DeepSpeed, Microsoft's deep learning library, introduces two significant updates focused on optimizing the training of multimodal models and reducing memory consumption.
PyTorch-Identical Backward API
The first update concerns a backward API identical to that of PyTorch. This new API simplifies the writing of training loops for multimodal models, which often combine vision encoders and LLMs, enabling sophisticated parallelism schemes with cleaner code. DeepSpeed transparently manages performance optimizations. One example is the enablement of disaggregated hybrid parallelism, which led to a 30% improvement in training speed for multimodal AI models.
DeepSpeed's original backward API required the use of model_engine.backward(loss) instead of PyTorch's usual loss.backward(), limiting flexibility. The new API allows combining multiple models, defining separate loss functions, and handling non-scalar tensors with custom gradients, while maintaining DeepSpeed optimizations such as ZeRO and offloading.
Low-Precision Training to Reduce Memory Usage
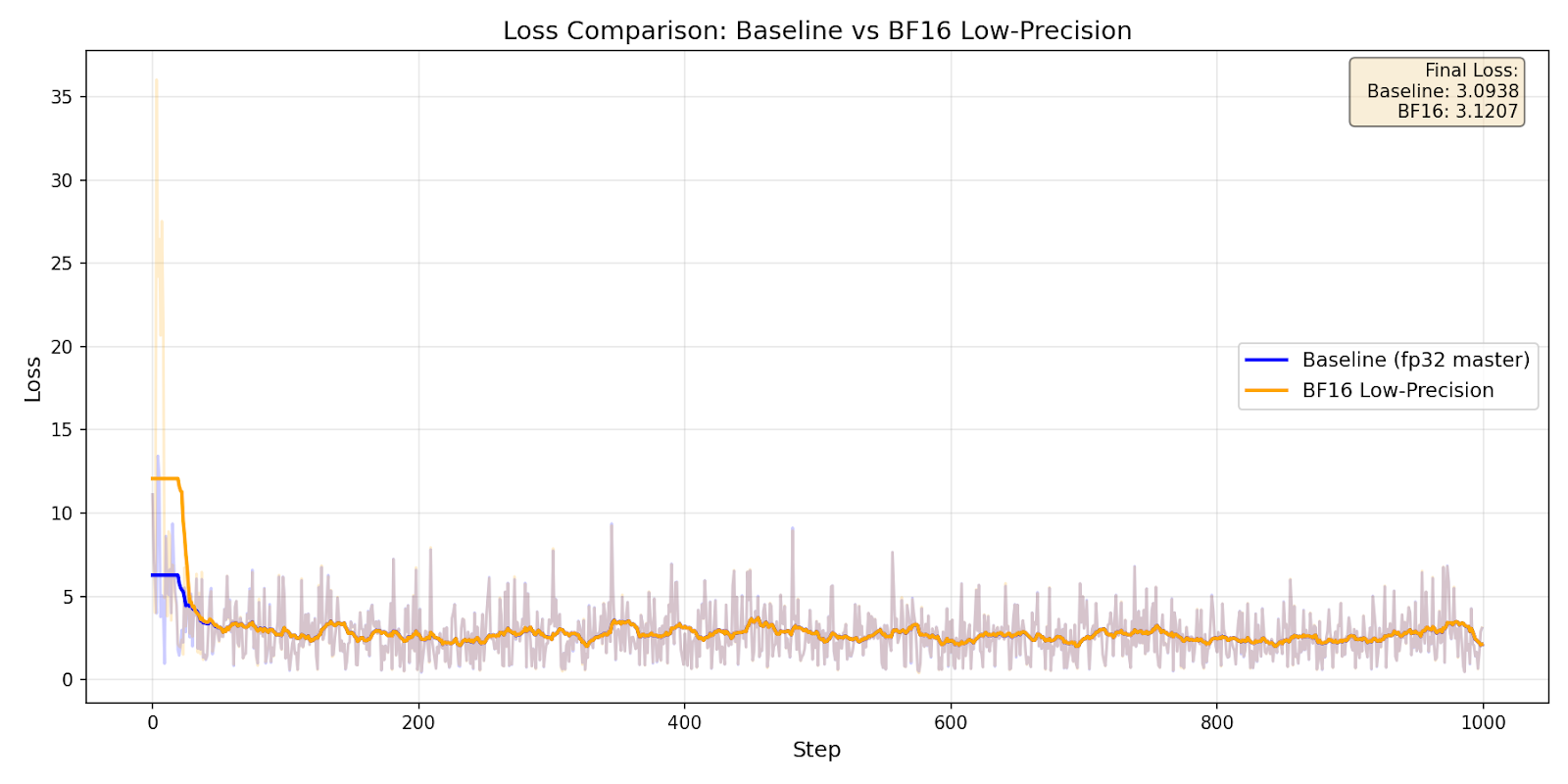
The second update introduces an option to keep all model states (parameters, gradients, and optimizer states) in low precision, such as BF16 or FP16. This drastically reduces the memory footprint, allowing researchers to fine-tune larger models on hardware with limited resources. Integration with torch.autocast ensures numerical stability during training.
A test showed a 40% reduction in peak memory while maintaining numerical stability. The results show that low-precision training with BF16 maintains comparable convergence to training with FP32, but with significant memory savings.









💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!