Samsung's Advancement in HBM4 Memory
The generative artificial intelligence landscape is rapidly evolving, and with it, the demand for increasingly high-performance hardware grows. In this context, HBM (High Bandwidth Memory) represents a fundamental pillar for AI accelerators, particularly for GPUs intended for Large Language Model inference and training. Samsung, a leading player in the semiconductor industry, has announced a significant improvement in the production yield of its HBM4 memory.
This progress is of crucial importance for the entire technology supply chain. Higher yield means greater availability of these critical components, which in turn can influence the production of high-end GPUs and, ultimately, the ability of companies to implement robust and scalable AI solutions. HBM4 memory is designed to offer superior bandwidth compared to previous generations, an indispensable requirement for managing the massive datasets and complex models typical of LLMs.
Technical Details and Nvidia's Praise
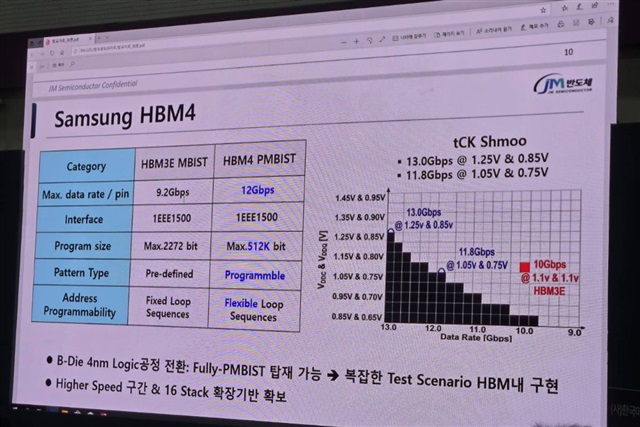
In addition to progress in HBM4 yield, Samsung has introduced an upgrade to its 4-nanometer manufacturing process, which includes PMBIST (Process Monitor Built-In Self Test) technology. This innovation has been welcomed by Nvidia, an undisputed leader in the GPU market for AI. The appreciation from a player like Nvidia underscores the importance of these improvements not only in terms of production volume but also in component quality and reliability.
The 4-nanometer process allows for the integration of a greater number of transistors in a reduced space, improving chip efficiency and performance. PMBIST, on the other hand, is an integrated feature that allows monitoring and testing the manufacturing process directly on the silicio, ensuring greater reliability and reducing defects. For companies evaluating on-premise LLM deployments, hardware stability and longevity are key factors that directly impact TCO and operational continuity.
Implications for On-Premise Deployments and TCO
The optimization of HBM4 production and the reliability of 4-nanometer processes have direct repercussions for AI deployment strategies, especially those prioritizing self-hosted infrastructure. The availability of high-bandwidth memory is a limiting factor for GPU performance, and a supply bottleneck can delay the expansion of AI computing capabilities. An improvement in HBM4 yield can therefore accelerate the availability of next-generation AI accelerators.
For CTOs and infrastructure architects, the choice of on-premise deployment is often driven by the need for data sovereignty, regulatory compliance, and granular control over the environment. In this scenario, hardware reliability and performance are crucial. Improvements in the quality and production yield of components like HBM4 contribute to reducing maintenance costs and optimizing overall TCO, making local deployments more competitive compared to cloud alternatives.
Future Prospects for AI Hardware
The developments announced by Samsung highlight the continuous race for innovation in the AI hardware sector. The demand for computing capacity for LLMs and other artificial intelligence applications shows no signs of slowing down, pushing semiconductor manufacturers to invest heavily in research and development. HBM4 memory, with its promises of higher bandwidth and capacity, will be a distinguishing element of future generations of accelerators.
For companies facing strategic decisions about AI infrastructure, monitoring these advancements is essential. The ability to best leverage new technologies, balancing performance, costs, and security requirements, will determine the success of their AI projects. The commitment of manufacturers like Samsung to improve the quality and availability of critical components like HBM4 is a positive signal for the entire ecosystem, especially for those focusing on robust and controlled solutions in self-hosted environments.










💬 Comments (0)
🔒 Log in or register to comment on articles.
No comments yet. Be the first to comment!