L'Apprendimento Continuo per gli Agenti AI: Oltre i Pesi del Modello
Quando si discute di apprendimento continuo nell'ambito dell'intelligenza artificiale, l'attenzione si concentra spesso sull'aggiornamento dei pesi dei modelli. Tuttavia, per gli agenti AI, il processo di apprendimento può manifestarsi su tre livelli distinti e interconnessi: il modello stesso, la sua 'harness' (o struttura di controllo) e il contesto operativo. Comprendere questa distinzione è fondamentale per chi progetta sistemi capaci di evolvere e migliorare autonomamente nel tempo.
Questo approccio multistrato offre una visione più completa di come gli agenti AI possono acquisire nuove capacità e adattarsi a scenari mutevoli, superando i limiti di un'ottimizzazione focalizzata esclusivamente sul cuore algoritmico. Per i CTO e gli architetti di infrastrutture, questa prospettiva è cruciale per la progettazione di deployment robusti e flessibili, specialmente in contesti che richiedono elevata personalizzazione e sovranità dei dati.
Le Tre Dimensioni dell'Apprendimento Continuo
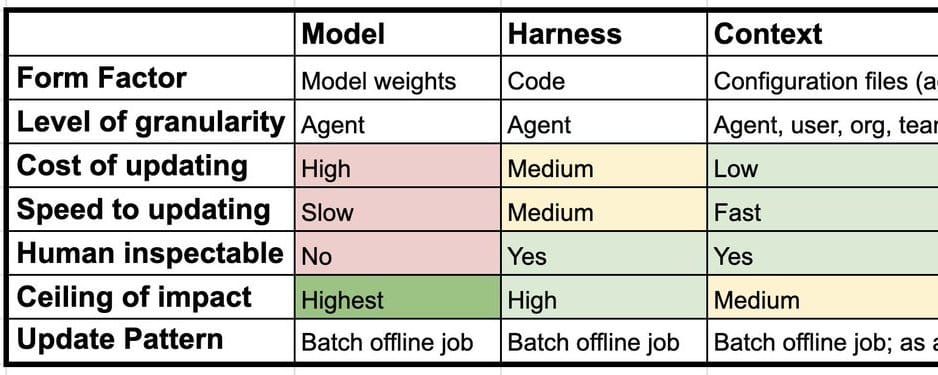
Il primo livello, quello del modello, è il più intuitivo: si riferisce all'aggiornamento dei pesi del Large Language Model (LLM) sottostante. Tecniche come il Supervised Fine-tuning (SFT) o l'apprendimento per rinforzo (RL), ad esempio tramite GRPO, sono impiegate per affinare le capacità del modello. La sfida principale in questo ambito è il cosiddetto 'catastrophic forgetting', ovvero la tendenza del modello a degradare le conoscenze acquisite precedentemente quando viene addestrato su nuovi dati o compiti. Sebbene sia teoricamente possibile applicare il Fine-tuning a un livello granulare, come un LoRA per utente, nella pratica questo tipo di apprendimento è solitamente gestito a livello dell'intero agente.
Il secondo livello è la 'harness', che rappresenta il codice, le istruzioni e gli strumenti che costituiscono l'infrastruttura permanente dell'agente. Questa 'harness' è il motore che guida tutte le istanze dell'agente. L'ottimizzazione di questo strato è oggetto di ricerca, come dimostrato dal paper 'Meta-Harness: End-to-End Optimization of Model Harnesses'. L'idea centrale è che l'agente esegue una serie di compiti, i cui log vengono memorizzati. Un agente di codifica può poi analizzare queste 'traces' per suggerire modifiche al codice della 'harness', migliorandone le prestazioni. Anche in questo caso, l'apprendimento è tipicamente a livello di agente, sebbene si possa immaginare un'ottimizzazione per utente.
Infine, il contesto costituisce il terzo livello. Si tratta di istruzioni aggiuntive, skill o strumenti che risiedono al di fuori della 'harness' e che possono essere utilizzati per configurarla. Spesso ci si riferisce a questo come alla 'memoria' dell'agente. L'apprendimento del contesto può avvenire a livello di singolo agente, come nel caso di OpenClaw con il suo SOUL.md che si aggiorna nel tempo, o a livello di 'tenant' (utente, organizzazione, team), con soluzioni come Hex's Context Studio o Decagon's Duet. Gli aggiornamenti possono essere eseguiti offline, in un processo che OpenClaw chiama 'dreaming', o in tempo reale, mentre l'agente è attivo sul compito principale. Questa flessibilità permette di adattare l'agente in modo dinamico alle esigenze specifiche dell'utente o dell'organizzazione.
Tracce di Esecuzione e Implicazioni per il Deployment
Il filo conduttore che unisce tutti questi meccanismi di apprendimento è rappresentato dalle 'traces': i percorsi di esecuzione completi di un agente. Piattaforme come LangSmith sono progettate per aiutare a raccogliere queste 'traces', che diventano il dato grezzo per l'ottimizzazione. Se si desidera aggiornare il modello, le 'traces' possono essere utilizzate per il Fine-tuning. Per migliorare la 'harness', strumenti come LangSmith CLI e LangSmith Skills consentono a un agente di codifica di accedere a queste 'traces' e suggerire modifiche al codice. Infine, per l'apprendimento del contesto, la 'harness' dell'agente deve supportare l'integrazione e l'aggiornamento di questa memoria, come dimostrato da Deep Agents con le sue funzionalità di memoria a livello utente e apprendimento in background.
Per le organizzazioni che valutano deployment on-premise o self-hosted, la capacità di controllare e ottimizzare questi tre livelli è di importanza strategica. La gestione delle 'traces' in ambienti locali garantisce la sovranità dei dati e la conformità normativa, aspetti critici per settori regolamentati. La flessibilità di personalizzare la 'harness' e il contesto a livello granulare permette di costruire agenti AI che si adattano perfettamente alle specifiche esigenze aziendali, senza dipendere da configurazioni predefinite di fornitori cloud. AI-RADAR offre framework analitici su /llm-onpremise per valutare i trade-off tra controllo, performance e TCO in questi scenari.
Verso Sistemi AI Adattivi e Controllabili
L'approccio multistrato all'apprendimento continuo per gli agenti AI rappresenta un passo significativo verso la creazione di sistemi più robusti, adattivi e autonomi. Spostando l'attenzione oltre il solo aggiornamento dei pesi del modello, si aprono nuove possibilità per l'ottimizzazione delle prestazioni e la personalizzazione dell'esperienza utente. La capacità di un agente di imparare e migliorare non solo a livello algoritmico, ma anche attraverso la sua logica operativa e il suo contesto di utilizzo, è fondamentale per affrontare la complessità del mondo reale.
Per i decision-maker tecnici, comprendere questi meccanismi significa poter progettare architetture AI che non solo rispondono alle esigenze attuali, ma sono anche in grado di evolvere e adattarsi a quelle future. Questo livello di controllo e adattabilità è particolarmente prezioso in contesti dove la sicurezza, la privacy e l'efficienza operativa sono priorità assolute, rafforzando l'argomento per soluzioni di AI che offrono una gestione granulare dell'intero stack tecnicico.










💬 Commenti (0)
🔒 Accedi o registrati per commentare gli articoli.
Nessun commento ancora. Sii il primo a commentare!