L'Ottimizzazione dei Kernel per l'Inference LLM
L'efficienza nell'inference dei Large Language Models (LLM) è un fattore critico per le aziende che valutano deployment on-premise, dove il Total Cost of Ownership (TCO) e la sovranità dei dati sono priorità assolute. In questo contesto, l'ottimizzazione a livello di kernel GPU può generare benefici sostanziali in termini di throughput e latenza. Un recente lavoro ha visto l'integrazione dei kernel Helion all'interno di vLLM, un framework di serving e inference ad alte prestazioni per LLM, con l'obiettivo di migliorare l'efficienza dell'inference FP8 utilizzando i modelli della famiglia Qwen3.
Questa iniziativa si è concentrata sulla valutazione delle performance su hardware NVIDIA H100 e B200, due delle GPU più avanzate per carichi di lavoro AI. L'obiettivo primario era dimostrare come Helion possa offrire un flusso di lavoro PyTorch-native più produttivo per lo sviluppo di kernel GPU fusi, garantendo al contempo miglioramenti prestazionali per kernel di inference intensivi in termini di quantization, normalizzazione e fusione. I benchmark end-to-end hanno evidenziato incrementi di throughput in diversi scenari di serving, con ulteriori ottimizzazioni in corso per le performance GEMM sulle GPU Blackwell.
Dettagli Tecnici dell'Integrazione Helion-vLLM
vLLM è ampiamente utilizzato per il serving di LLM in produzione grazie alla sua elevata capacità di throughput, all'efficiente gestione della KV-cache e all'architettura di continuous batching. Internamente, vLLM si affida a kernel GPU personalizzati, alla fusione TorchInductor e a backend GEMM ottimizzati come CUTLASS e DeepGEMM. Helion, d'altra parte, è un DSL (Domain-Specific Language) per kernel, nativo di PyTorch e agnostico rispetto all'hardware, progettato per scrivere kernel ad alte prestazioni utilizzando un modello di programmazione a tile. Offre un'esperienza di sviluppo più naturale, simile a PyTorch o Triton, pur consentendo un controllo di basso livello su layout di memoria, strategia di tiling e scheduling dei kernel.
L'integrazione ha comportato la sostituzione di quasi tutti i kernel del forward-pass coinvolti nell'inference quantizzata con implementazioni Helion, concentrandosi inizialmente sull'inference senza parallelismo tensoriale con quantization delle attivazioni FP8. I benchmark sono stati condotti sia a livello di singolo kernel che a livello di serving end-to-end. Per le operazioni non-GEMM, i kernel Helion hanno costantemente superato sia i kernel generati da TorchInductor che le implementazioni CUDA esistenti di vLLM, con speedup che vanno da 1.133x a 2.269x a seconda del kernel e dell'hardware. Per i carichi di lavoro GEMM (scaled_mm e scaled_mm_blockwise), i risultati sono stati più eterogenei: su H100, scaled_mm ha superato CUTLASS (1.080x), mentre su B200 entrambi i kernel GEMM sono rimasti indietro rispetto a CUTLASS, principalmente a causa delle attuali limitazioni di Triton nella generazione di kernel GEMM per le GPU Blackwell.
Contesto e Implicazioni per i Deployment On-Premise
L'autotuning AOT (Ahead-Of-Time) di Helion è un punto di forza, in grado di esplorare un vasto spazio di configurazione dei kernel e selezionare automaticamente le implementazioni ottimizzate per specifici carichi di lavoro e hardware. Questa capacità è particolarmente rilevante per i deployment on-premise, dove la massimizzazione dell'efficienza hardware e la riduzione del TCO sono obiettivi primari. La possibilità di ottimizzare i kernel per le dimensioni statiche dei modelli (come hidden size e intermediate size) e per le dimensioni dinamiche (num_tokens) consente di ottenere performance elevate in scenari di produzione reali.
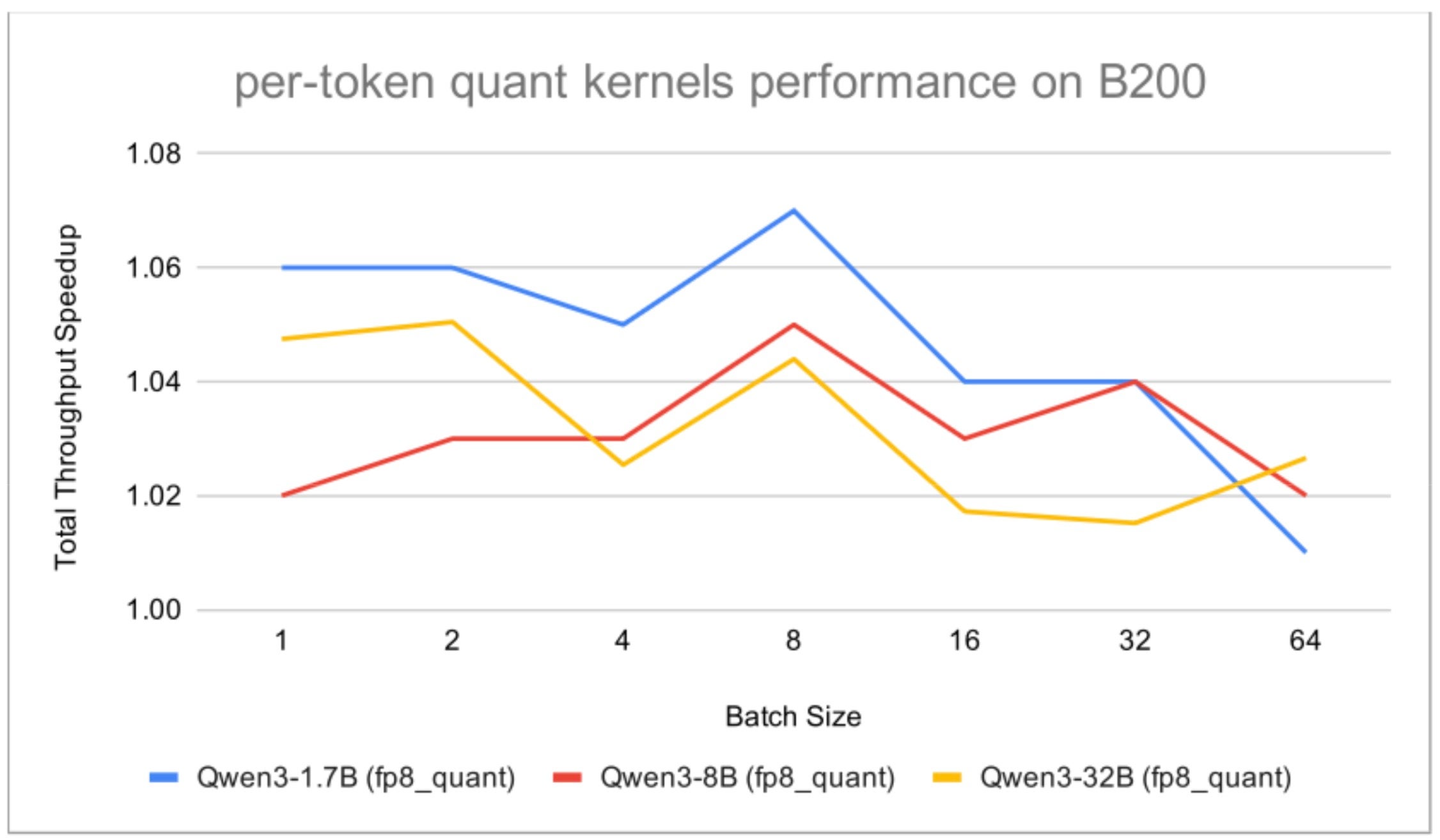
I benchmark end-to-end hanno mostrato miglioramenti significativi nel throughput totale. Ad esempio, con la quantization delle attivazioni per-token abilitata, si sono osservati incrementi di throughput fino a circa 1.09x per il modello Qwen3-8B su H100, specialmente in scenari di decoding speculativo. Anche su B200, abilitando solo i kernel relativi alla quantization FP8, si sono registrati miglioramenti significativi. Tuttavia, è importante notare che l'autotuning dei kernel può richiedere tempi considerevoli, fino a un'intera giornata per kernel complessi e un gran numero di forme di input. Inoltre, l'overhead della fase di dispatch di Helion, seppur nell'ordine delle decine di microsecondi, rende essenziale l'uso di CUDA graph capture e replay per ottenere performance ottimali, soprattutto per kernel di piccole dimensioni. Per chi valuta deployment on-premise, questi trade-off tra tempo di ottimizzazione e performance runtime sono considerazioni chiave.
Prospettive Future e Sviluppi
Helion si conferma uno strumento promettente per lo sviluppo rapido di nuovi kernel e l'esplorazione di opportunità di fusione, semplificando notevolmente il processo di implementazione. La capacità di scrivere e validare la maggior parte dei kernel in tempi brevi dimostra la sua praticità come DSL. Sebbene i kernel Helion abbiano dimostrato performance superiori nella maggior parte dei casi rispetto alle implementazioni vLLM predefinite, c'è ancora margine di miglioramento per i kernel GEMM, in particolare sulle GPU Blackwell. I team di sviluppo stanno attivamente lavorando per migliorare la generazione di codice Triton e introducendo backend alternativi come CuteDSL per affrontare queste sfide.
Il team Helion sta inoltre esplorando tecniche per ridurre i tempi di tuning, inclusi strategie di riduzione dello spazio di ricerca e approcci di autotuning guidati da LLM, e sta lavorando per ridurre la latenza di dispatch senza la modalità CudaGraph. Questi sviluppi futuri mirano a rendere Helion ancora più efficiente e versatile, consolidando il suo ruolo come componente chiave nell'ottimizzazione delle performance LLM su diverse piattaforme hardware, un aspetto fondamentale per le strategie di infrastruttura AI self-hosted.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!