
L'Editoriale AI-Radar: Lo Scontro Finale dell'Framework Cloud e VPS nel 2026
Benvenuti nel 2026, dove la principale valuta dell'innovazione tecnicica non è più la capacità di calcolo generica, ma la pura e inalterata capacità GPU. Tentare di addestrare o ottimizzare un Large Language Model (LLM) su un tradizionale Virtual Private Server (VPS) basato su CPU è come cercare di bollire l'oceano con un asciugacapelli. Oggi, l'AI richiede architetture specializzate, interconnessioni InfiniBand ad alta velocità e VRAM misurata in centinaia di gigabyte.
In questo approfondimento esclusivo di AI-Radar, valutiamo i principali provider di VPS e Cloud GPU sul mercato. Analizzeremo i loro costi, funzionalità, sicurezza, assistenza clienti e template disponibili. Che tu stia ospitando un vasto modello da 70 miliardi di parametri, ottimizzando un'IA agentica o semplicemente cercando di eseguire un endpoint di inference stabile senza mandare in bancarotta la tua startup, questa è la tua guida di sopravvivenza definitiva.
Parte 1: La Moderna Gerarchia del Cloud AI
Il mercato delle infrastrutture del 2026 è definito da tre livelli distinti.
Tabella 1: I Tre Livelli dell'Framework AI | Livello | Descrizione | Provider Chiave | Ideale Per | | :--- | :--- | :--- | :--- | | Livello 1: Hyperscaler | Giganti globali con ecosistemi massicci ma costi elevati e rigidi vincoli (lock-in). | AWS, Microsoft Azure, Google Cloud (GCP), Oracle (OCI) | Pipeline ML end-to-end a livello enterprise, integrazioni profonde. | | Livello 2: Neocloud Specializzati e VPS | Cloud 'AI-first' che si concentrano interamente sul calcolo GPU, offrendo prezzi migliori e hardware specializzato. | CoreWeave, Lambda Labs, GMI Cloud, GPU Mart, DigitalOcean, Vultr, Linode/Akamai, Hetzner. | Startup, laboratori di ricerca, fine-tuning rapido e inference in produzione. | | Livello 3: Mercati Decentralizzati | Piattaforme P2P che aggregano GPU sottoutilizzate. Prezzi stracciati, ma altamente volatili. | Vast.ai, RunPod (Community), io.net, TensorDock. | Lavori batch sensibili al costo, esperimenti con dati 'usa e getta'. |
Parte 2: Pro, Contro dei Provider e il Focus AI
Analizziamo i principali attori attraverso la lente dell'hosting di modelli AI, del fine-tuning di LLM e del calcolo ad alte prestazioni.
Tabella 2: Analisi Completa di Pro e Contro
| Provider | Pro | Contro | Focus AI / LLM |
|---|---|---|---|
| AWS | Ecosistema profondo (SageMaker); 29% di quota di mercato; disponibilità globale; chip personalizzati Trainium/Inferentia. | Costi di egress dati punitivi (~$90/TB); prezzi complessi; liste d'attesa per le quote GPU. | Training enterprise; deployment MLOps in produzione. |
| Microsoft Azure | Incredibile integrazione Microsoft/OpenAI; 20% di quota di mercato; forte supporto per il cloud ibrido. | Configurazione complessa; prezzi enterprise elevati; ecosistema con lock-in. | Aziende regolamentate standardizzate su Windows/Active Directory. |
| Google Cloud (GCP) | Accesso esclusivo a TPU (v5p); integrazione Vertex AI; 13% di quota di mercato. | Costi di egress elevati (~$120/TB); curva di apprendimento ripida; approvazioni di quote complesse. | Carichi di lavoro intensivi con TensorFlow/JAX; analisi di dati massicci. |
| CoreWeave | Cloud AI nativo Kubernetes costruito appositamente; networking InfiniBand; scalabile a migliaia di GPU. | Richiede profonda esperienza Kubernetes; il focus enterprise implica minimi elevati. | Training di modelli all'avanguardia (oltre 1.000 GPU); apprendimento per rinforzo. |
| Lambda Labs | Semplicità "SSH-and-go"; stack di deep learning preconfigurati; prezzi trasparenti. | Frequenti carenze hardware; networking meno robusto per cluster massicci. | Team di ricerca, laboratori accademici, fine-tuning rapido. |
| RunPod | Fatturazione al secondo; endpoint di inference Serverless; livelli Secure vs. Community. | Il cloud Community manca di SLA e può essere instabile; i volumi di rete possono creare colli di bottiglia. | API di inference 'bursty', orchestrazione basata su container, LLM scalabili. |
| Vast.ai | Prezzi imbattibili (fino al 70% più economici); enorme varietà di GPU consumer ed enterprise. | Zero garanzie di affidabilità; gli host possono terminare le istanze senza preavviso; nessuna conformità. | Esperimenti a breve termine, tolleranti ai guasti, con dati 'usa e getta'. |
| DigitalOcean | Bella UX; deployment di modelli con 1 clic (es. Llama 3.1); fatturazione altamente prevedibile. | Costo per ora GPU più elevato rispetto agli specialisti puri; limiti di banda (es. 6TB). | Piccoli team, applicazioni web che necessitano di inference GPU integrata. |
| Vultr | 33 località globali; opzioni GPU bare-metal; motore Kubernetes facile. | Il supporto può essere inconsistente; ecosistema AI più piccolo rispetto agli hyperscaler. | Inference edge a bassa latenza in tutto il mondo. |
| Linode (Akamai) | Banda generosa; il control plane LKE (Kubernetes gestito) è gratuito; prezzi prevedibili. | Selezione GPU più limitata rispetto agli specialisti; il rebranding Akamai ha spostato il focus sul CDN. | Startup che eseguono carichi di lavoro ML containerizzati generici. |
| Hetzner (Info Esterna) | Prezzi estremamente aggressivi per server dedicati root e cloud VPS; banda massiccia. | GPU AI NVIDIA di fascia alta specializzate (H100/A100) molto limitate/assenti; politiche di abuso severe. | Hosting CPU generico, archiviazione dati o esecuzione di modelli più piccoli e vincolati alla CPU. |
Parte 3: Il Vero Costo del Calcolo AI
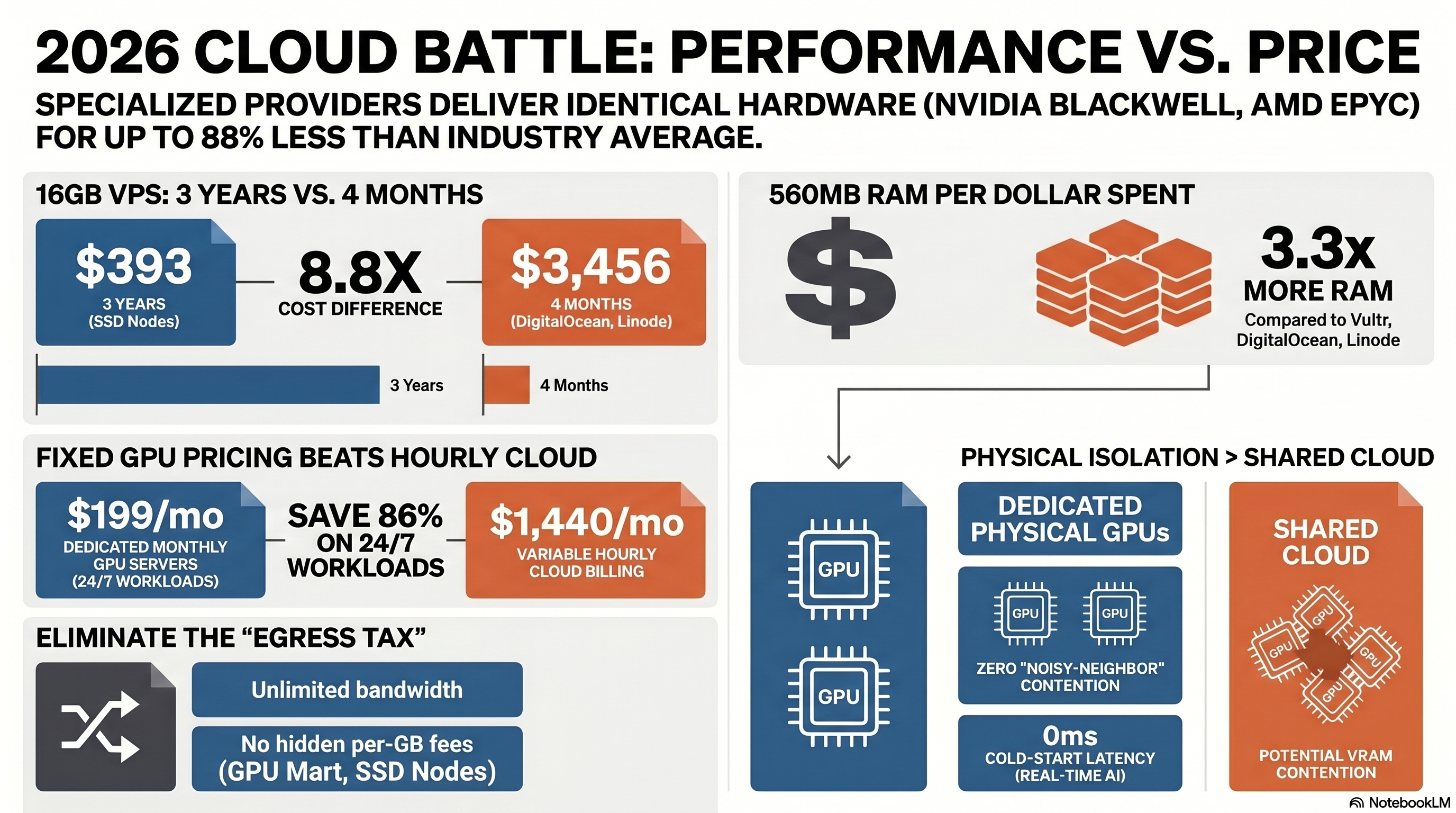
Il costo "per ora" della GPU, spesso in evidenza, è spesso una trappola. Il TCO (TCO) nel 2026 dipende fortemente da tre fattori: Costi di Egress, Cold Start e Granularità di Fatturazione.
Se stai servendo un'API di inference LLM, devi considerare la larghezza di banda. Un'API di generazione di immagini o una piattaforma di chat possono facilmente consumare terabyte di dati in uscita. Gli hyperscaler ti penalizzeranno severamente per questo, mentre gli specialisti spesso includono banda illimitata o economica.
Tabella 3: Confronto Costi e Modelli di Prezzo
| Provider | Granularità di Fatturazione | Prezzo Stimato H100 (Per Ora) | Costi di Egress Dati | Efficienza Costi per AI |
|---|---|---|---|---|
| AWS | Al secondo / Oraria | ~$12.29 | ~$90/TB | Bassa per traffico pesante sostenuto; le istanze Spot risparmiano fino al 90%. |
| GCP | Al secondo | ~$14.19 | ~$120/TB | Bassa per il traffico; "Committed Use" risparmia fino al 57%. |
| CoreWeave | Al secondo / Riservata | ~$2.44 - $4.25 | Gratuita / Prevedibile | Alta per scala massiccia; le riserve offrono sconti del 60%. |
| Lambda Labs | Oraria | ~$2.49 | Gratuita / Illimitata | Alta per i ricercatori; la prenotazione di 1 anno riduce il prezzo di circa il 37%. |
| RunPod | Al secondo | ~$1.99 - $2.34 | Gratuita | Estremamente alta per traffico 'bursty'; Serverless previene i costi di inattività. |
| Vast.ai | Al secondo | ~$1.87 - $2.67 | Fatturata separatamente dall'host | Assolutamente il più economico, ma l'affidabilità discontinua lo rende rischioso. |
| GPU Mart | Oraria o Mensile Fissa | $2.599/mese (Fissa) | Illimitata | Ideale per inference 24/7; la tariffa mensile fissa batte quella oraria di 3-5 volte. |
Consiglio Pro: Se il tuo LLM funziona 24 ore su 24, 7 giorni su 7, la fatturazione oraria è un errore finanziario. Provider come GPU Mart che offrono tariffe mensili fisse (es. una RTX Pro 4000 a $199/mese) possono battere le tariffe orarie del cloud fino all'86%.
Parte 4: Funzionalità, Template ed Ecosistemi
Per implementare LLM in modo efficiente, non puoi passare tre giorni a combattere con incompatibilità dei driver CUDA. Hai bisogno di piattaforme che offrano efficienza "Time-to-GPU", motori di inference moderni e integrazioni Kubernetes.
L'Ascesa di vLLM e SafeTensors Per l'inference in produzione, lo standard industriale è ora vLLM, che utilizza PagedAttention e il batching continuo per aumentare il throughput di 8-24 volte rispetto al serving tradizionale. I provider devono supportare ambienti Docker capaci di eseguire vLLM con SafeTensors (che previene l'esecuzione di codice malevolo durante il caricamento del modello).
Tabella 4: Funzionalità di Deployment e Template
| Provider | Configurazione Ambiente e Template | Funzionalità di Orchestrazione AI |
|---|---|---|
| Lambda Labs | Lambda Stack: Pre-installa PyTorch, TensorFlow e CUDA. Pura semplicità "SSH-and-go". | VM semplici. Nessun overhead Kubernetes integrato. |
| RunPod | RunPod Hub / Pods: Vasta libreria di template (vLLM, Stable Diffusion, LLaMA). Docker con 1 clic. | Endpoint Serverless scalano a 0. Generazione API nativa. |
| CoreWeave | Avanzato. Richiede build di container personalizzate per il loro ambiente. | Mission Control: Kubernetes completamente gestito, RL Serverless e InfiniBand. |
| DigitalOcean | Modelli 1-Click: Implementa Llama 3.1 tramite Hugging Face istantaneamente. | DOKS (Kubernetes) supporta nodi GPU senza problemi. |
| Paperspace | Gradient IDE: Notebook ML preconfigurati e pronti all'uso. | Eccellente per l'esplorazione di data science; limiti sui livelli budget. |
Parte 5: Sicurezza, Conformità e Sovranità dei Dati
I modelli AI stanno acquisendo dati aziendali proprietari, registri finanziari e informazioni sanitarie dei pazienti (PHI). Operare un LLM su un cloud non certificato è una responsabilità enorme. Lo standard aureo del 2026 richiede un framework di controllo unificato che copra la conformità SOC 2 Tipo II e HIPAA.
Tabella 5: Posizione di Sicurezza e Conformità
| Provider | Modello di Isolamento | SOC 2 / HIPAA / GDPR | Note di Sicurezza |
|---|---|---|---|
| AWS / Azure / GCP | Hypervisor (VM) | Pienamente Conforme | IAM, KMS e isolamento VPC di livello enterprise. |
| CoreWeave | Kubernetes / Container | SOC 2 (Metà 2026) / HIPAA | Accesso bare-metal disponibile; accordi BAA supportati; partnership con CrowdStrike. |
| RunPod | Container | SOC 2 / HIPAA / GDPR | Secure Cloud opera in datacenter Tier 3/4 con crittografia AES-256. Controllo degli accessi basato sui ruoli (RBAC). |
| Vast.ai | Docker / P2P | Nessuno | Host di terze parti. Non utilizzare per dati sensibili o proprietari |
| GPU Mart | Fisico Dedicato | DC USA certificato SOC | L'isolamento hardware fisico previene lo "snooping" della VRAM e i "noisy neighbors". |
| Akamai (Linode) | Hypervisor (VM) | Pienamente Conforme | Cilium CNI su Kubernetes Enterprise fornisce un isolamento di rete profondo. |
Se operi nel settore sanitario o finanziario, il Secure Cloud di RunPod o CoreWeave offrono la migliore combinazione di accesso GPU specializzato e rigorosa conformità HIPAA/SOC 2 senza duplicare gli sforzi. Evita a tutti i costi i cloud comunitari e i marketplace P2P per i dati sensibili.
Parte 6: Assistenza Clienti — Quando le GPU Prendono Fuoco
Se un lavoro di training multi-nodo si blocca al dodicesimo giorno, chi chiami? Il supporto clienti nello spazio del cloud GPU varia da ingegneri dedicati al silenzio assoluto.
Tabella 6: La Realtà del Supporto Clienti
| Provider | Modello di Supporto | La Realtà |
|---|---|---|
| GPU Mart | Umano 24/7 Gratuito | Insuperabile. Tempi di risposta inferiori a 5 minuti da ingegneri reali. |
| Lambda Labs | Ingegneri AI | Costruito da ricercatori. Il supporto comprende a fondo i problemi CUDA/NCCL, ma le risposte sono strettamente negli orari lavorativi. |
| Hyperscaler (AWS/Azure) | A Livelli / A Pagamento | Robusto, ma il supporto altamente reattivo è bloccato dietro enormi paywall enterprise. |
| RunPod | Ticketing / Discord | Buona documentazione, ma si basa pesantemente su ticketing e un Discord della community. |
| Vast.ai | Community | Sei completamente da solo. Tempi di risposta via email di 1-3 giorni. |
Verdetto Finale: Scegliere il Tuo Cloud AI
Non esiste un unico provider "migliore" nel 2026, ma solo il provider giusto per la tua specifica fase del ciclo di vita dell'AI.
Per il Ricercatore e Sperimentatore AI: Se hai bisogno di testare rapidamente uno script o eseguire un hyperparameter sweep con un budget limitato, Vast.ai e RunPod (Community) offrono capacità di calcolo "usa e getta" a prezzi imbattibili.**Per la Startup Depl











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!