Accelerating Kernel Optimization with Large Language Models
Optimizing the performance of machine learning kernels is a critical factor for the efficiency and scalability of AI workloads. Helion, PyTorch's domain-specific language (DSL) designed for authoring performant and portable ML kernels, heavily relies on autotuning to achieve peak performance on target hardware. However, the default autotuning method, based on Likelihood-Free Bayesian Optimization (LFBO), while effective, requires hundreds of compile-and-benchmark cycles per kernel, significantly slowing down the development process and production deployment.
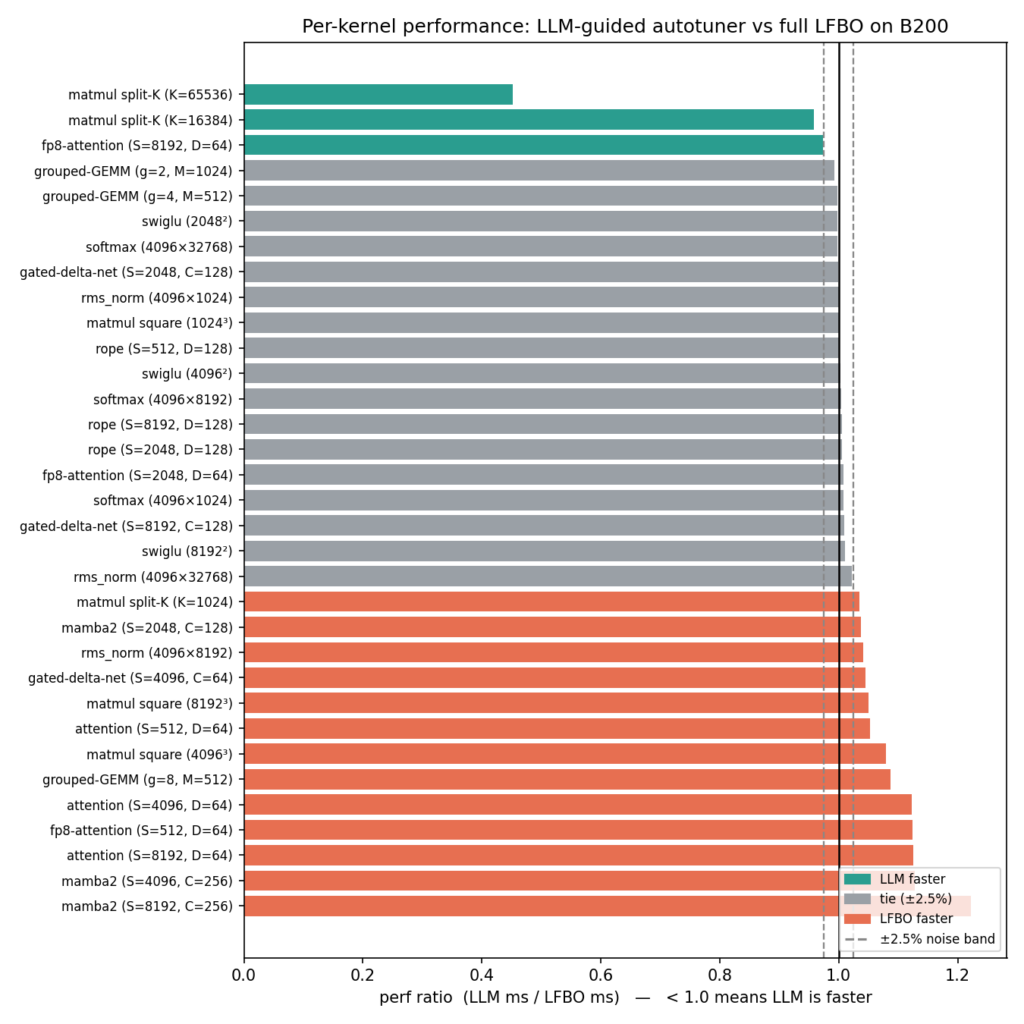
To address this challenge, a new autotuner guided by Large Language Models (LLMs) has been introduced. This innovation aims to drastically reduce tuning times without compromising performance quality. Tests conducted on NVIDIA B200 GPUs, across a set of 11 kernels and various configurations, have shown that the LLM-based approach can match the performance of LFBO-optimized kernels, but with significantly higher efficiency.
The Mechanism of LLM-Guided Autotuning
The LLM-guided autotuner operates through iterative cycles of prompts and feedback. Initially, Helion provides the LLM with the kernel code, workload details (such as input tensor shapes and GPU hardware specifications, e.g., NVIDIA B200), and the configuration space for tunable parameters (like tile sizes, block sizes, num_warps, num_stages). The LLM, acting as an "expert GPU kernel autotuner," proposes a set of candidate configurations in JSON format.
Once the configurations are received, Helion compiles and benchmarks them, identifying the top-performing ones. In subsequent refinement rounds, the LLM receives detailed feedback including the most successful configurations, their performance metrics, and an analysis of successful or failed patterns. This feedback loop allows the LLM to mutate existing configurations and propose new ones, focusing on the most promising areas and discarding less effective ones. The process terminates early if no significant performance gains are detected.
Efficiency and Performance: Field Results
Comparative benchmarks between the LLM-guided autotuner and the LFBO method have highlighted a significant gain in efficiency. The LLM-based approach allowed for exploring approximately 10 times fewer configurations (around 55 versus 546 per kernel) and reduced the overall tuning time by approximately 6.7 times (from 261 to 39 seconds), measured on a 384-thread host. This means that the LLM achieves a performance level comparable to LFBO (with a geomean ratio of 1.009X) in a fraction of the time and computational resources.
For the few cases where the LLM showed a performance drop greater than 5% compared to LFBO, a hybrid strategy was developed. This involves an initial "seeding" phase by the LLM, followed by refinement using LFBO. This hybrid approach successfully closed the performance gap in most cases, while maintaining superior efficiency: it proved to be approximately 3 times cheaper than a full LFBO search. Interestingly, performance was largely independent of the specific LLM model used, with Opus-4.8, gpt-5.5, and Sonnet-4.6 showing very similar results.
Implications for On-Premise Deployment and Future Prospects
The introduction of an LLM-guided autotuner has significant implications for development teams and deployment decisions, especially in on-premise contexts. The drastic reduction in tuning times directly translates into increased developer velocity and faster production deployment. For self-hosted infrastructures, where Total Cost of Ownership (TCO) and hardware resource optimization are priorities, the ability to obtain high-performing kernels in a short time is a crucial competitive advantage. This allows for maximizing throughput and minimizing latency on specific hardware like NVIDIA B200 GPUs, without incurring high operational costs for prolonged optimization cycles.
AI-RADAR emphasizes that the choice between on-premise and cloud deployment involves a careful evaluation of these trade-offs. For those considering on-premise deployments, analytical frameworks are available at /llm-onpremise to delve deeper into these aspects. Moving forward, researchers plan to further enhance heuristics to boost the effectiveness of both the LLM-guided and hybrid autotuners, promising further advancements in AI workload optimization.









💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!