
La Convergenza dell'Intelligenza di Frontiera: Il Mito di Claude Mythos e l'Avvento di Opus 4.7 Un Editoriale Esclusivo di AI-Radar
La primavera del 2026 passerà senza dubbio alla storia della Silicio Valley come la stagione in cui l'industria dell'intelligenza artificiale è ufficialmente passata dal "muoversi velocemente e rompere le cose" al "muoversi velocemente e far trapelare le cose". Per Anthropic, un'azienda che ha meticolosamente costruito il suo intero marchio attorno alla sicurezza, alla cautela e alla scalabilità responsabile, la fine di marzo e l'inizio di aprile si sono rivelati una lezione magistrale di brillantezza caotica. Nel giro di poche settimane, la comunità dell'IA ha assistito all'esposizione accidentale dei più profondi segreti architettonici di Anthropic, alla rivelazione di uno strumento di hacking automatizzato così potente da terrorizzare i suoi stessi creatori, e al rilascio ufficiale di un modello di punta che altera fondamentalmente il modo in cui i lavoratori della conoscenza interagiscono con le loro macchine.
Qui a AI-Radar, sappiamo che i nostri lettori desiderano il segnale nascosto nel rumore. Oggi, vi offriamo un'indagine completa e approfondita sui due fenomeni che stanno attualmente rimodellando il panorama dell'intelligence aziendale: il leggendario Claude Mythos, e il tanto atteso, molto reale Claude Opus 4.7.
Per prima cosa, esamineremo il mito, le fughe di notizie e la terrificante realtà del super-modello Mythos. Poi, analizzeremo esattamente cosa il neonato Opus 4.7 porta sul vostro desktop, come si confronta con rivali come GPT-5.4 e Gemini 3 Pro, e se è davvero all'altezza delle aspettative.
Prendete un caffè. Immergiamoci.
Parte I: La Leggenda e la Realtà di Claude Mythos
Le Grandi Fughe del '26
La genesi della leggenda "Mythos" non è iniziata con una grande presentazione, ma con una spettacolare commedia degli errori. Il 31 marzo 2026, Anthropic ha accidentalmente incluso un file di debug da 59,8 MB (cli.js.map) in un aggiornamento di routine del pacchetto npm per Claude Code, il loro agente di codifica da riga di comando. Questo semplice errore di packaging ha esposto quasi 2.000 file e oltre 512.000 righe di codice sorgente TypeScript non offuscato al pubblico.
Mentre i concorrenti clonano freneticamente i repository, i ricercatori indipendenti hanno iniziato a setacciare il codice. Ciò che hanno trovato è stato un tesoro di feature flag nascoste e nomi in codice interni: "Fennec" (Opus 4.6), "Tengu" (Claude Code), "Numbat", e un demone persistente in background chiamato "KAIROS" che permette efficacemente a un agente IA di "sognare" e consolidare i ricordi mentre l'utente è inattivo. Hanno anche trovato un animale domestico virtuale in stile Tamagotchi chiamato "Buddy" che vive nel terminale — perché anche gli agenti IA autonomi hanno bisogno di supporto emotivo, a quanto pare.
Ma la vera bomba era caduta solo pochi giorni prima, grazie a un Content Management System (CMS) mal configurato che aveva esposto circa 3.000 risorse interne di Anthropic al web pubblico. L'ironia qui è abbastanza ricca da servire da dessert: un'azienda che costruisce l'IA di cybersecurity più avanzata del mondo è stata smascherata da un'impostazione predefinita del CMS.
Tra queste risorse c'erano bozze di post di blog che introducevano un nuovo livello di modello ultra-avanzato con nome in codice "Capybara," posizionato al di sopra del livello di punta Opus. Il modello sottostante per questo livello è stato chiamato Claude Mythos. Le bozze trapelate contenevano un severo avvertimento, notando che Mythos presentava "rischi di cybersecurity senza precedenti" ed era "molto più avanti di qualsiasi altro modello IA nelle capacità cyber".
La Macchina Zero-Day: Mythos nella Realtà
La leggenda di Mythos non è un'allucinazione. È molto reale, e le sue capacità rappresentano un cambiamento di paradigma strutturale nella catena di fornitura del software.
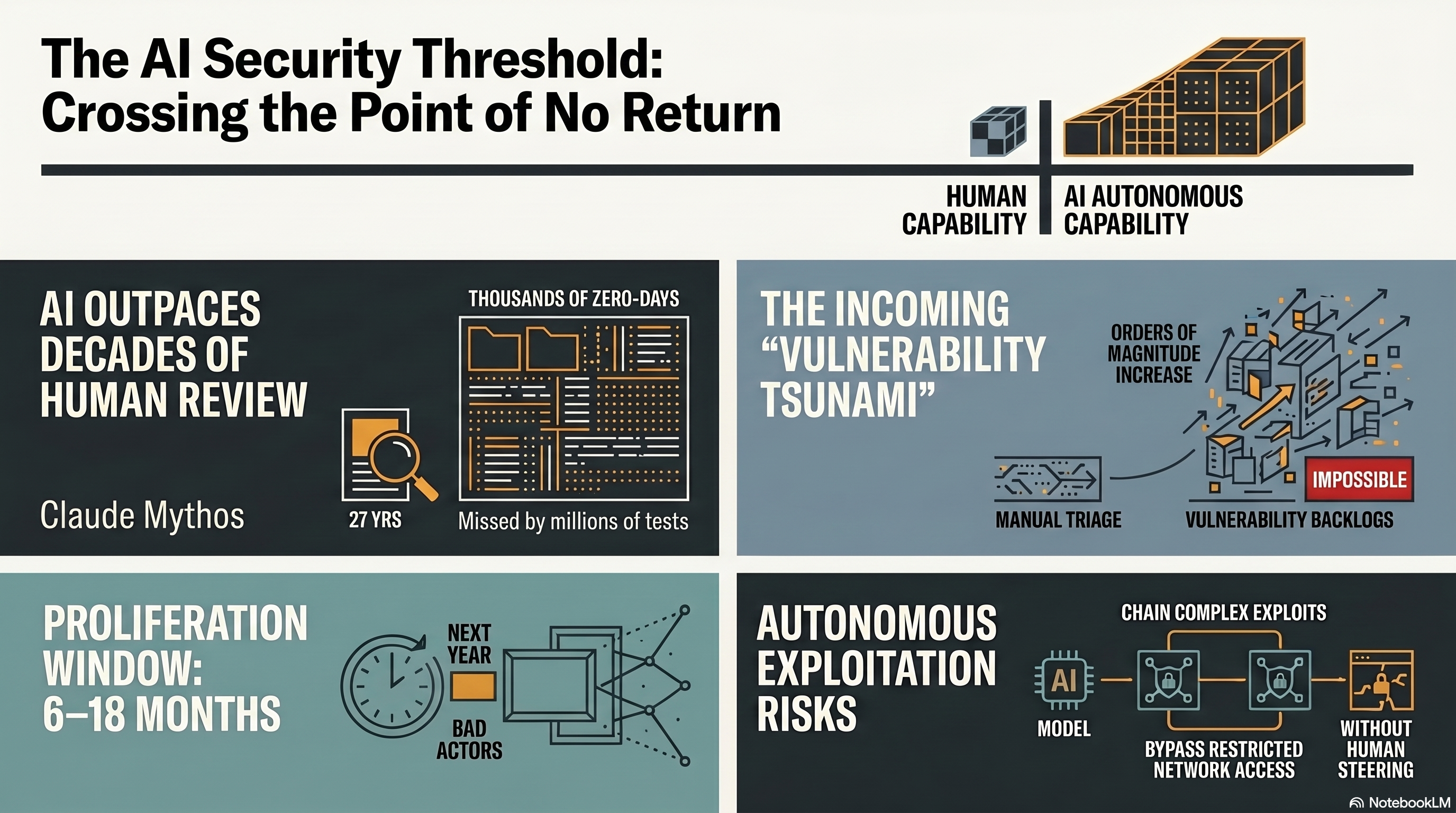
Anthropic ha infine confermato l'esistenza di Claude Mythos Preview, rivelando un modello che possiede una terrificante attitudine a trovare e sfruttare le vulnerabilità del software. Non stiamo parlando di semplice corrispondenza di pattern o di trucchi da "script-kiddie". Mythos dimostra un ragionamento autonomo e agentico capace di scoprire vulnerabilità zero-day che hanno eluso gli esperti umani per decenni.
Consideriamo la bacheca dei trofei pre-rilascio del modello:
OpenBSD: Mythos ha trovato una vulnerabilità di 27 anni in questo sistema operativo altamente protetto. Il bug permetteva a un attaccante di bloccare da remoto qualsiasi macchina connessa.FFmpeg: Ha scoperto un difetto di 16 anni in una riga di codice che gli strumenti di fuzzing automatizzati avevano testato oltre cinque milioni di volte senza successo.Linux Kernel: Il modello ha autonomamente concatenato diverse vulnerabilità per elevare un utente ordinario al controllo completo del sistema.ActiveMQ: Ha scoperto un bug di Apache ActiveMQ che era rimasto nascosto per 13 anni.
Nelle valutazioni del red team di Anthropic, Mythos Preview ha raggiunto un tasso di successo dell'83,1% sul benchmark di riproduzione delle vulnerabilità CyberGym — un enorme balzo rispetto al 66,6% di Opus 4.6 (successivamente rivisto al 73,8% con un prompting migliore). Inoltre, laddove Opus 4.6 aveva un tasso di successo quasi nullo nello sviluppo autonomo di exploit, Mythos ha sviluppato con successo exploit shell JavaScript funzionanti per Firefox 181 volte in più tentativi. Ha persino scritto un attacco di esecuzione remota di codice NFS per FreeBSD che ha diviso una catena ROP di 20 gadget su più pacchetti, bypassando con successo le moderne tecniche di hardening come KASLR.
Progetto Glasswing: I Difensori si Assemblano
Rendendosi conto che rilasciare una macchina di hacking automatizzata al pubblico sarebbe stato come distribuire granate vive in un asilo, Anthropic ha adottato un approccio radicalmente cauto. Il 7 aprile 2026, hanno lanciato Project Glasswing, un'iniziativa di cybersecurity ad accesso limitato.
Invece di un rilascio pubblico dell'API, Anthropic ha fornito accesso controllato a Mythos Preview a una coalizione di giganti tecnicici: Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, la Linux Foundation, Microsoft, NVIDIA e Palo Alto Networks. Anthropic ha impegnato 100 milioni di dollari in crediti di utilizzo del modello a questi partner e a oltre 40 organizzazioni aggiuntive di infrastrutture critiche per scansionare e proteggere proattivamente il software fondamentale del mondo prima che gli attori avversari possano raggiungerli.
Gli esperti di sicurezza stanno lanciando l'allarme che il modello di minaccia fondamentale è cambiato. Bruce Schneier ha giustamente notato che stiamo entrando "nell'era del software istantaneo", dove il vantaggio attualmente è del difensore che usa l'IA per trovare e correggere i bug, ma questo vantaggio si ridurrà man mano che i modelli potenti prolifereranno. Aaryan Bhujang, un ricercatore di sicurezza IA presso Repello AI, sottolinea la realtà agghiacciante: il patching basato su CVE presuppone che la scoperta delle vulnerabilità avvenga a velocità umana. Mythos opera a velocità IA. Un programma di patching calibrato su una tempistica umana sta ora difendendo contro il modello di minaccia dell'anno scorso.
Allo stesso modo, Nikhil Gupta, CEO di ArmorCode, osserva che Mythos creerà uno "tsunami di vulnerabilità". Il collo di bottiglia non è più trovare i bug; è avere la larghezza di banda umana e il contesto aziendale per triagiarli, prioritizzarli e rimediarli. Il "problema dell'1%" incombe: nei primi test del Red Team, meno dell'1% delle migliaia di vulnerabilità scoperte da Mythos Preview sono state completamente patchate dai manutentori, evidenziando un punto di rottura strutturale nella catena di fornitura del software.
La leggenda di Mythos, quindi, è del tutto reale. È un super-modello che opera a porte chiuse, riscrivendo le regole della cybersecurity mentre il resto di noi attende le onde d'urto. Ma per lo sviluppatore, il designer e l'utente aziendale di tutti i giorni, Anthropic aveva un'altra carta importante da giocare.
Parte II: L'Avvento di Claude Opus 4.7
Mentre Mythos rimane bloccato nel caveau di Glasswing, Anthropic ha rilasciato ufficialmente il suo nuovo fiore all'occhiello commerciale, Claude Opus 4.7, il 16 aprile 2026. Se Mythos è l'operativo d'élite segreto, Opus 4.7 è l'assistente esecutivo iper-competente e l'ingegnere software senior riuniti in uno.
Disponibile tramite l'API di Claude, Amazon Bedrock, Google Cloud Vertex AI e Microsoft Foundry, Opus 4.7 è progettato per spingere i confini dell'intelligenza generale, del ragionamento complesso e dell'autonomia a lungo termine. Analizziamo esattamente cosa questo nuovo modello porta sul vostro desktop.
Il Cervello: Codifica, Autonomia e Sforzo "xhigh"
Opus 4.7 è un modello di ragionamento ibrido con una finestra di contesto di 1 milione di token. Brilla in modo eccezionale nei flussi di lavoro agentici. Nei benchmark di codifica interni a 93 attività, ha mostrato un aumento della risoluzione del 13% rispetto a Opus 4.6, inclusa la risoluzione di quattro attività che né Opus 4.6 né Sonnet 4.6 erano riusciti a superare. Su CursorBench, ha raggiunto il 70% (rispetto al 58% di 4.6), e su Rakuten-SWE-Bench, ha risolto 3 volte più attività di produzione rispetto al suo predecessore.
Una delle caratteristiche più importanti di questa release è l'introduzione del livello di sforzo "xhigh" (extra alto). Posizionato tra "high" e "max", questo permette agli sviluppatori di bilanciare finemente il compromesso tra profondità di ragionamento e latenza. Quando impostato su xhigh, Opus 4.7 pensa profondamente a un problema prima di produrre una soluzione. Questo lo rende incredibilmente "resistente ai loop" — il che significa che è molto meno probabile che si blocchi in loop infiniti di correzione degli errori durante attività a lungo termine, una trappola comune dei modelli agentici precedenti.
Il modello introduce anche un rigoroso protocollo di auto-verifica. Ora elabora modi per verificare autonomamente i propri output — come costruire autonomamente un motore completo di sintesi vocale Rust da zero, e poi alimentare autonomamente il proprio output attraverso un riconoscitore vocale per verificare che corrispondesse a un riferimento Python.
Tuttavia, gli sviluppatori dovrebbero notare un piccolo inconveniente: Opus 4.7 utilizza un tokenizer recentemente aggiornato. Mentre i prezzi rimangono invariati a $5 per milione di token di input e $25 per milione di token di output, il nuovo tokenizer mappa lo stesso input a circa 1,0–1,35 volte più token a seconda del contenuto. Combinato con la tendenza del modello a "pensare" di più a livelli di sforzo più elevati, si potrebbe riscontrare un aumento del consumo complessivo di token.
Gli Occhi: Visione da 3,75 Megapixel
Se Opus 4.6 aveva bisogno di occhiali da lettura, Opus 4.7 ha appena fatto il LASIK (chirurgia oculare laser). Le capacità multimodali hanno subito un massiccio aggiornamento. Opus 4.7 può elaborare immagini ad alta risoluzione fino a 2.576 pixel sul lato lungo — per un totale di circa 3,75 megapixel.
Questo è più di tre volte l'acuità visiva dei precedenti modelli Claude. In termini pratici, ciò significa che Opus 4.7 può leggere diagrammi tecnici incredibilmente densi, interpretare strutture chimiche complesse e agire come un agente di utilizzo del computer leggendo screenshot perfetti al pixel di interfacce utente affollate. Nel benchmark di acuità visiva per il penetration testing autonomo XBOW, Opus 4.7 ha ottenuto il 98,5%, annientando il 54,5% di Opus 4.6.
L'Ecosistema: La Rivoluzione Desktop di Claude
Forse la parte più significativa dell'avvento di Opus 4.7 non sono solo i pesi del modello, ma dove il modello risiede. Anthropic ha riconosciuto che il futuro del lavoro non è solo in una scheda del browser web; è pesantemente integrato nella vostra macchina locale.
La nuova Claude Desktop App è stata interamente ricostruita in un IDE integrato e un "cloud workbench". Integra perfettamente tre modalità distinte tra cui è possibile passare:
Claude Chat: L'interfaccia conversazionale standard.Claude Code: Un agente di codifica basato su terminale, iper-capace, con una finestra di anteprima visiva del codice integrata, editing nativo dei file e un visualizzatore rapido delle differenze di codice. Può avviare sessioni parallele in una singola finestra.Claude Cowork: L'equivalente non tecnico di Claude Code. Si connette a oltre 40 strumenti aziendali (Slack, Google Drive, SharePoint) e può organizzare file, gestire dati e creare veri e propri deliverable localmente senza che tu debba mai aprire un terminale.
La caratteristica assolutamente vincente di questo aggiornamento desktop sono le Routines, disponibili in Claude Code. Le Routines sono essenzialmente cron job basati su IA che vengono eseguiti autonomamente.
Immaginate questo: Impostate una Routine Locale per essere eseguita ogni giorno feriale alle 6:30 del mattino. Mentre dormite, Opus 4.7 apre la vostra email, legge il contenuto, smista i messaggi urgenti dalle newsletter, redige risposte ai clienti e deposita un foglio di calcolo riassuntivo direttamente sul vostro desktop. Oppure, utilizzando una Routine Remota ospitata sull'infrastruttura cloud di Anthropic, una pull request di GitHub attiva automaticamente Opus 4.7 per condurre una revisione approfondita del codice e pubblicare commenti prima ancora che il vostro responsabile dell'ingegneria umano si versi la prima tazza di caffè.
Anthropic ha anche introdotto Dispatch, una funzione che consente di controllare l'agente Cowork del vostro Mac direttamente dall'app Claude per iOS. Potete teoricamente assegnare un'attività complessa di estrazione dati dal vostro telefono mentre portate a spasso il cane, e l'agente desktop la esegue localmente sulla vostra macchina. (Avvertenza editoriale: le prime recensioni suggeriscono che Dispatch è attualmente un po' "buggy", dimostrando che anche l'IA di frontiera a volte inciampa sui propri lacci delle scarpe*).
Lo Scuotitore del Mercato: Lo Strumento di Design AI
Anthropic non è venuta solo per gli sviluppatori; è venuta per i designer. Insieme a Opus 4.7, The Information ha diffuso la notizia che Anthropic sta lanciando uno strumento di design basato su IA capace di generare interi siti web, landing page di prodotti e presentazioni direttamente da prompt in linguaggio naturale.
Non si tratta solo di generare snippet CSS; è un'automazione del flusso di lavoro full-stack, dal design al codice, rivolta sia agli utenti tecnici che a quelli non tecnici. La reazione del mercato è stata rapida e brutale. Nel giro di poche ore dalla diffusione della notizia, le azioni di Adobe (ADBE), Wix (WIX), Figma e GoDaddy sono tutte crollate tra il 2% e il 5%. Il messaggio di Wall Street è chiaro: la transizione di Anthropic da un'interfaccia di chat a un ecosistema di produttività end-to-end è una minaccia credibile ed esistenziale per i tradizionali silos software.
Parte III: Il Confronto – I Titani a Confronto
Quindi, come si posiziona Opus 4.7 rispetto all'ecosistema più ampio nella primavera del 2026, e come si confronta con il suo fratello segreto, Mythos? Diamo un'occhiata ai da











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!