La gestione del contesto è diventata essenziale per gli agenti AI man mano che la lunghezza dei compiti affrontabili aumenta, al fine di prevenire la perdita di contesto e gestire le limitazioni di memoria degli LLM.
Il Deep Agents SDK di LangChain fornisce un framework open source per sviluppare agenti capaci di pianificare, generare sotto-agenti e interagire con un filesystem per eseguire compiti complessi e di lunga durata. Poiché questi compiti possono superare la finestra di contesto dei modelli, l'SDK implementa funzionalità per la compressione del contesto.
Tecniche di compressione del contesto
La compressione del contesto si riferisce a tecniche che riducono il volume di informazioni nella memoria di lavoro di un agente, preservando i dettagli rilevanti per il completamento del compito. Ciò può includere la summarization di interazioni precedenti, il filtraggio di informazioni obsolete o la decisione strategica su cosa conservare e cosa scartare.
Deep Agents implementa un'astrazione del filesystem che consente agli agenti di eseguire operazioni come elencare, leggere e scrivere file, nonché ricercare, confrontare pattern ed eseguire file. Gli agenti utilizzano il filesystem per cercare e recuperare contenuti scaricati quando necessario.
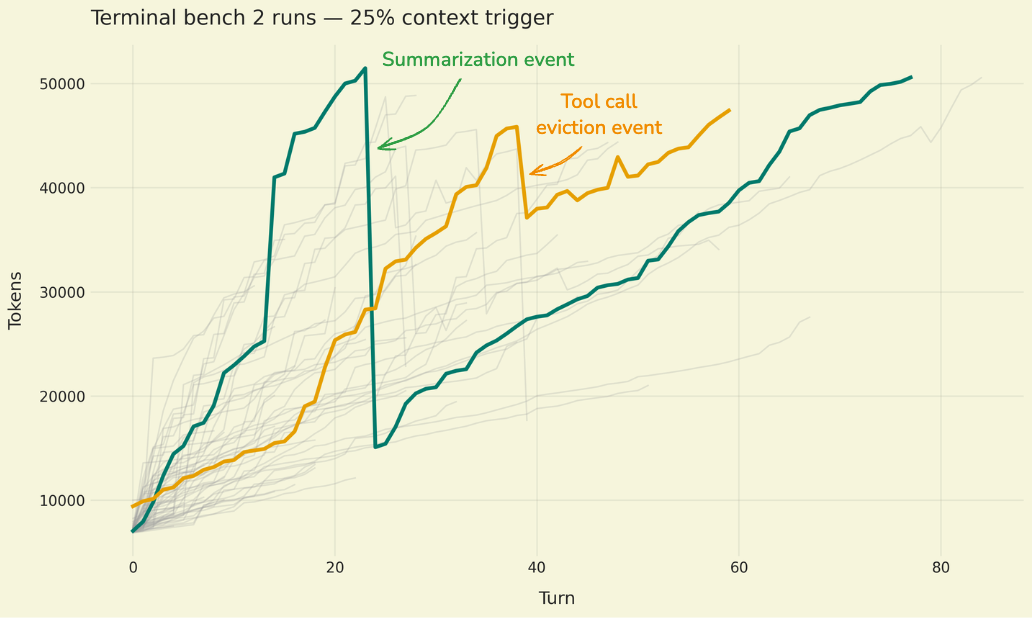
Deep Agents implementa tre tecniche principali di compressione, attivate a frequenze diverse:
- Offload di risultati di tool di grandi dimensioni: Le risposte di tool di grandi dimensioni vengono scaricate sul filesystem.
- Offload di input di tool di grandi dimensioni: Quando la dimensione del contesto supera una soglia, i vecchi argomenti di scrittura/modifica delle chiamate ai tool vengono scaricati sul filesystem.
- Summarization: Quando la dimensione del contesto supera la soglia e non è più disponibile alcun contesto per l'offload, viene eseguita una fase di summarization per comprimere la cronologia dei messaggi.
Per gestire i limiti del contesto, il Deep Agents SDK attiva questi passaggi di compressione a frazioni di soglia della dimensione della finestra di contesto del modello.
Offload di risultati di tool di grandi dimensioni
Le risposte delle chiamate ai tool (ad esempio, il risultato della lettura di un file di grandi dimensioni o di una chiamata API) possono superare la finestra di contesto di un modello. Quando Deep Agents rileva una risposta di tool che supera i 20.000 token, scarica la risposta sul filesystem e la sostituisce con un riferimento al percorso del file e un'anteprima delle prime 10 righe. Gli agenti possono quindi rileggere o cercare il contenuto secondo necessità.
Offload di input di tool di grandi dimensioni
Le operazioni di scrittura e modifica di file lasciano indietro chiamate ai tool contenenti il contenuto completo del file nella cronologia della conversazione dell'agente. Poiché questo contenuto è già salvato nel filesystem, è spesso ridondante. Quando il contesto della sessione supera l'85% della finestra disponibile del modello, Deep Agents tronca le chiamate ai tool più vecchie, sostituendole con un puntatore al file sul disco e riducendo la dimensione del contesto attivo.
Summarization
Quando l'offload non produce più spazio sufficiente, Deep Agents ricorre alla summarization. Questo processo ha due componenti:
- Summarization in-context: un LLM genera una summarization strutturata della conversazione, inclusi l'intento della sessione, gli artefatti creati e i passaggi successivi, che sostituisce la cronologia completa della conversazione nella memoria di lavoro dell'agente.
- Conservazione del filesystem: i messaggi completi e originali della conversazione vengono scritti sul filesystem come record canonico.
Questo duplice approccio garantisce che l'agente mantenga la consapevolezza dei suoi obiettivi e dei progressi (tramite la summarization) preservando al contempo la capacità di recuperare dettagli specifici quando necessario (tramite la ricerca nel filesystem).
Valutazione delle strategie di compressione
Quando si valutano le proprie strategie di compressione del contesto, è importante:
- Iniziare con benchmark reali, quindi stress-testare le singole funzionalità.
- Testare la recuperabilità.
- Monitorare la deriva degli obiettivi.
Tutte le funzionalità dell'agente Deep Agents sono open source.









💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!