
Il Drago nella Sala Server: DeepSeek è la cura per la sbornia dei prezzi di Copilot?
Bentornati su AI-Radar. Se ultimamente avete prestato attenzione ai vostri budget di ingegneria del software, probabilmente state provando un dolore improvviso e acuto nel portafoglio. La fase della luna di miele dell'assistenza AI economica e apparentemente infinita è ufficialmente terminata.
A partire dal 1° giugno 2026, GitHub Copilot sta modificando radicalmente il suo modello di fatturazione, passando da un comodo sistema di richieste premium a tariffa fissa a un implacabile modello a token 'Crediti AI' basato sull'utilizzo. Gli sviluppatori che si affidano a framework di codifica agentica sono in preda al panico, e i Direttori Finanziari guardano le loro spese previste per il cloud computing con puro terrore.
Entra in scena il disruptor: DeepSeek. Questa azienda cinese di intelligenza artificiale relativamente nuova ha scatenato una raffica di modelli open-weight—in particolare il DeepSeek-V3, il motore di ragionamento DeepSeek-R1 e la nuovissima serie DeepSeek-V4—che stanno scuotendo la Silicon Valley. Gli investitori l'hanno definito un "momento Sputnik dell'IA", e a ragione. DeepSeek offre intelligenza di livello all'avanguardia a una frazione del costo, e sta distribuendo i pesi gratuitamente.
Ma questa realtà cinese è un'alternativa valida e pronta per l'impresa agli ecosistemi raffinati di Microsoft, OpenAI e Anthropic? Approfondiamo. Esploreremo i pro e i contro, analizzeremo i confronti di costo, indagheremo sugli intensi requisiti hardware del sogno "LLM On-Premise" e affronteremo il grande elefante nella stanza: i rischi di sicurezza geopolitici.
Parte 1: Il Dilemma di Copilot e la Grande Stretta sui Prezzi
Per capire perché l'industria è improvvisamente infatuata di DeepSeek, dobbiamo prima capire cosa stanno facendo Microsoft e GitHub alla vostra carta di credito.
Negli ultimi due anni, GitHub Copilot è stato un affare incredibilmente generoso. Pagavi una tariffa fissa—10 $ al mese per Pro, 19 $ per Business o 39 $ per Enterprise—e ricevevi essenzialmente un compagno di codifica illimitato. Tuttavia, l'IA si è evoluta. Non stiamo più solo chiedendo a Copilot di completare automaticamente una funzione Python; stiamo chiedendo all'IA agentica di leggere interi repository, rifattorizzare l'architettura ed eseguire sessioni di codifica autonome di più ore.
A causa di questa crescente domanda di calcolo, GitHub sta passando a un modello di utilizzo basato su token il 1° giugno 2026. Le Unità di Richieste Premium (PRU) sono morte, sostituite dai Crediti AI di GitHub (dove 1 credito equivale a 0,01 $). Secondo le nuove regole, i vostri token di input, output e memorizzati nella cache saranno misurati in base alle tariffe API pubblicate dei modelli sottostanti (come Claude 3.5 Sonnet, GPT-4.1 e OpenAI o3).
Per l'utente avanzato medio, questa è una crisi. Mentre i completamenti di codice di base rimangono gratuiti, qualsiasi lavoro pesante in Copilot Chat o in modalità agente consumerà i vostri crediti mensili inclusi a velocità vertiginose. In precedenza, se esaurivi le richieste premium, il sistema ti declassava elegantemente a un modello più economico come fallback. Non più. Sotto il nuovo regime basato sull'utilizzo, quando esaurisci i crediti, sei completamente tagliato fuori finché non ne paghi altri.
Se sei un'azienda con 50 sviluppatori che consumano token, la tua prevedibile fattura mensile di GitHub di 3.000 $ potrebbe facilmente gonfiarsi in una massiccia e imprevedibile passività. L'era dell'IA sovvenzionata è morta, ed è arrivata l'era della richiesta extra da 0,04 $.
Parte 2: Vi Presentiamo DeepSeek – Il Disruptor da Hangzhou
Se il nuovo modello di prezzi di Copilot è la malattia, DeepSeek si presenta come la cura.
Fondata nel luglio 2023 da Liang Wenfeng, un prodigio dei fondi hedge quantitativi e co-fondatore di High-Flyer, DeepSeek opera da Hangzhou, Cina. A differenza delle tradizionali startup tecniciche della Silicon Valley, pesantemente finanziate da venture capital e focalizzate su prodotti di consumo appariscenti, DeepSeek approccia l'IA con l'ottimizzazione matematica spietata di una società di trading ad alta frequenza.
Hanno raggiunto un ritmo di iterazione sbalorditivo. Negli ultimi due anni, sono passati dai transformer in stile Llama di base a design Mixture-of-Experts (MoE) altamente sofisticati.
L'attuale Arsenale DeepSeek:
DeepSeek-R1: Rilasciato all'inizio del 2025, è un modello di ragionamento dedicato progettato per competere direttamente con le serie o1 e o3 di OpenAI. Eccelle nella logica complessa, nella matematica avanzata e nella risoluzione di problemi passo-passo.
DeepSeek-V3.2: Un modello MoE generico economico e altamente capace che supera di gran lunga la sua categoria di peso.
DeepSeek-V4 (Pro e Flash): I nuovi arrivati, rilasciati nell'aprile 2026. Il V4-Pro è un colosso con 1,6 trilioni di parametri totali (49 miliardi attivi per token) e una finestra di contesto predefinita di 1 milione di token. Il V4-Flash è il suo fratello minore più snello, che vanta 284 miliardi di parametri (13 miliardi attivi).
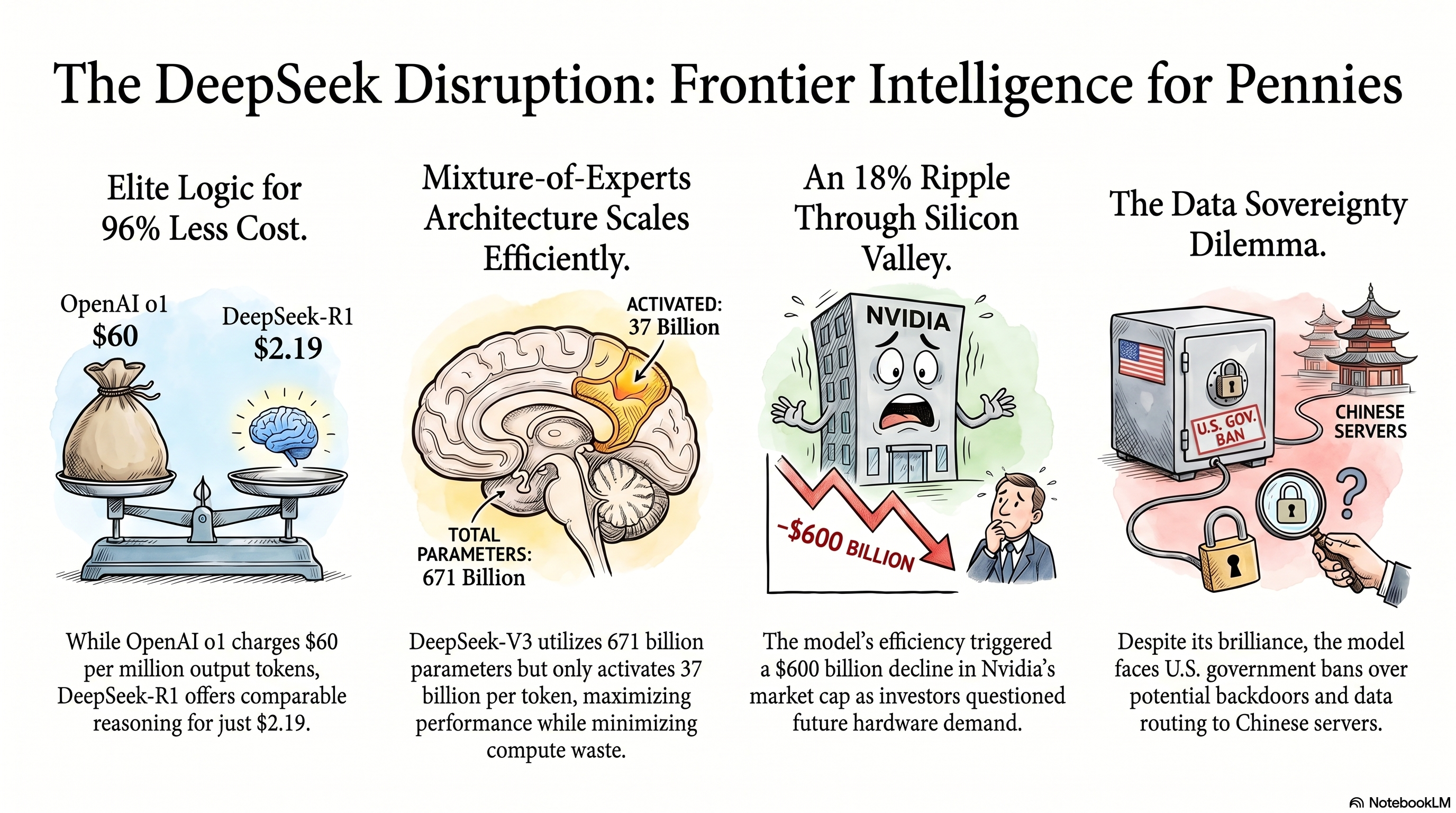
Ciò che rende DeepSeek speciale non è solo la sua dimensione; è quanto sia incredibilmente economico da addestrare ed eseguire. DeepSeek afferma di aver addestrato il modello V3 per soli 5,57 milioni di dollari utilizzando 2,788 milioni di ore GPU H800. Confrontate questo con i circa 100 milioni di dollari stimati che OpenAI ha speso per addestrare GPT-4, e iniziate a capire perché l'industria lo definisce un "momento Sputnik".
Hanno raggiunto questo obiettivo attraverso radicali innovazioni architettoniche. DeepSeek utilizza la Multi-head Latent Attention (MLA), che comprime la cache Key-Value (KV) in un vettore latente a basso rango, riducendo drasticamente l'ingombro di memoria richiesto durante l'inference. Hanno anche introdotto una strategia di bilanciamento del carico senza perdita ausiliaria per la loro architettura MoE, garantendo che i modelli esperti non subiscano degrado delle prestazioni pur mantenendo l'efficienza computazionale. Infine, hanno implementato la Multi-Token Prediction (MTP), consentendo al modello di prevedere più token futuri contemporaneamente, abilitando una decodifica speculativa altamente efficiente e riducendo drasticamente la latenza.
Parte 3: L'Economia delle API – Risparmiare con i Grandi
Analizziamo i numeri concreti. Se decidete di bypassare Copilot e collegare il vostro Visual Studio Code direttamente a un'API utilizzando estensioni come Cline, Roo Code o Continue.dev, le differenze di costo sono a dir poco astronomiche.
Ecco una ripartizione completa dei costi API a metà 2026, prezzati per 1 Milione di Token (Input / Output):
| Provider / Modello | Input (per 1M) | Output (per 1M) | Finestra di Contesto |
|---|---|---|---|
| DeepSeek V4 Flash | 0,14 $ | 0,28 $ | 1.000.000 |
| DeepSeek-Chat V3.2 | 0,28 $ | 0,42 $ | 128.000 |
| DeepSeek V4 Pro | 0,30 $ | 0,50 $ | 1.000.000 |
| DeepSeek R1 | 0,55 $ | 2,19 $ | 128.000 |
| Google Gemini 3.1 Flash Lite | 0,25 $ | 1,50 $ | 1.000.000 |
| Google Gemini 3.1 Pro | 2,00 $ | 12,00 $ | 1.000.000 |
| OpenAI GPT-5.4 | 2,50 $ | 15,00 $ | 272.000 (1M in Codex) |
| Anthropic Claude Sonnet 4.6 | 3,00 $ | 15,00 $ | 1.000.000 |
| Anthropic Claude Opus 4.6 | 5,00 $ | 25,00 $ | 1.000.000 |
| OpenAI o3 | 2,00 $ | 8,00 $ | 128.000 |
Nota: Le metriche di prezzo provengono dal monitoraggio del settore all'inizio-metà del 2026.
Guardate attentamente la tabella sopra. Il DeepSeek V4 Pro è 8 volte più economico di GPT-5.4 per i token di input, e un sorprendente 30 volte più economico di GPT-5.4 per i token di output.
Ma il vero trucco magico dei prezzi di DeepSeek è il loro Sconto Cache Hit. Se i vostri prompt condividono un prefisso comune—il che è incredibilmente frequente nei flussi di lavoro di codifica dove il prompt di sistema, le definizioni degli strumenti e la struttura del progetto vengono inviati ripetutamente—i token di input memorizzati nella cache su DeepSeek V4 costano un misero 0,03 $ per milione. Questo è uno sconto del 90% sugli input.
Se avete un agente autonomo pesante che esegue una sessione di debug multi-step, inviando avanti e indietro l'intera struttura del codebase, potreste accumulare 35 $ al mese su GPT-5.4 di OpenAI. Su DeepSeek V4 Pro? Esattamente lo stesso carico di lavoro vi costerebbe circa 4 $. Non c'è da meravigliarsi se gli sviluppatori stanno abbandonando le tradizionali sottoscrizioni Copilot in favore di una configurazione "Bring Your Own Key" (BYOK).
Parte 4: La Battaglia dei Benchmark – DeepSeek è Davvero Intelligente?
Un'IA economica è inutile se allucina codice terribile. Quindi, come si posiziona DeepSeek rispetto al campione indiscusso di codifica del 2026, Claude Opus 4.6, e al peso massimo GPT-5.5?
La risposta è: sorprendentemente bene. La narrativa secondo cui i modelli open-weight sono perennemente 12-18 mesi indietro rispetto ai modelli proprietari closed-source è stata completamente smantellata da DeepSeek.
Vediamo la classifica per l'ingegneria del software complessa e del mondo reale, utilizzando lo standard di settore SWE-bench:
| Modello | SWE-bench Verified / Pro | AIME 2024 / 2025 | GPQA Diamond |
|---|---|---|---|
| Claude Opus 4.6 / 4.7 | 80,8% / 64,3% (Pro) | 99,8% | 91,3% |
| MiniMax M2.5 (Open-Source) | 80,2% | - | - |
| GPT-5.4 / 5.5 | ~80,0% / 58,6% (Pro) | 88,0% | 92,0% |
| DeepSeek V4 Pro | 55,4% (Pro) | 89,3% (V3.2)* | 90,1% |
| DeepSeek R1 | ~72,0% | 79,8% | 71,5% |
Nota: Il punteggio SWE-bench varia notevolmente in base allo scaffolding e se si considerano i sottoinsiemi "Verified" o "Pro", che sono stati rivisti nel 2026 a causa di preoccupazioni di contaminazione.
Mentre Claude Opus 4.6/4.7 di Anthropic mantiene generalmente la corona assoluta per l'architettura sfumata e il refactoring profondo e multi-file, DeepSeek V4 Pro gli sta alle calcagna. Per il ragionamento matematico, DeepSeek R1 ottiene un incredibile 97,3% su MATH-500, superando ufficialmente il modello o1-1217 di OpenAI (96,4%).
DeepSeek V4 introduce anche tre distinte modalità di sforzo di ragionamento:
Non-pensiero: Per compiti di routine veloci e intuitivi.
Pensiero Elevato: Analisi logica più lenta e deliberata.
Pensiero Massimo: Spinge i limiti di calcolo del modello per risolvere i problemi limite più difficili.
Per il vostro sviluppatore aziendale medio che si occupa quotidianamente di correzione di bug, generazione di boilerplate e scrittura di script, probabilmente non noterete mai il delta del benchmark del 2-3% tra DeepSeek V4 Pro e Claude Opus 4.6. Noterete, tuttavia, la riduzione dell'85% nelle vostre bollette API mensili.
Parte 5: Andare Offline – Il Sogno dell'"LLM On-Premise"
Affrontiamo la fantasia aziendale definitiva: la sovranità assoluta dei dati.
Con GitHub Copilot, siete intrinsecamente legati all'infrastruttura cloud di Microsoft. La vostra proprietà intellettuale viene trasmessa via internet. Ma poiché DeepSeek è un modello "open-weight" (rilasciato principalmente sotto la licenza MIT altamente permissiva), potete teoricamente scaricare i pesi ed eseguire l'intero cervello sui vostri server.
È qui che la fantasia si scontra con il muro della realtà hardware.
DeepSeek V4 Pro e V3.2 Speciale sono colossali modelli MoE. V3.2 Speciale si attesta a 685 miliardi di parametri totali, e V4 Pro è un vero leviatano con 1,6 trilioni di parametri. Non potete eseguirli sul vostro PC da gaming potenziato.
La Realtà del Data Center
Per eseguire i modelli DeepSeek completi da 671B/685B in tempo reale per un'inference a velocità di produzione, avete bisogno di hardware serio, di classe data center. Anche se pesantemente quantizzato a precisione a 4 bit (come AWQ), i requisiti di VRAM superano i 350-400 GB. In piena precisione FP16, il requisito di memoria supera 1,4 TB.
Opzioni Hardware per la Distribuzione Completa del Modello:
Minimo Indispensabile (Quantizzato 4-bit/FP8): 8x GPU NVIDIA H100 da 80GB. Questo vi dà 640GB di VRAM, consentendo di caricare i pesi del modello (~400GB) lasciando circa 240GB per la cache KV per gestire lunghezze di contesto di 64K-80K. Costo totale? Ben oltre 300.000 $.
Produzione Raccomandata: 8x GPU NVIDIA H200 da 141GB. Fornisce 1,13 TB di VRAM, consentendo la finestra di contesto completa di 128K ad alta concorrenza.
La Fattoria di Mac Studio: Per gli ingegneri creativi con budget limitato, quattro Apple Mac Studio al massimo delle prestazioni (192GB di Memoria Unificata ciascuno) collegati in rete possono teoricamente eseguire il modello per circa 22.000 $.
La Costruzione Economica CPU/RAM: Se non vi preoccupa la latenza, potete costruire un server massiccio basato su CPU. Utilizzando processori Dual AMD Epyc serie 9005 e 1TB di RAM DDR5-6000 a 12 canali su una scheda madre Gigabyte MZ73-LM0, potete costruire un server per circa 20.000 $. La fregatura? La vostra velocità di generazione dei token sarà lentissima, da 5 a 35 token al secondo. Vedrete il codice digitarsi come se fosse internet dial-up del 1995.
I Salvatori: Modelli Distillati
Se il vostro dipartimento IT vi ha riso in faccia per aver richiesto un rack di server 8x H100, DeepSeek ha fornito un'alternativa brillante: la Distillazione.
DeepSeek ha estratto le capacità di ragionamento del massiccio modello R1 e le ha iniettate in architetture più piccole ed efficienti basate su Llama e Qwen.
DeepSeek-R1-Distill-Llama-70B: Un fantastico modello da 70 miliardi di parametri che ottiene un incredibile 94,5% su MATH-500. Quantizzato a 4 bit, questo richiede solo circa 40 GB di VRAM, il che significa che potete facilmente eseguirlo localmente su due GPU da gaming standard NVIDIA RTX 3090 o 4090.
**DeepSeek-R1-











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!