Kernel Optimization for LLM Inference
Efficiency in Large Language Model (LLM) inference is a critical factor for companies evaluating on-premise deployments, where Total Cost of Ownership (TCO) and data sovereignty are top priorities. In this context, GPU kernel-level optimization can yield substantial benefits in terms of throughput and latency. Recent work has seen the integration of Helion kernels into vLLM, a high-performance LLM inference and serving framework, with the goal of improving FP8 inference efficiency using the Qwen3 model family.
This initiative focused on evaluating performance on NVIDIA H100 and B200 hardware, two of the most advanced GPUs for AI workloads. The primary objective was to demonstrate how Helion can offer a more productive PyTorch-native workflow for developing fused GPU kernels, while delivering performance improvements for inference kernels that are intensive in quantization, normalization, and fusion. End-to-end benchmarks showed throughput gains in various serving scenarios, with further optimization work underway for GEMM performance on Blackwell GPUs.
Technical Details of Helion-vLLM Integration
vLLM is widely used for production LLM serving due to its high throughput performance, efficient KV-cache management, and continuous batching architecture. Internally, vLLM relies on custom GPU kernels, TorchInductor fusion, and optimized GEMM backends such as CUTLASS and DeepGEMM. Helion, on the other hand, is a PyTorch-native, hardware-agnostic kernel DSL (Domain-Specific Language) designed for writing high-performance kernels using a tile-programming model. It offers a more natural development experience, similar to PyTorch or Triton, while still allowing low-level control over memory layout, tiling strategy, and kernel scheduling.
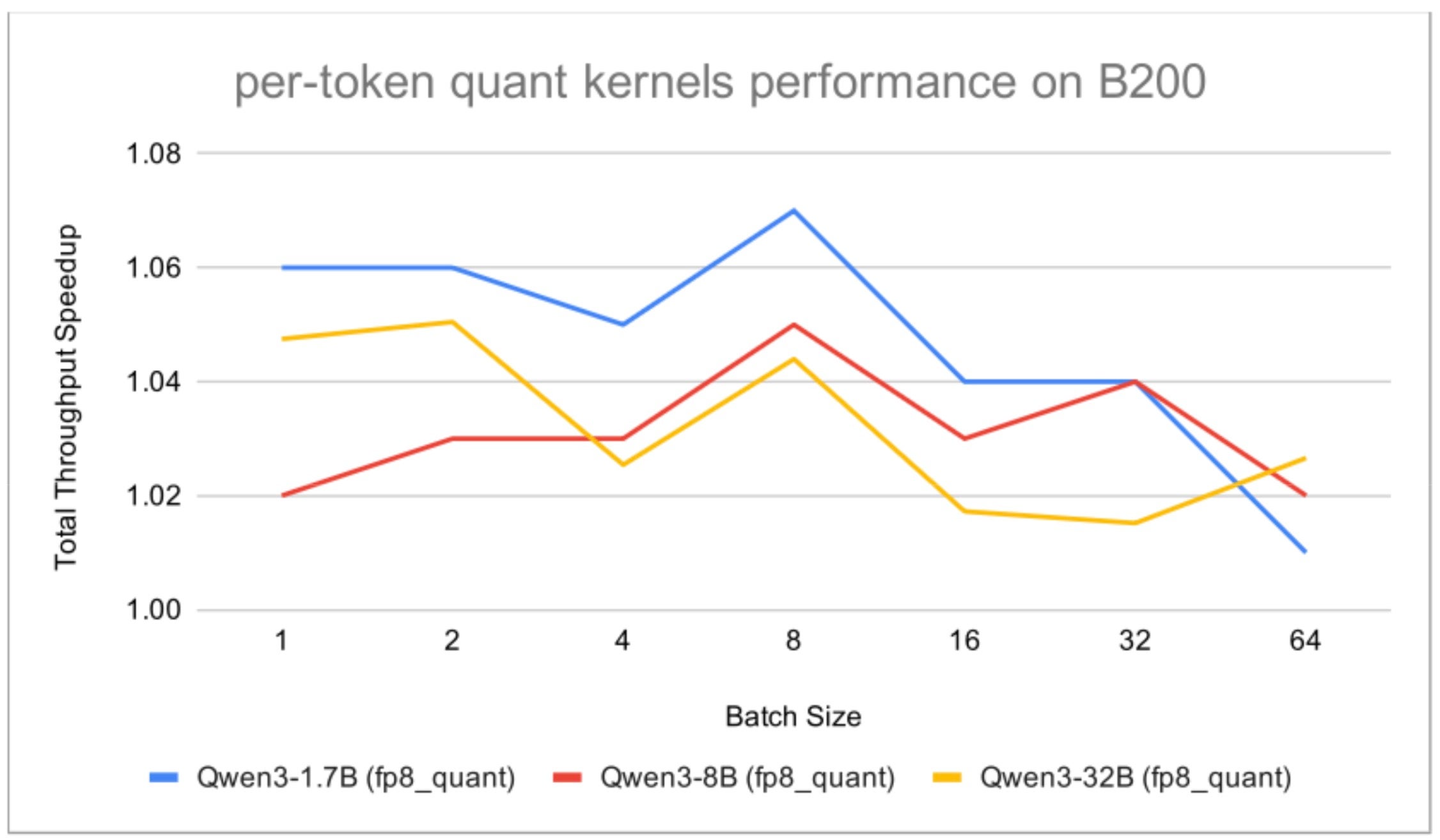
The integration involved replacing almost all forward-pass kernels involved in quantized inference with Helion implementations, initially focusing on tensor-parallel-free inference with FP8 activation quantization enabled. Benchmarks were conducted at both the kernel level and end-to-end serving level. For non-GEMM operations, Helion kernels consistently outperformed both TorchInductor-generated kernels and existing vLLM CUDA implementations, with speedups ranging from 1.133x to 2.269x depending on the kernel and hardware. For GEMM workloads (scaled_mm and scaled_mm_blockwise), results were more mixed: on H100, scaled_mm outperformed CUTLASS (1.080x), while on B200, both GEMM kernels lagged behind CUTLASS, primarily due to current Triton limitations in generating GEMM kernels for Blackwell GPUs.
Context and Implications for On-Premise Deployments
Helion's powerful AOT (Ahead-Of-Time) autotuning is a key strength, capable of exploring a large kernel configuration space and automatically selecting optimized implementations for specific workloads and hardware targets. This capability is particularly relevant for on-premise deployments, where maximizing hardware efficiency and reducing TCO are primary goals. The ability to optimize kernels for static model dimensions (such as hidden size and intermediate size) and dynamic dimensions (num_tokens) allows for high performance in real-world production scenarios.
End-to-end benchmarks showed significant improvements in total throughput. For example, with per-token activation quantization enabled, throughput increases of up to approximately 1.09x were observed for the Qwen3-8B model on H100, especially in speculative decoding scenarios. Even on B200, enabling only the FP8 quantization-related kernels resulted in meaningful improvements. However, it is important to note that kernel autotuning can be time-consuming, taking up to a full day for complex kernels and a large number of input shapes. Furthermore, Helion's dispatch overhead, although in the order of tens of microseconds, makes CUDA graph capture and replay essential for optimal performance, especially for small kernels. For those evaluating on-premise deployments, these trade-offs between optimization time and runtime performance are key considerations.
Future Prospects and Developments
Helion proves to be a promising tool for rapid development of new kernels and exploration of fusion opportunities, significantly simplifying the implementation process. The ability to write and validate most kernels in a short time demonstrates its practicality as a DSL. While Helion kernels have shown superior performance in most cases compared to default vLLM implementations, there is still room for improvement for GEMM kernels, particularly on Blackwell GPUs. Development teams are actively working to improve Triton code generation and introduce alternative backends like CuteDSL to address these challenges.
The Helion team is also exploring techniques to reduce tuning time, including search-space reduction strategies and LLM-guided autotuning approaches, and is working to reduce dispatch latency without CudaGraph mode. These future developments aim to make Helion even more efficient and versatile, solidifying its role as a key component in optimizing LLM performance across various hardware platforms, a fundamental aspect of self-hosted AI infrastructure strategies.











💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!