LinkedIn rivoluziona l'ottimizzazione con PyTorch e GPU
Le moderne piattaforme internet non si limitano a formulare previsioni; prendono anche decisioni complesse che guidano il comportamento intelligente di applicazioni web su larga scala. Per aziende come LinkedIn, queste decisioni si traducono spesso in problemi di ottimizzazione che, pur sembrando semplici, nascondono una complessità enorme: scegliere il miglior set di azioni tra milioni o miliardi di opzioni, rispettando vincoli specifici. La programmazione lineare (LP) rappresenta un framework matematico fondamentale per affrontare queste sfide, ma la sua applicazione su scala "web-scale" – con centinaia di milioni di utenti e trilioni di variabili decisionali – ha tradizionalmente messo in crisi i risolutori convenzionali.
I metodi classici, come quelli simplex o a punti interni, si basano su fattorizzazioni matriciali che diventano proibitive in termini di memoria e calcolo a fronte di dimensioni estreme. Per superare questi limiti, LinkedIn ha intrapreso una riarchitettura radicale del suo risolutore distribuito DuaLip, passando da uno stack basato su CPU (Scala/Spark) a una versione accelerata da GPU con PyTorch. Questa mossa strategica ha permesso di affrontare problemi di ottimizzazione che prima erano irrisolvibili in tempi accettabili, aprendo nuove possibilità per la gestione di sistemi decisionali complessi.
Dettagli tecnici: l'accelerazione GPU e la scalabilità
La transizione a DuaLip-GPU, la nuova incarnazione del risolutore di LinkedIn, è stata motivata dalla necessità di sfruttare appieno gli acceleratori hardware moderni. PyTorch si è rivelato la scelta ideale, offrendo accelerazione nativa per GPU, astrazioni flessibili per tensori (sia sparsi che densi) e operazioni efficienti per il calcolo gradiente. Queste capacità hanno permesso di strutturare la risoluzione di problemi LP su larga scala in modo simile all'addestramento di reti neurali, ma con primitive specifiche per l'ottimizzazione.
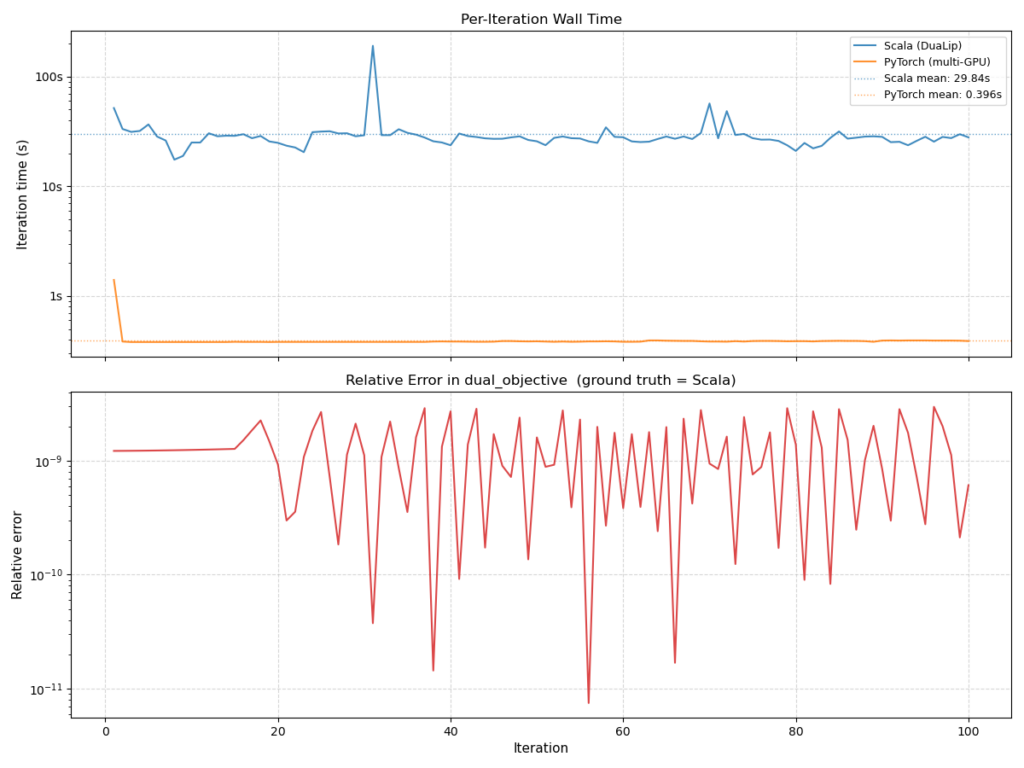
Il cuore di DuaLip-PyTorch risiede in un modello di programmazione a livello di operatore, che espone esplicitamente il flusso di dati su operazioni sparse matrice-vettore e proiezioni a blocchi. Questo approccio si traduce in un'esecuzione efficiente su GPU, senza richiedere modifiche al loop di ottimizzazione principale. La scalabilità distribuita è stata ottenuta partizionando le variabili tra le GPU e sincronizzando le variabili duali attraverso schemi di comunicazione collettiva come all-reduce e broadcast. Questi accorgimenti hanno consentito una scalabilità quasi lineare su più dispositivi, con il risolutore PyTorch (su 8 GPU) che ha dimostrato un incremento di velocità di 75 volte nel tempo di clock per iterazione rispetto all'implementazione Scala basata su CPU.
Implicazioni per l'infrastruttura e il TCO
L'adozione di PyTorch e l'accelerazione GPU da parte di LinkedIn sottolineano un trend crescente nel settore: la convergenza tra le tecniche di Machine Learning e quelle di ottimizzazione. Questa sinergia non solo ha permesso a LinkedIn di ottenere speedup di ordini di grandezza e di scalare efficacemente da sistemi a singola GPU a configurazioni multi-GPU, ma ha anche ridotto l'overhead ingegneristico per la formulazione di nuovi problemi di ottimizzazione. La capacità di gestire formulazioni LP flessibili ed estensibili è cruciale per piattaforme che evolvono rapidamente.
Per le aziende che valutano l'implementazione di carichi di lavoro AI/LLM, l'esperienza di LinkedIn offre spunti significativi. La scelta di uno stack ottimizzato per GPU, anche per problemi tradizionalmente CPU-bound, può avere un impatto diretto sul Total Cost of Ownership (TCO). Un'esecuzione più rapida e scalabile significa meno risorse computazionali necessarie per completare le operazioni, riducendo i costi operativi e migliorando l'efficienza. Questo approccio è particolarmente rilevante per chi considera deployment on-premise, dove il controllo sull'hardware e l'ottimizzazione delle risorse sono prioritari. AI-RADAR offre framework analitici su /llm-onpremise per valutare questi trade-off, fornendo strumenti per decisioni informate.
Prospettive future nell'ottimizzazione su larga scala
Il successo di DuaLip-PyTorch dimostra che l'ottimizzazione di livello industriale è ora possibile su scale precedentemente considerate impraticabili, grazie alla ristrutturazione dei risolutori attorno all'algebra lineare sparsa efficiente per GPU. Le operazioni dominanti, come le moltiplicazioni sparse matrice-vettore e gli aggiornamenti di proiezione, si mappano naturalmente all'esecuzione ad alto throughput delle GPU. Questo non solo apre la strada a risolutori più potenti e flessibili, ma spinge anche l'innovazione nell'hardware e nei framework software.
L'integrazione di tecniche di ottimizzazione avanzate, come la normalizzazione delle righe, le strategie di continuazione della regolarizzazione e i metodi di ottimizzazione del primo ordine (AGD e varianti FISTA), ha ulteriormente migliorato la velocità di convergenza mantenendo l'accuratezza. Questo approccio olistico, che combina innovazione algoritmica con l'utilizzo strategico dell'hardware, è fondamentale per affrontare le sfide future dell'ottimizzazione su larga scala e per sbloccare nuove capacità nelle applicazioni basate sull'intelligenza artificiale.










💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!