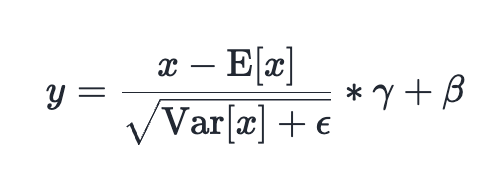
Introduction: Normalization Efficiency for On-Premise LLMs
Normalization methods, such as LayerNorm and RMSNorm, are fundamental pillars in deep learning, essential for stabilizing the model training process and ensuring smoother convergence. Their efficiency is particularly critical in on-premise deployment contexts, where every GPU clock cycle and every byte of VRAM memory count towards optimizing the Total Cost of Ownership (TCO) and maximizing throughput. In this scenario, optimizing low-level operations can significantly impact the overall performance of Large Language Models (LLMs).
This article explores how the PyTorch development team has improved torch.compile performance for LayerNorm and RMSNorm operations on NVIDIA H100 and B200 hardware. The goal was to achieve near state-of-the-art (SOTA) performance at the kernel level, also leveraging the compiler's automatic fusion capabilities. Such advancements are vital for CTOs and infrastructure architects seeking to maximize the efficiency of their self-hosted AI stacks.
Technical Details: Compiler Optimizations and New Strategies
LayerNorm, introduced in 2016, normalizes inputs by calculating mean and variance, then scaling them with learnable parameters (gamma and beta). RMSNorm, an evolution from 2019, uses the root mean square (RMS) for normalization, eliminating the bias term and often proving more efficient. For this study, LayerNorm and RMSNorm benchmark results were presented interchangeably given the similarity of the kernels.
Initially, torch.compile showed lower performance compared to Quack, a library of hyper-optimized CuteDSL kernels from Tri Dao, which served as the SOTA baseline. Initial benchmarks indicated that torch.compile typically achieved about 50% of Quack's performance. However, through careful autotuning and optimization of Inductor's default settings, PyTorch's compiler, this gap was closed. Key modifications included calibrating parameters like R_BLOCK for inner reductions, XBLOCK for persistent reductions, and reducing the number of num_warps to maximize vectorization and saturate memory bandwidth, a crucial aspect for the B200's Blackwell architecture.
Backward Pass Innovation: MixOrderReduction and Pipelining
The backward pass for normalizations is inherently more complex, requiring the calculation of gradients for the input (dX) and for the weights (dW, dB). A naive approach that performs these reductions in separate kernels leads to reading the same inputs twice, doubling the bytes transferred and significantly increasing latency, especially for memory-bound workloads. To address this challenge, torch.compile introduced the MixOrderReduction strategy, which combines INNER (for dX) and OUTER (for dW, dB) reductions into a single fused kernel.
This technique, inspired by solutions like Meta's Liger and Quack's fused CuteDSL kernels, allows for simultaneous gradient processing, drastically reducing memory traffic. A critical aspect of MixOrderReduction is the autotuning of the SPLIT_SIZE parameter, which can influence performance by more than 2x. For instance, a 32x reduction in SPLIT_SIZE led to an improvement from 0.417 TB/s to 1.912 TB/s on H100 for the RMSNorm backward pass with bfloat16. Furthermore, the introduction of software pipelining (prefetching loads) as an autotuning parameter generated speedups of up to 20% for some configurations, especially for inputs with large M and small N dimensions.
Results and Implications for AI Infrastructure
Benchmarks conducted on a 750W B200 machine with CUDA 12.9 (late 2025) demonstrated the effectiveness of these optimizations. For the RMSNorm backward pass, torch.compile with MixOrderReduction achieved a speed 17.07x faster than PyTorch's eager execution, and almost double that of the previous torch.compile version without MixOrderReduction (9.93x). Even more significantly, it surpassed Liger by 1.45x and Quack by 1.34x. Similar results were observed for LayerNorm, confirming a significant approach to peak memory bandwidth.
These advancements are of fundamental importance for organizations deploying LLMs and other deep learning models on on-premise infrastructures. Kernel-level efficiency directly translates into higher throughput, lower latency, and optimized TCO for dedicated hardware. torch.compile's ability to generate optimized kernels and perform automatic fusions with surrounding operations offers a competitive advantage over hand-authored kernels, ensuring superior end-to-end performance. For those evaluating on-premise deployments, these improvements underscore the importance of frameworks that maximize hardware resource utilization, contributing to data sovereignty and complete control over the execution environment.











💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!