Nvidia estende l'AI ai dispositivi client con DGX Spark
A Computex 2026, Nvidia ha sollevato il velo sulla sua ambiziosa roadmap DGX Spark, una serie di soluzioni progettate per portare la potenza di calcolo dell'intelligenza artificiale direttamente su laptop e PC desktop. Questa mossa strategica segna un'espansione significativa dell'ecosistema Nvidia, tradizionalmente focalizzato sui data center e sulle workstation di fascia alta, verso un segmento di mercato più ampio e distribuito.
L'annuncio sottolinea la crescente importanza dell'AI locale e dell'edge computing. Per CTO, DevOps lead e architetti infrastrutturali, la possibilità di eseguire carichi di lavoro AI complessi direttamente sui dispositivi client apre nuove prospettive in termini di sovranità dei dati, riduzione della latenza e ottimizzazione dei costi operativi per scenari specifici.
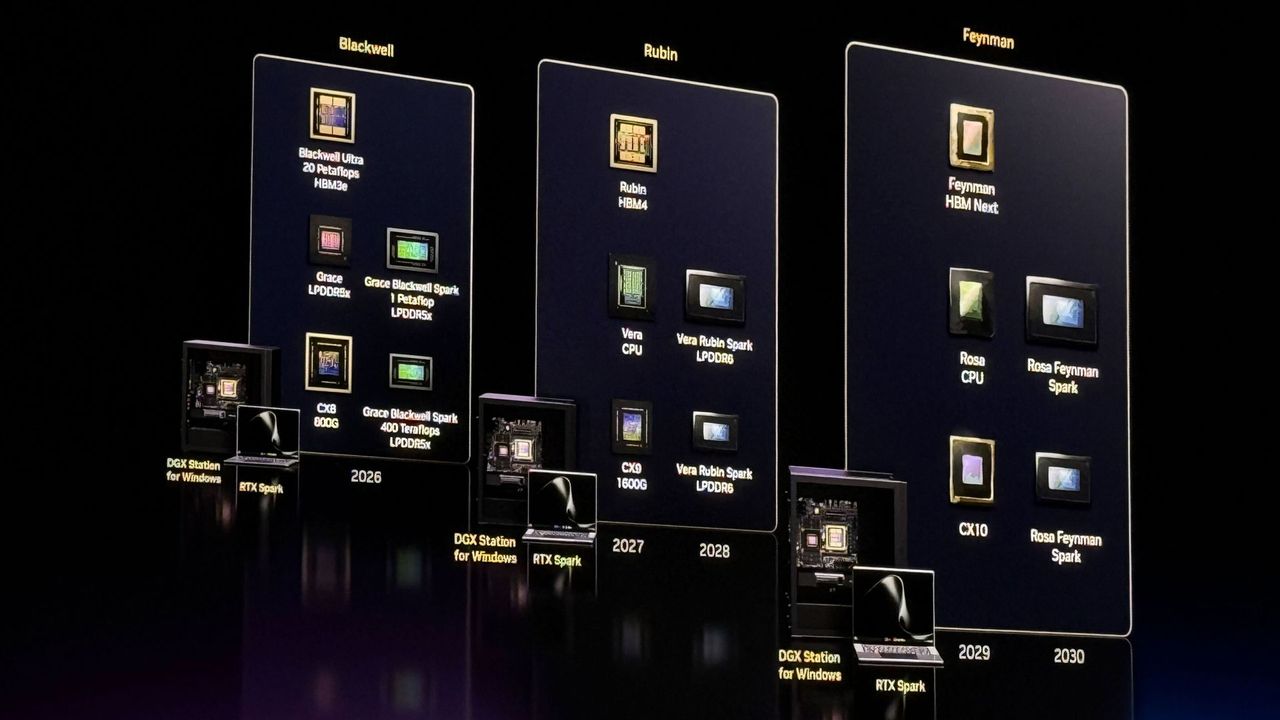
Le future generazioni: Rubin con LPDDR6 e Rosa Feynman
La roadmap DGX Spark delinea lo sviluppo di tre generazioni di piattaforme. Tra queste, Nvidia ha già rivelato i nomi di due architetture chiave: Rubin e Rosa Feynman. La piattaforma Rubin, in particolare, è destinata a integrare memoria LPDDR6, un dettaglio tecnico significativo che evidenzia l'attenzione verso l'efficienza energetica e la compattezza, fattori cruciali per dispositivi come laptop e PC desktop.
La memoria LPDDR6 (Low Power Double Data Rate 6) è progettata per offrire elevate prestazioni con un consumo energetico ridotto, rendendola ideale per l'integrazione in form factor più piccoli senza compromettere la capacità di elaborazione necessaria per i carichi di lavoro AI moderni. Rosa Feynman, la generazione successiva a Rubin, promette ulteriori avanzamenti, sebbene i dettagli specifici non siano ancora stati divulgati. La roadmap include anche la linea RTX Spark, suggerendo una sinergia tra le soluzioni DGX Spark e le GPU consumer RTX di Nvidia.
Implicazioni per il deployment on-premise e l'edge computing
L'iniziativa DGX Spark di Nvidia ha profonde implicazioni per le strategie di deployment dell'AI, in particolare per chi valuta alternative self-hosted o scenari di edge computing. Portare capacità di calcolo AI avanzate su dispositivi client significa poter elaborare dati sensibili localmente, rispondendo a stringenti requisiti di compliance e sovranità dei dati, come il GDPR. Questo approccio riduce la dipendenza dal cloud per l'inference di modelli, minimizzando i rischi legati al trasferimento e alla conservazione dei dati esterni.
Inoltre, l'esecuzione di LLM e altri modelli AI direttamente su laptop e PC desktop può migliorare drasticamente la latenza per applicazioni in tempo reale, come assistenti virtuali avanzati o sistemi di analisi video locali. Sebbene il TCO per l'hardware iniziale possa essere un fattore, la riduzione dei costi operativi legati al traffico di rete e ai servizi cloud a lungo termine può rendere queste soluzioni competitive per determinate applicazioni. Per chi valuta deployment on-premise, AI-RADAR offre framework analitici su /llm-onpremise per valutare i trade-off tra soluzioni cloud e locali.
Prospettive future per l'ecosistema AI distribuito
L'introduzione della roadmap DGX Spark da parte di Nvidia è un chiaro segnale della direzione che sta prendendo l'industria dell'AI: una maggiore distribuzione della potenza di calcolo. Questo sviluppo apre la strada a un'ampia gamma di nuove applicazioni e scenari, dai professionisti che necessitano di workstation AI portatili, alle aziende che implementano soluzioni di AI per l'edge in ambienti industriali o retail.
Per i decision-maker tecnici, è fondamentale considerare come queste nuove piattaforme si inseriranno nell'infrastruttura esistente e quali ottimizzazioni software saranno necessarie per sfruttarne appieno il potenziale. L'evoluzione dell'hardware client con capacità AI dedicate stimolerà lo sviluppo di LLM sempre più efficienti e ottimizzati per l'inference locale, contribuendo a un ecosistema AI più resiliente e versatile.











💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!