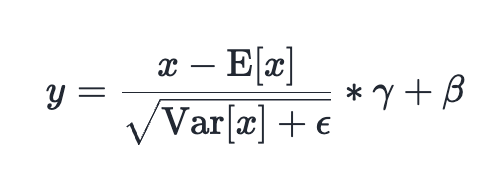
Introduzione: L'Efficienza delle Normalizzazioni per i LLM On-Premise
I metodi di normalizzazione, come LayerNorm e RMSNorm, costituiscono un pilastro fondamentale nel deep learning, essenziali per stabilizzare il processo di training dei modelli e garantire una convergenza più fluida. La loro efficienza è particolarmente critica in contesti di deployment on-premise, dove ogni ciclo di clock della GPU e ogni byte di memoria VRAM contano per ottimizzare il Total Cost of Ownership (TCO) e massimizzare il throughput. In questo scenario, l'ottimizzazione delle operazioni a basso livello può generare un impatto significativo sulle performance complessive dei Large Language Models (LLM).
Questo articolo esplora come il team di sviluppo di PyTorch abbia migliorato le prestazioni di torch.compile per le operazioni di LayerNorm e RMSNorm su hardware NVIDIA H100 e B200. L'obiettivo è stato raggiungere performance vicine allo stato dell'arte (SOTA) a livello di kernel, sfruttando anche le capacità di fusione automatica del compilatore. Tali avanzamenti sono vitali per CTO e architetti infrastrutturali che cercano di massimizzare l'efficienza dei loro stack AI self-hosted.
Dettagli Tecnici: Ottimizzazioni del Compilatore e Nuove Strategie
LayerNorm, introdotto nel 2016, normalizza gli input calcolando media e varianza, per poi scalarli con parametri apprendibili (gamma e beta). RMSNorm, una sua evoluzione del 2019, utilizza invece la radice quadrata della media dei quadrati (RMS) per la normalizzazione, eliminando il termine di bias e risultando spesso più efficiente. Per questa analisi, i benchmark di LayerNorm e RMSNorm sono stati presentati in modo intercambiabile data la somiglianza dei kernel.
Inizialmente, torch.compile mostrava prestazioni inferiori rispetto a Quack, una libreria di kernel CuteDSL ottimizzati di Tri Dao, che funge da baseline SOTA. I benchmark iniziali indicavano che torch.compile raggiungeva circa il 50% delle prestazioni di Quack. Tuttavia, attraverso un'attenta autotuning e l'ottimizzazione delle impostazioni predefinite di Inductor, il compilatore di PyTorch, è stato possibile colmare questo divario. Le modifiche chiave hanno incluso la calibrazione di parametri come R_BLOCK per le riduzioni interne, XBLOCK per le riduzioni persistenti e la riduzione del numero di num_warps per massimizzare la vettorizzazione e saturare la banda di memoria, un aspetto cruciale per l'architettura Blackwell della B200.
L'Innovazione del Backward Pass: MixOrderReduction e Pipelining
Il backward pass per le normalizzazioni è intrinsecamente più complesso, richiedendo il calcolo di gradienti per l'input (dX) e per i pesi (dW, dB). Un approccio ingenuo che esegue queste riduzioni in kernel separati comporta una doppia lettura degli stessi input, raddoppiando i byte trasferiti e aumentando significativamente la latenza, specialmente per carichi di lavoro memory-bound. Per affrontare questa sfida, torch.compile ha introdotto la strategia MixOrderReduction, che combina le riduzioni INNER (per dX) e OUTER (per dW, dB) in un unico kernel fuso.
Questa tecnica, ispirata a soluzioni come Liger di Meta e i kernel fusi di Quack, permette di elaborare simultaneamente i gradienti, riducendo drasticamente il traffico di memoria. Un aspetto cruciale di MixOrderReduction è l'autotuning del parametro SPLIT_SIZE, che può influenzare le prestazioni di oltre 2x. Ad esempio, una riduzione di 32x in SPLIT_SIZE ha portato a un miglioramento da 0.417 TB/s a 1.912 TB/s su H100 per il backward pass di RMSNorm con bfloat16. Inoltre, l'introduzione del software pipelining (prefetching dei carichi) come parametro di autotuning ha generato accelerazioni fino al 20% per alcune configurazioni, specialmente per input con grandi dimensioni M e piccole N.
Risultati e Implicazioni per l'Framework AI
I benchmark eseguiti su una macchina B200 da 750W con CUDA 12.9 (fine 2025) hanno dimostrato l'efficacia di queste ottimizzazioni. Per il backward pass di RMSNorm, torch.compile con MixOrderReduction ha raggiunto una velocità 17.07x superiore rispetto all'esecuzione eager di PyTorch, e quasi il doppio rispetto alla versione precedente di torch.compile senza MixOrderReduction (9.93x). Ancora più significativo, ha superato Liger di 1.45x e Quack di 1.34x. Risultati simili sono stati osservati per LayerNorm, confermando un significativo avvicinamento alla banda di memoria di picco.
Questi progressi sono di fondamentale importanza per le organizzazioni che implementano LLM e altri modelli di deep learning su infrastrutture on-premise. L'efficienza a livello di kernel si traduce direttamente in un maggiore throughput, una minore latenza e un TCO ottimizzato per l'hardware dedicato. La capacità di torch.compile di generare kernel ottimizzati e di eseguire fusioni automatiche con operazioni circostanti offre un vantaggio competitivo rispetto ai kernel scritti a mano, garantendo prestazioni end-to-end superiori. Per chi valuta deployment on-premise, questi miglioramenti sottolineano l'importanza di framework che massimizzano l'utilizzo delle risorse hardware, contribuendo alla sovranità dei dati e al controllo completo sull'ambiente di esecuzione.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!