Nvidia Extends AI to Client Devices with DGX Spark
At Computex 2026, Nvidia lifted the veil on its ambitious DGX Spark roadmap, a series of solutions designed to bring AI computing power directly to laptops and desktop PCs. This strategic move marks a significant expansion of Nvidia's ecosystem, traditionally focused on data centers and high-end workstations, towards a broader, distributed market segment.
The announcement underscores the growing importance of local AI and edge computing. For CTOs, DevOps leads, and infrastructure architects, the ability to run complex AI workloads directly on client devices opens new possibilities in terms of data sovereignty, reduced latency, and optimized operational costs for specific scenarios.
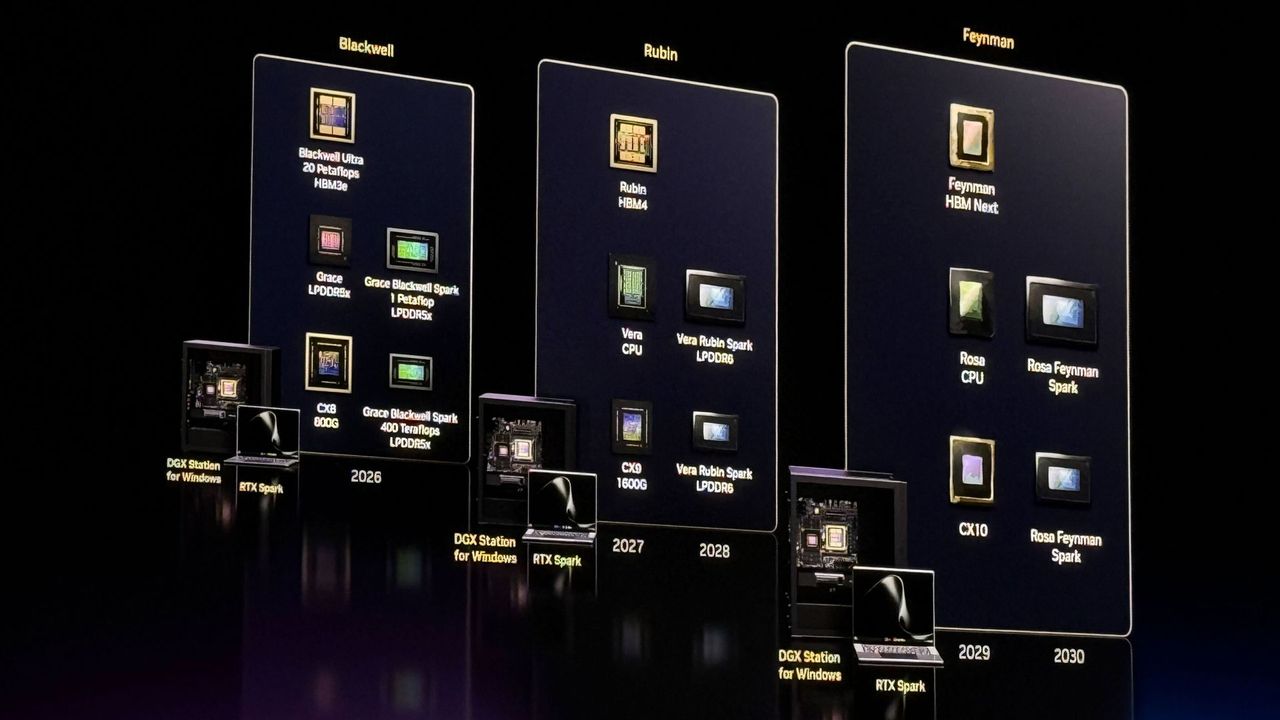
Future Generations: Rubin with LPDDR6 and Rosa Feynman
The DGX Spark roadmap outlines the development of three generations of platforms. Among these, Nvidia has already revealed the names of two key architectures: Rubin and Rosa Feynman. The Rubin platform, in particular, is set to integrate LPDDR6 memory, a significant technical detail that highlights the focus on energy efficiency and compactness, crucial factors for devices like laptops and desktop PCs.
LPDDR6 (Low Power Double Data Rate 6) memory is designed to offer high performance with reduced power consumption, making it ideal for integration into smaller form factors without compromising the processing capability required for modern AI workloads. Rosa Feynman, the generation following Rubin, promises further advancements, although specific details have not yet been disclosed. The roadmap also includes the RTX Spark line, suggesting a synergy between DGX Spark solutions and Nvidia's consumer RTX GPUs.
Implications for On-Premise Deployment and Edge Computing
Nvidia's DGX Spark initiative has profound implications for AI deployment strategies, particularly for those evaluating self-hosted alternatives or edge computing scenarios. Bringing advanced AI computing capabilities to client devices means being able to process sensitive data locally, meeting stringent compliance and data sovereignty requirements, such as GDPR. This approach reduces reliance on the cloud for model inference, minimizing risks associated with external data transfer and storage.
Furthermore, running LLMs and other AI models directly on laptops and desktop PCs can dramatically improve latency for real-time applications, such as advanced virtual assistants or local video analysis systems. While the TCO for initial hardware might be a factor, the reduction in operational costs related to network traffic and long-term cloud services can make these solutions competitive for certain applications. For those evaluating on-premise deployments, AI-RADAR offers analytical frameworks on /llm-onpremise to assess the trade-offs between cloud and local solutions.
Future Prospects for the Distributed AI Ecosystem
Nvidia's introduction of the DGX Spark roadmap is a clear signal of the direction the AI industry is taking: greater distribution of computing power. This development paves the way for a wide range of new applications and scenarios, from professionals needing portable AI workstations to companies implementing edge AI solutions in industrial or retail environments.
For technical decision-makers, it is crucial to consider how these new platforms will integrate into existing infrastructure and what software optimizations will be necessary to fully leverage their potential. The evolution of client hardware with dedicated AI capabilities will stimulate the development of increasingly efficient LLMs optimized for local inference, contributing to a more resilient and versatile AI ecosystem.











💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!