestazioni dei kernel di machine learning è un fattore critico per l'efficienza e la scalabilità dei carichi di lavoro AI. Helion, il linguaggio specifico di dominio (DSL) di PyTorch progettato per la creazione di kernel ML portabili e performanti, si affida pesantemente all'autotuning per raggiungere le massime prestazioni sull'hardware target. Tuttavia, il metodo di autotuning predefinito, basato sull'ottimizzazione bayesiana senza verosimiglianza (LFBO), sebbene efficace, richiede centinaia di cicli di compilazione e benchmark per ogni kernel, rallentando significativamente il processo di sviluppo e il deployment in produzione.
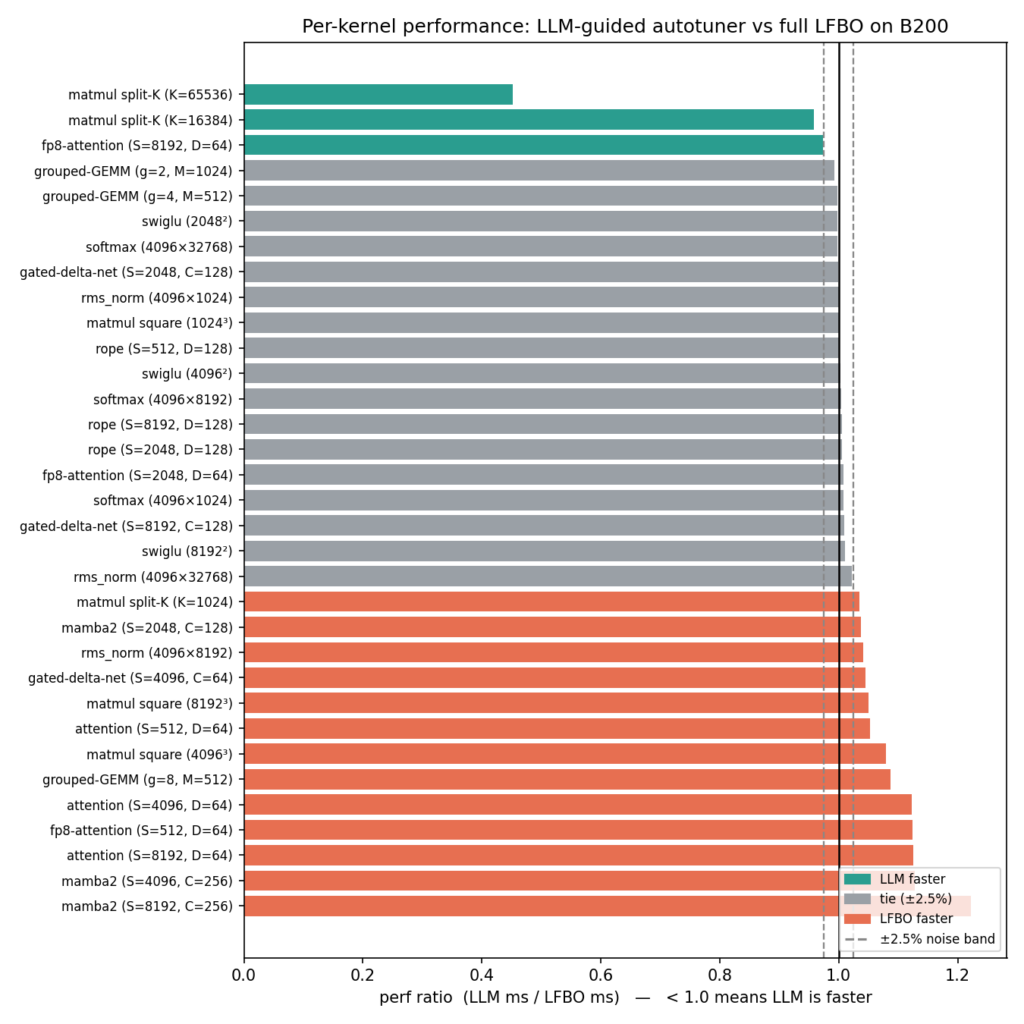
Per affrontare questa sfida, è stato introdotto un nuovo autotuner guidato da Large Language Models (LLM). Questa innovazione mira a ridurre drasticamente i tempi di sintonizzazione senza compromettere la qualità delle prestazioni. I test condotti su GPU NVIDIA B200, su un set di 11 kernel e diverse configurazioni, hanno dimostrato che l'approccio basato su LLM può eguagliare le prestazioni dei kernel ottimizzati con LFBO, ma con un'efficienza notevolmente superiore.
Il Meccanismo dell'Autotuning Guidato da LLM
L'autotuner guidato da LLM opera attraverso cicli iterativi di prompt e feedback. Inizialmente, Helion fornisce all'LLM il codice del kernel, i dettagli del carico di lavoro (come le dimensioni dei tensori di input e le specifiche hardware della GPU, ad esempio NVIDIA B200) e lo spazio di configurazione dei parametri ottimizzabili (come tile sizes, block sizes, num_warps, num_stages). L'LLM, agendo come un "esperto di autotuning di kernel GPU", propone un set di configurazioni candidate in formato JSON.
Una volta ricevute le configurazioni, Helion le compila e le sottopone a benchmark, identificando quelle più performanti. Nelle fasi successive di raffinamento, l'LLM riceve un feedback dettagliato che include le configurazioni di maggior successo, le loro metriche di performance e un'analisi dei pattern efficaci o fallimentari. Questo ciclo di feedback permette all'LLM di mutare le configurazioni esistenti e proporne di nuove, concentrandosi sulle aree più promettenti e scartando quelle meno efficaci. Il processo si conclude anticipatamente se non si rilevano miglioramenti significativi.
Efficienza e Performance: I Risultati sul Campo
I benchmark comparativi tra l'autotuner guidato da LLM e il metodo LFBO hanno evidenziato un notevole guadagno in efficienza. L'approccio basato su LLM ha permesso di esplorare circa 10 volte meno configurazioni (circa 55 contro 546 per kernel) e ha ridotto il tempo complessivo di sintonizzazione di circa 6.7 volte (da 261 a 39 secondi), misurato su un host con 384 thread. Questo significa che l'LLM raggiunge un livello di performance paragonabile a LFBO (con un rapporto geomean di 1.009X) in una frazione del tempo e delle risorse computazionali.
Per i pochi casi in cui l'LLM mostrava un calo di performance superiore al 5% rispetto a LFBO, è stata sviluppata una strategia ibrida. Questa prevede una fase iniziale di "seeding" da parte dell'LLM, seguita da un raffinamento tramite LFBO. Questo approccio ibrido ha permesso di colmare il divario prestazionale nella maggior parte dei casi, mantenendo un'efficienza superiore: è risultato circa 3 volte più economico rispetto a una ricerca LFBO completa. È interessante notare come le prestazioni siano state ampiamente indipendenti dal modello LLM utilizzato, con Opus-4.8, gpt-5.5 e Sonnet-4.6 che hanno mostrato risultati molto simili.
Implicazioni per il Deployment On-Premise e le Prospettive Future
L'introduzione di un autotuner guidato da LLM ha implicazioni significative per i team di sviluppo e per le decisioni di deployment, specialmente in contesti on-premise. La drastica riduzione dei tempi di sintonizzazione si traduce direttamente in una maggiore velocità di sviluppo (developer velocity) e in un più rapido rilascio (deployment) in produzione. Per le infrastrutture self-hosted, dove il Total Cost of Ownership (TCO) e l'ottimizzazione delle risorse hardware sono prioritari, la capacità di ottenere kernel altamente performanti in tempi brevi è un vantaggio competitivo cruciale. Questo permette di massimizzare il throughput e minimizzare la latenza su hardware specifico come le GPU NVIDIA B200, senza dover sostenere costi operativi elevati per cicli di ottimizzazione prolungati.
AI-RADAR sottolinea come la scelta tra deployment on-premise e cloud implichi una valutazione attenta di questi trade-off. Per chi valuta deployment on-premise, esistono framework analitici su /llm-onpremise per approfondire questi aspetti. In futuro, i ricercatori intendono migliorare ulteriormente le euristiche per potenziare l'efficacia sia dell'autotuner guidato da LLM che della strategia ibrida, promettendo ulteriori avanzamenti nell'ottimizzazione dei carichi di lavoro AI.









💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!