
The AI-Radar Editorial: The 2026 Cloud Infrastructure & VPS Battle Royale
Welcome to 2026, where the primary currency of technological innovation is no longer general-purpose compute, but raw, unadulterated GPU capacity. Attempting to train or fine-tune a Large Language Model (LLM) on a traditional CPU-heavy Virtual Private Server (VPS) is like trying to boil the ocean with a hairdryer. Today, AI requires specialized architectures, high-speed InfiniBand interconnects, and VRAM measured in hundreds of gigabytes.
In this exclusive AI-Radar deep dive, we evaluate the main VPS and Cloud GPU providers on the market. We will dissect their costs, features, security, customer care, and available templates. Whether you are hosting a sprawling 70B parameter model, fine-tuning an agentic AI, or just looking to run a stable inference endpoint without bankrupting your startup, this is your ultimate survival guide.
--------------------------------------------------------------------------------
Part 1: The Modern AI Cloud Hierarchy
The 2026 infrastructure market is defined by three distinct tiers.
Table 1: The Three Tiers of AI Infrastructure
| Tier | Description | Key Providers | Best For |
|---|---|---|---|
| Tier 1: Hyperscalers | Global giants with massive ecosystems but high premiums and strict lock-ins. | AWS, Microsoft Azure, Google Cloud (GCP), Oracle (OCI) | Enterprise-scale end-to-end ML pipelines, deep integrations. |
| Tier 2: Specialized Neoclouds & VPS | AI-first clouds focusing entirely on GPU compute, offering better pricing and specialized hardware. | CoreWeave, Lambda Labs, GMI Cloud, GPU Mart, DigitalOcean, Vultr, Linode/Akamai, Hetzner. | Startups, research labs, rapid fine-tuning, and production inference. |
| Tier 3: Decentralized Marketplaces | P2P platforms aggregating underutilized GPUs. Rock-bottom prices, but highly volatile. | Vast.ai, RunPod (Community), io.net, TensorDock. | Cost-sensitive batch jobs, throwaway data experiments. |
--------------------------------------------------------------------------------
Part 2: Provider Pros, Cons & The AI Focus
Let's break down the main players through the lens of AI model hosting, LLM fine-tuning, and high-performance computing.
Table 2: Comprehensive Pros & Cons Analysis
| Provider | Pros | Cons | AI / LLM Focus |
|---|---|---|---|
| AWS | Deep ecosystem (SageMaker); 29% market share; global availability; custom Trainium/Inferentia chips. | Punishing data egress fees (~$90/TB); complex pricing; GPU quota waitlists. | Enterprise training; production MLOps deployment. |
| Microsoft Azure | Incredible Microsoft/OpenAI integration; 20% market share; strong hybrid cloud support. | Complex configuration; steep enterprise pricing; locked-in ecosystem. | Regulated enterprises standardized on Windows/Active Directory. |
| Google Cloud (GCP) | Exclusive access to TPUs (v5p); Vertex AI integration; 13% market share. | High egress fees (~$120/TB); steep learning curve; complex quota approvals. | TensorFlow/JAX-heavy workloads; massive data analytics. |
| CoreWeave | Purpose-built Kubernetes-native AI cloud; InfiniBand networking; scales to thousands of GPUs. | Requires deep Kubernetes expertise; enterprise focus means steep minimums. | Frontier model training (1,000+ GPUs); reinforcement learning. |
| Lambda Labs | "SSH-and-go" simplicity; pre-configured deep learning stacks; transparent pricing. | Frequent hardware shortages; less robust networking for massive clusters. | Research teams, academic labs, rapid fine-tuning. |
| RunPod | Per-second billing; Serverless inference endpoints; Secure vs. Community tiers. | Community cloud lacks SLAs and can be unstable; network volumes can bottleneck. | Bursty inference APIs, container-based orchestration, scalable LLMs. |
| Vast.ai | Unbeatable pricing (up to 70% cheaper); massive variety of consumer and enterprise GPUs. | Zero reliability guarantees; hosts can terminate instances without warning; no compliance. | Short-term, fault-tolerant experiments with disposable data. |
| DigitalOcean | Beautiful UX; 1-click model deployments (e.g., Llama 3.1); highly predictable billing. | Higher cost per GPU hour than pure specialists; bandwidth limits (e.g., 6TB). | Small teams, web apps needing integrated GPU inference. |
| Vultr | 33 global locations; bare-metal GPU options; easy Kubernetes engine. | Support can be inconsistent; smaller AI ecosystem than hyperscalers. | Low-latency edge inference across the globe. |
| Linode (Akamai) | Generous bandwidth; LKE (managed Kubernetes) control plane is free; predictable pricing. | Narrower GPU selection compared to specialists; Akamai rebrand shifted focus to CDN. | Startups running general containerized ML workloads. |
| Hetzner (Outside Info) | Extremely aggressive pricing for dedicated root servers and cloud VPS; massive bandwidth. | Very limited/no specialized high-end NVIDIA AI GPUs (H100/A100); strict abuse policies. | General CPU hosting, data storage, or running smaller, CPU-bound models. |
--------------------------------------------------------------------------------
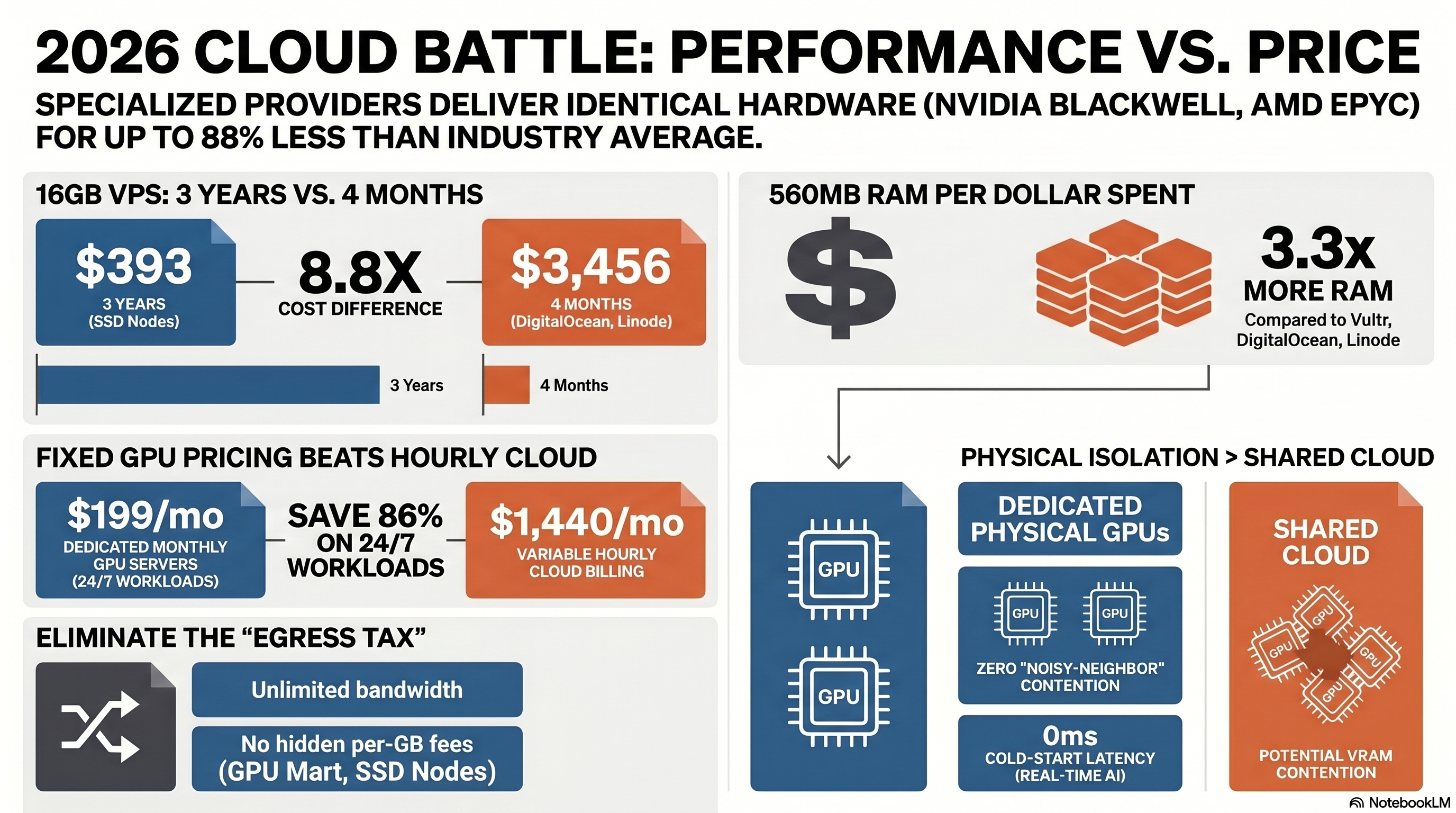
Part 3: The True Cost of AI Compute
The headline "per-hour" GPU cost is often a trap. Total Cost of Ownership (TCO) in 2026 relies heavily on three factors: Egress Fees, Cold Starts, and Billing Granularity.
If you are serving an LLM inference API, you need to account for bandwidth. An image generation API or a chat platform can easily burn through terabytes of outbound data. Hyperscalers will penalize you severely for this, while specialists often include unlimited or cheap bandwidth.
Table 3: Cost & Pricing Model Comparison
| Provider | Billing Granularity | Est. H100 Price (Per Hour) | Data Egress Fees | Cost Efficiency for AI |
|---|---|---|---|---|
| AWS | Per-second / Hourly | ~$12.29 | ~$90/TB | Low for sustained heavy traffic; Spot instances save up to 90%. |
| GCP | Per-second | ~$14.19 | ~$120/TB | Low for traffic; "Committed Use" saves up to 57%. |
| CoreWeave | Per-second / Reserved | ~$2.44 - $4.25 | Free / Predictable | High for massive scale; reserves offer 60% discounts. |
| Lambda Labs | Hourly | ~$2.49 | Free / Unlimited | High for researchers; 1-year reserved drops price ~37%. |
| RunPod | Per-second | ~$1.99 - $2.34 | Free | Extremely High for bursty traffic; Serverless prevents idle costs. |
| Vast.ai | Per-second | ~$1.87 - $2.67 | Billed separately by host | Absolute cheapest, but spotty reliability makes it risky. |
| GPU Mart | Hourly or Flat Monthly | $2,599/mo (Flat) | Unlimited | Best for 24/7 inference; monthly flat rate beats hourly by 3-5x. |
Pro Tip: If your LLM runs 24/7, hourly billing is a financial mistake. Providers like GPU Mart offering flat monthly fees (e.g., an RTX Pro 4000 for $199/mo) can undercut cloud hourly rates by up to 86%.
--------------------------------------------------------------------------------
Part 4: Features, Templates, and Ecosystems
To deploy LLMs efficiently, you cannot spend three days fighting CUDA driver mismatches. You need platforms that offer "Time-to-GPU" efficiency, modern inference engines, and Kubernetes integrations.
The Rise of vLLM & SafeTensors For production inference, the industry standard is now vLLM, which utilizes PagedAttention and continuous batching to increase throughput by 8-24x over traditional serving. Providers must support Docker environments capable of running vLLM with SafeTensors (which prevents malicious code execution during model loading).
Table 4: Deployment Features & Templates
| Provider | Environment Setup & Templates | AI Orchestration Features |
|---|---|---|
| Lambda Labs | Lambda Stack: Pre-installs PyTorch, TensorFlow, and CUDA. Pure "SSH-and-go" simplicity. | Simple VMs. No built-in Kubernetes overhead. |
| RunPod | RunPod Hub / Pods: Massive template library (vLLM, Stable Diffusion, LLaMA). 1-click Docker. | Serverless endpoints scale to 0. Native API generation. |
| CoreWeave | Advanced. Requires custom container builds for their environment. | Mission Control: Fully managed Kubernetes, Serverless RL, and InfiniBand. |
| DigitalOcean | 1-Click Models: Deploy Llama 3.1 via Hugging Face instantly. | DOKS (Kubernetes) supports GPU nodes seamlessly. |
| Paperspace | Gradient IDE: ML notebooks pre-configured out of the box. | Excellent for data science exploration; limits on budget tiers. |
--------------------------------------------------------------------------------
Part 5: Security, Compliance, and Data Sovereignty
AI models are ingesting proprietary corporate data, financial records, and patient health information (PHI). Operating an LLM on an uncertified cloud is a massive liability. The 2026 gold standard requires a unified control framework covering SOC 2 Type II and HIPAA compliance.
Table 5: Security & Compliance Posture
| Provider | Isolation Model | SOC 2 / HIPAA / GDPR | Security Notes |
|---|---|---|---|
| AWS / Azure / GCP | Hypervisor (VM) | Fully Compliant | Enterprise-grade IAM, KMS, and VPC isolation. |
| CoreWeave | Kubernetes / Container | SOC 2 (Mid-2026) / HIPAA | Bare-metal access available; BAA agreements supported; CrowdStrike partnered. |
| RunPod | Container | SOC 2 / HIPAA / GDPR | Secure Cloud runs in Tier 3/4 datacenters with AES-256 encryption. Role-Based Access Control (RBAC). |
| Vast.ai | Docker / P2P | None | Third-party hosts. Do not use for sensitive or proprietary data. |
| GPU Mart | Physical Dedicated | SOC-certified US DC | Physical hardware isolation prevents VRAM snooping and "noisy neighbors". |
| Akamai (Linode) | Hypervisor (VM) | Fully Compliant | Cilium CNI on Enterprise Kubernetes provides deep network isolation. |
If you are in healthcare or finance, RunPod's Secure Cloud or CoreWeave offer the best blend of specialized GPU access and strict HIPAA/SOC 2 compliance without duplicating effort. Avoid community clouds and P2P marketplaces at all costs for sensitive data.
--------------------------------------------------------------------------------
Part 6: Customer Care — When the GPUs Catch Fire
If a multi-node training job crashes on day 12, who do you call? Customer support in the GPU cloud space ranges from dedicated engineers to absolute silence.
Table 6: Customer Support Realities
| Provider | Support Model | The Reality |
|---|---|---|
| GPU Mart | Free 24/7 Human | Unmatched. Sub-5-minute response times from actual engineers. |
| Lambda Labs | AI Engineers | Built by researchers. Support understands CUDA/NCCL issues deeply, but responses are strictly business hours. |
| Hyperscalers (AWS/Azure) | Tiered / Paid | Robust, but highly responsive support is locked behind massive enterprise paywalls. |
| RunPod | Ticketing / Discord | Good documentation, but relies heavily on ticketing and a community Discord. |
| Vast.ai | Community | You are completely on your own. 1-3 day email response times. |
--------------------------------------------------------------------------------
Final Verdict: Choosing Your AI Cloud
There is no single "best" provider in 2026—only the right provider for your specific AI lifecycle stage.
For the AI Researcher & Experimenter: If you need to test a script quickly or perform a hyperparameter sweep on a budget, Vast.ai and RunPod (Community) offer throwaway compute at unbeatable prices.For the Startup Deploying AI Inference: If you are serving an LLM to users and need low latency, zero cold starts, and predictable pricing, RunPod (Secure Cloud) for serverless scaling, or GPU Mart for fixed monthly 24/7 dedicated instances are your best bets.For Large-Scale Model Training: If you are orchestrating thousands of GPUs to train a foundational model, you need the InfiniBand networking and Kubernetes orchestration of CoreWeave.For the Enterprise Standard: If your company is already married to Microsoft, or you need unparalleled global data residency and security integrations, bite the bullet and pay the premium for Azure or AWS.
The GPU cloud market has matured. You no longer have to accept the hyperscaler "tax" just to get reliable compute. Match your workload to the provider, secure your data, and happy training.










💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!