Continual Learning for AI Agents: A Multi-Layered Approach Beyond Model Weights
When discussing continual learning in artificial intelligence, the focus often narrows to updating model weights. However, for AI agents, the learning process can manifest across three distinct and interconnected layers: the model itself, its 'harness' (or control structure), and the operational context. Understanding this distinction is fundamental for those designing systems capable of evolving and improving autonomously over time.
This multi-layered approach offers a more comprehensive view of how AI agents can acquire new capabilities and adapt to changing scenarios, overcoming the limitations of optimization focused solely on the algorithmic core. For CTOs and infrastructure architects, this perspective is crucial for designing robust and flexible deployments, especially in contexts requiring high customization and data sovereignty.
The Three Dimensions of Continual Learning
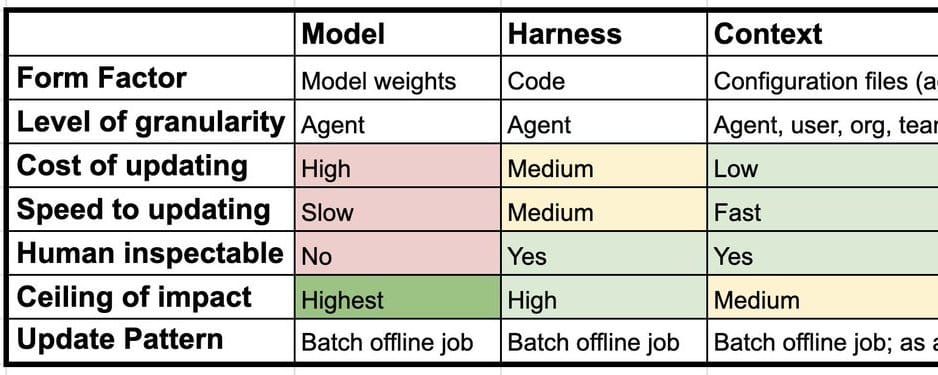
The first layer, the model, is the most intuitive: it refers to updating the weights of the underlying Large Language Model (LLM). Techniques such as Supervised Fine-tuning (SFT) or Reinforcement Learning (RL), for example via GRPO, are employed to refine the model's capabilities. The main challenge here is 'catastrophic forgetting,' the model's tendency to degrade previously acquired knowledge when trained on new data or tasks. While it is theoretically possible to apply Fine-tuning at a granular level, such as a LoRA per user, in practice this type of learning is usually managed at the level of the entire agent.
The second layer is the harness, which represents the code, instructions, and tools that constitute the agent's permanent infrastructure. This harness is the engine that drives all instances of the agent. The optimization of this layer is a subject of research, as demonstrated by the paper 'Meta-Harness: End-to-End Optimization of Model Harnesses.' The core idea is that the agent performs a series of tasks, whose logs are stored. A coding agent can then analyze these 'traces' to suggest changes to the harness code, improving its performance. Here too, learning is typically at the agent level, although optimization per user could be envisioned.
Finally, context constitutes the third layer. These are additional instructions, skills, or tools that reside outside the harness and can be used to configure it. This is often referred to as the agent's 'memory.' Context learning can occur at the individual agent level, as in the case of OpenClaw with its SOUL.md that updates over time, or at the 'tenant' level (user, organization, team), with solutions like Hex's Context Studio or Decagon's Duet. Updates can be performed offline, in a process OpenClaw calls 'dreaming,' or in real-time, while the agent is active on the main task. This flexibility allows the agent to dynamically adapt to the specific needs of the user or organization.
Execution Traces and Deployment Implications
The common thread uniting all these learning mechanisms is 'traces': the complete execution paths of an agent. Platforms like LangSmith are designed to help collect these traces, which become the raw data for optimization. If you want to update the model, traces can be used for Fine-tuning. To improve the harness, tools like LangSmith CLI and LangSmith Skills allow a coding agent to access these traces and suggest code changes. Finally, for context learning, the agent's harness must support the integration and updating of this memory, as demonstrated by Deep Agents with its user-level memory and background learning features.
For organizations evaluating on-premise or self-hosted deployments, the ability to control and optimize these three layers is of strategic importance. Managing traces in local environments ensures data sovereignty and regulatory compliance, critical aspects for regulated sectors. The flexibility to customize the harness and context at a granular level allows for building AI agents that perfectly adapt to specific business needs, without relying on predefined cloud provider configurations. AI-RADAR offers analytical frameworks on /llm-onpremise to evaluate the trade-offs between control, performance, and TCO in these scenarios.
Towards Adaptive and Controllable AI Systems
The multi-layered approach to continual learning for AI agents represents a significant step towards creating more robust, adaptive, and autonomous systems. By shifting the focus beyond just updating model weights, new possibilities open up for performance optimization and user experience personalization. An agent's ability to learn and improve not only at an algorithmic level but also through its operational logic and usage context is fundamental for addressing real-world complexity.
For technical decision-makers, understanding these mechanisms means being able to design AI architectures that not only meet current needs but are also capable of evolving and adapting to future ones. This level of control and adaptability is particularly valuable in contexts where security, privacy, and operational efficiency are absolute priorities, strengthening the argument for AI solutions that offer granular management of the entire technology stack.










💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!